






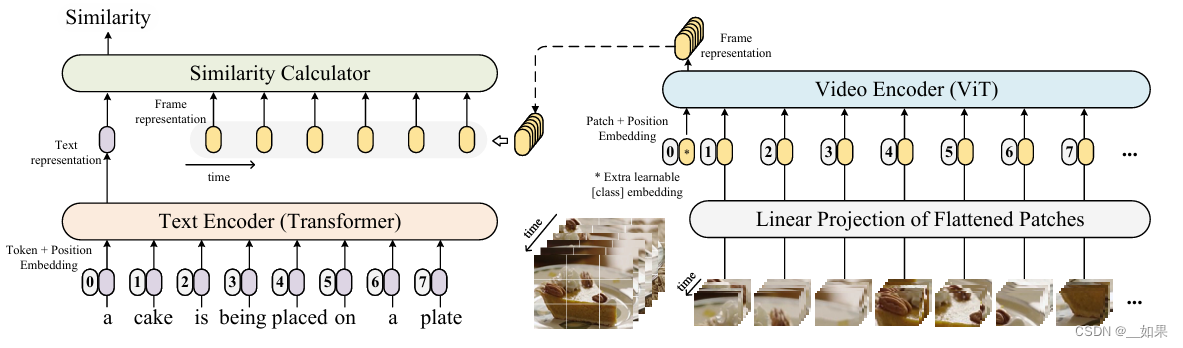
CLIP天生适合做retrieve的任务,拿编码好的特征做相似度计算
CLIP做视频的迁移问题在于,一般视频的处理方式是对多个帧做patch,因此得到的图像特征应该是多个帧的融合特征,但CLIP是一个文本特征对应一个图像特征,这时候该如何进行相似度计算?
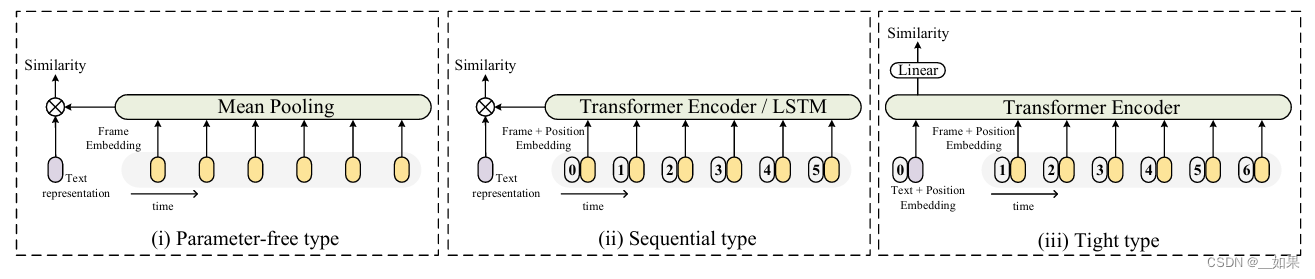
第一种方法:直接取平均。缺点是没有考虑到时序的特性,例如两段视频,一段是人慢慢坐下,一段是人慢慢起身,直接取平均的话这两段视频的语义是一样的
第二章方法:用transformer或LSTM,把时序信息加进去
第三章方法:不在最后融合特征,而是将文本与视频帧丢入同一个transformer,类似于把文本特征当成cls token,最后把融合了视频与文本的特征去做相似度计算
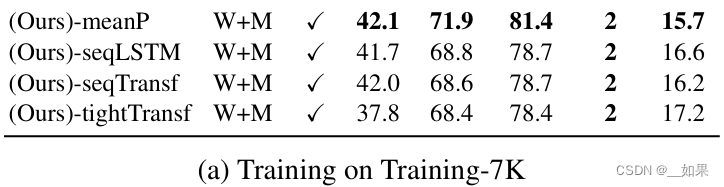
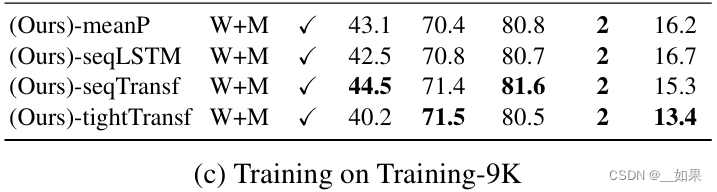
用少量数据集时直接平均的效果最好,只有当数据量上去的时候,后面的方法效果才会提高















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









