






Abstract
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These highperforming vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption.
In this work, we produce competitive convolutionfree transformers trained on ImageNet only using a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data.
We also introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention, typically from a convnet teacher. The learned transformers are competitive (85.2% top-1 acc.) with the state of the art on ImageNet, and similarly when transferred to other tasks. We will share our code and models.
翻译:
最近,基于注意力机制的神经网络被证明可以解决图像分类等图像理解任务。这些高性能的视觉Transformer使用大规模基础设施对数亿张图像进行了预训练,从而限制了它们的采用。
在这项工作中,我们提出了一种竞争力强的无卷积Transformer,在仅使用一台计算机不到3天的时间内,仅通过ImageNet数据进行了训练。我们的参考视觉Transformer(8600万参数)在ImageNet上的单剪裁准确率达到了83.1%,没有使用外部数据。
我们还引入了一种针对Transformer特定的师生策略。它依赖于一个蒸馏令牌,确保学生通过注意力从教师那里学习,通常是从一个卷积网络教师那里学习。经过学习的Transformer在ImageNet上表现出色(85.2%的单剪裁准确率),与最新技术水平相当,并且在转移到其他任务时也是如此。我们将分享我们的代码和模型。
Introduction
We address another question: how to distill these models? We introduce a token-based strategy, DeiT⚗, that advantageously replaces the usual distillation for transformers.
In summary, our work makes the following contributions:
• We show that our neural networks that contain no convolutional layer can achieve competitive results against the state of the art on ImageNet with no external data.They are learned on a single node with 4 GPUs in three days1 . Our two new models DeiT-S and DeiT-Ti have fewer parameters and can be seen as the counterpart of ResNet-50 and ResNet-18.
• We introduce a new distillation procedure based on a distillation token, which plays the same role as the class token, except that it aims at reproducing the label estimated by the teacher. Both tokens interact in the transformer through attention. This transformer-specific strategy outperforms vanilla distillation by a significant margin.
• Our models pre-learned on Imagenet are competitive when transferred to different downstream tasks such as fine-grained classification, on several popular public benchmarks: CIFAR-10, CIFAR-100, Oxford-102 flowers, Stanford Cars and iNaturalist-18/19.
翻译:
我们解决了另一个问题:如何对这些模型进行蒸馏?我们引入了一种基于令牌的策略,DeiT⚗,有利地替代了传统的Transformer蒸馏方法。
总之,我们的工作具有以下贡献:
• 我们展示了我们的神经网络,不含卷积层,可以在没有外部数据的情况下,在ImageNet上与最先进的技术取得竞争力。它们在一个单节点上,使用4个GPU在三天内学习。我们的两个新模型DeiT-S和DeiT-Ti具有更少的参数,可以看作是ResNet-50和ResNet-18的对应模型。
• 我们引入了一种新的基于蒸馏令牌的蒸馏过程,它与类别令牌类似,但其目标是复现教师估计的标签。这两个令牌通过注意力在Transformer中进行交互。这种特定于Transformer的策略明显优于传统的蒸馏方法。
• 我们在ImageNet上预先训练的模型在转移到不同的下游任务时表现出竞争力,例如细粒度分类,在几个流行的公共基准数据集上:CIFAR-10、CIFAR-100、Oxford-102 flowers、Stanford Cars和iNaturalist-18/19。
Vision transformer: overview
The class token
is a trainable vector, appended to the patch tokens before the first layer, that goes through the transformer layers, and is then projected with a linear layer to predict the class. This class token is inherited from NLP (Devlin et al, 2018), and departs from the typical pooling layers used in computer vision to predict the class.
The transformer thus process batches of (N + 1) tokens of dimension D, of which only the class vector is used to predict the output. This architecture forces the self-attention to spread information between the patch tokens and the class token: at training time the supervision signal comes only from the class embedding, while the patch tokens are the model’s only variable input.
翻译:
是一个可训练的向量,附加到patch令牌之前的第一层,然后通过transformer层,并最终通过线性层进行投影以预测类别。这个class令牌继承自自然语言处理领域(Devlin等人,2018年),与计算机视觉中典型的池化层不同,用于预测类别。
因此,transformer处理的是维度为D的(N+1)个令牌的批次,其中只有class向量用于预测输出。这种架构强制自注意力在patch令牌和class令牌之间传播信息:在训练时,监督信号仅来自class嵌入,而patch令牌是模型的唯一可变输入。
Distillation through attention
Soft distillation
(Hinton et al, 2015; Wei et al, 2020) minimizes the Kullback-Leibler divergence between the softmax of the teacher and the softmax of the student model.
Let Zt be the logits of the teacher model, Zs the logits of the student model. We denote by τ the temperature for the distillation, λ the coefficient balancing the Kullback–Leibler divergence loss (KL) and the cross-entropy (LCE) on ground truth labels y, and ψ the softmax function. The distillation objective is
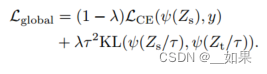
翻译:
(Hinton等人,2015年;韦等人,2020年)最小化了教师模型的 softmax 和学生模型的 softmax 之间的 Kullback-Leibler 散度。
设 Zt 为教师模型的 logits,Zs 为学生模型的 logits。我们用 τ 表示蒸馏的温度,λ 表示平衡 Kullback–Leibler 散度损失(KL)和基于地面真实标签 y 的交叉熵(LCE)的系数,ψ 表示 softmax 函数。蒸馏目标是
Hard-label distillation
We introduce a variant of distillation where we take the hard decision of the teacher as a true label. Let yt = argmaxcZt(c) be the hard decision of the teacher, the objective associated with this hard-label distillation is:
For a given image, the hard label associated with the teacher may change depending on the specific data augmentation.We will see that this choice is better than the traditional one, while being parameter-free and conceptually simpler: The teacher prediction yt plays the same role as the true label y.
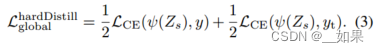
翻译:
我们引入了一种蒸馏的变体,其中我们将教师的硬决策视为真实标签。设 yt = argmaxcZt(c) 为教师的硬决策,与这种硬标签蒸馏相关的目标是:
对于给定的图像,与教师相关的硬标签可能会根据具体的数据增强而变化。我们将看到,这种选择比传统方法更好,同时又是无需参数且概念上更简单的:教师的预测 yt 扮演了与真实标签 y 相同的角色。
总结:
教师的预测和真实标签重要性一样
Label smoothing
Hard labels can also be converted into soft labels with label smoothing (Szegedy et al, 2016), where the true label is considered to have a probability of 1 − ε, and the remaining ε is shared across the remaining classes. We fix ε = 0.1 in our all experiments that use true labels. Note that we do not smooth pseudo-labels provided by the teacher (e.g., in hard distillation).
翻译:
硬标签也可以通过标签平滑(Szegedy等人,2016)转换为软标签,其中真实标签被认为具有概率为1−ε,而剩余的ε被分配给其他类别。在所有使用真实标签的实验中,我们固定 ε = 0.1。请注意,在教师提供的伪标签中(例如,在硬蒸馏中),我们不进行平滑处理。
Distillation token
We now focus on our proposal, which is illustrated in Figure 2. We add a new token, the distillation token, to the initial embeddings (patches and class token).
Our distillation token is used similarly as the class token: it interacts with other embeddings through self-attention, and is output by the network after the last layer. Its target objective is given by the distillation component of the loss.
The distillation embedding allows our model to learn from the output of the teacher, as in a regular distillation, while remaining complementary to the class embedding.
翻译:
我们现在将重点放在我们的提议上,如图2所示。
我们在初始嵌入(patch 和 class 标记)中添加了一个新的标记,即蒸馏标记。
我们的蒸馏标记的使用方式与类标记类似:它通过自注意力与其他嵌入进行交互,并在最后一层之后由网络输出。其目标目标由损失的蒸馏组件确定。
蒸馏嵌入使得我们的模型可以从教师的输出中学习,就像常规的蒸馏一样,同时保持与类嵌入的互补性。
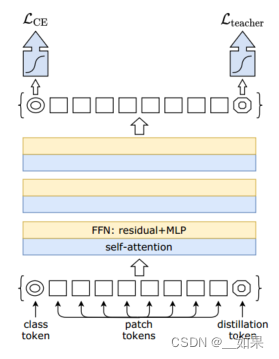
cls token和distill token通过反向传播学得
distill token的目标是重现教师模型的预测,而非真实的标签
Fine-tuning with distillation
We use both the true label and teacher prediction during the fine-tuning stage at higher resolution. We use a teacher with the same target resolution, typically obtained from the lower-resolution teacher by the method of Touvron et al (2019). We have also tested with true labels only but this reduces the benefit of the teacher and leads to a lower performance.
翻译:
在更高分辨率的微调阶段,我们同时使用真实标签和教师预测。我们使用与目标分辨率相同的教师模型,通常是通过Touvron等人(2019年)的方法从低分辨率教师模型获得的。我们也尝试过仅使用真实标签,但这会减少教师模型的好处,并导致性能降低。
Classification with our approach: joint classifiers
At test time, both the class or the distillation embeddings produced by the transformer are associated with linear classifiers and able to infer the image label. Our referent method is the late fusion of these two separate heads, for which we add the softmax output by the two classifiers to make the prediction. We evaluate these three options in Section 5.
翻译:
在测试阶段,由transformer生成的类别或蒸馏嵌入都与线性分类器相关联,并能够推断图像标签。我们的参考方法是这两个单独头部的后期融合,我们将两个分类器的 softmax 输出相加以进行预测。我们在第5节中评估了这三种选项。
Experiments
teacher模型CNN比transformer好,可能是transformer通过蒸馏继承了归纳偏置
在本方法中,硬蒸馏效果比软蒸馏好
Conclusion
We have introduced a data-efficient training procedure for image transformers so that do not require very large amount of data to be trained, thanks to improved training and in particular a novel distillation procedure. Convolutional neural networks have been optimized, both in terms of architecture and optimization, during almost a decade, including through extensive architecture search prone to overfiting.
For DeiT we relied on existing data augmentation and regularization strategies pre-existing for convnets, not introducing any significant architectural change beyond our novel distillation token. Therefore we expect that further research on image transformers will bring further gains.
翻译:
我们引入了一种对ViT进行高效数据训练的过程,不需要大量数据进行训练,这要归功于改进的训练方法,尤其是一种新颖的蒸馏程序。在几乎一个 decade 的时间里,卷积神经网络在体系结构和优化方面都经过了优化,包括通过广泛的架构搜索来抵御过拟合。
对于 DeiT,我们依赖于现有的数据增强和正则化策略,这些策略在卷积网络中已经存在,除了我们的新颖蒸馏令牌之外,没有引入任何重大的架构变化。因此,我们期望对图像变换器的进一步研究将带来更大的收益。















 3307
3307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









