







创建进程 —— fork
初识fork
我们平时在创建进程的时候,都是在程序存在的情况下,./程序名称,启动程序的时候就将程序变成了进程。操作系统会将你的可执行程序先加载到内存当中,操作系统会给对应的程序创建PCB。
有没有一种办法能够通过代码来创建进程呢,我们在linux中运用fork系统调用来创建进程。
用途
在已存在的进程中创建一个进程
头文件
#include<unistd.h>
函数返回值以及形参类型
pid_t fork(void) //pid_t是一个整数
fork的返回值有三种
- 在父进程中,fork返回新创建子进程的进程ID
- 在子进程中,fork返回0
- 如果出现错误,fork返回一个负值
在文章的下面将会详细讲解fork的用法和返回值的含义
fork函数用例分析
用例1
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("befor fork: I am a process pid: %d, ppid:%d\n",getpid(),getppid());
fork();
printf("after fork: I am a process pid: %d,ppid: %d\n",getpid(),getppid());
return 0;
}
在这个代码中在fork函数之前,打印了进程的pid和ppid,在fork函数之后又再次打印了进程的pid和ppid,运行结果如下。
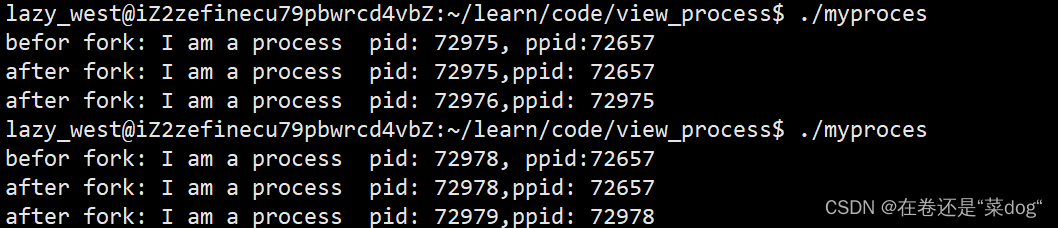
在上述运行结果后我们发现,在fork函数之前只有一个输出结果,在fork函数之后出现了两个输出结果,并且其中一个输出结果与fork之前的输出结果相同,另一个输出的ppid就是fork之前的pid。
由此我们可以猜测,在fork之后的输出一个输出是原本进程(父进程)的pid和ppid,然而另一个是新创建的子进程。
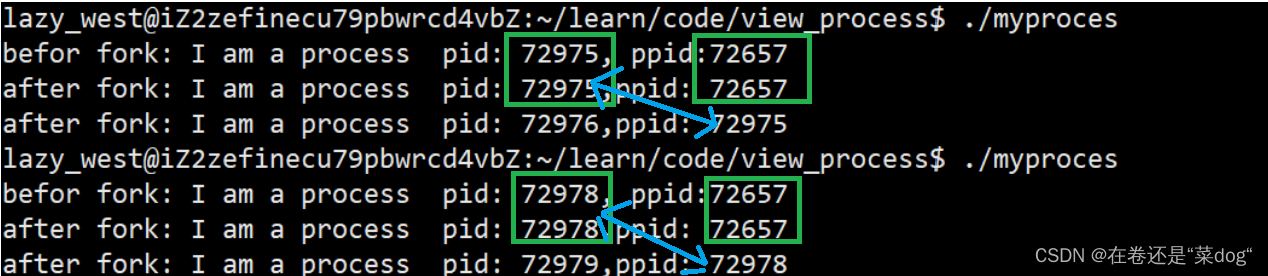
说明fork之后程序将会出现两个执行分支,两个分支都会执行printf所以printf会执行两次。说明fork之后代码共享!!!
那么毫无疑问pid为72657的进程应该为bash(命令行解释器)通过
ps ajx | head -1 && ps ajx | grep 72657
我们可以查询到相关进程信息。

用例2
int main()
{
printf("befor fork: I am a process pid: %d, ppid:%d\n",getpid(),getppid());
pid_t id = fork();
printf("after fork: I am a process pid: %d,ppid: %d,return id: %d\n",getpid(),getppid(),id);
return 0;
}
这个代码用来验证fork函数的返回值,通过运行结果我们可以得知,父进程fork返回值为子进程的pid,子进程的fork返回值为0。

观察fork的返回值我们会存在下面几个疑问
- 为什么给父进程返回子进程的
pid,给子进程返回0 ? - fork函数为什么返回两次
- 同一个变量怎么可能既等于0,又大于0(详细讲解在进程地址空间中讲解)
父进程 : 子进程 = 1 : n,一个子进程想要找到父进程是什么容易得,因为父进程具有唯一性。一个父进程想要找到子进程那么必须使用子进程的标识符!!!所以父进程返回子进程的pid,父进程就可以对子进程进行控制。
在fork之前只有一个进程那么调用fork的一定是父进程。在fork函数的执行中,没有走到return时其实已经创建好了子进程了,又因为我们知道fork之后代码共享,所以父子进程,都会在fork函数中执行return语句返回对应的值。
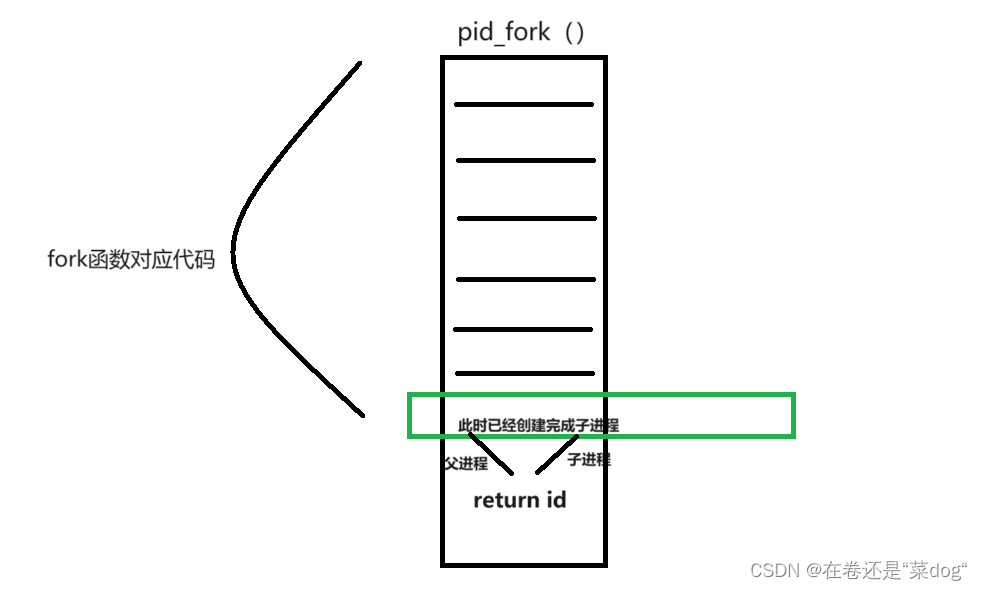
当一个进程崩溃了不会影响其它进程,所以当杀死父进程,子进程不会受到影响,**任意进程之间具有独立性,互相不能影响!!!**当父子进程一方将数据进行修改时操作系统会将数据单独拷贝一份,这就叫做 — 写时拷贝。返回的本质也是拷贝,所以当fork函数执行完,返回时就会发生写时拷贝。
用例3
我们把一个子进程创建出来,我们是为了什么?我们一定是为了让子进程帮助我们完成任务,一般而言我们想让父子进程做不同的事情。
所以我们可以同过父子进程不同的fork返回值,来实现父子进程做不同任务的要求
int main()
{
printf("befor fork: I am a process pid: %d, ppid:%d\n",getpid(),getppid());
sleep(5);
printf("开始创建进程!\n");
pid_t id = fork();
if(id < 0)
{
return 1;
}
else if(id == 0)
{
//子进程
while(1)
{
printf("before fork,我是子进程: I am a process pid: %d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("after fork,我是父进程: I am a process pid: %d, ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
printf("after fork: I am a process pid: %d,ppid: %d,return id: %d\n",getpid(),getppid(),id);
return 0;
}
运行结果
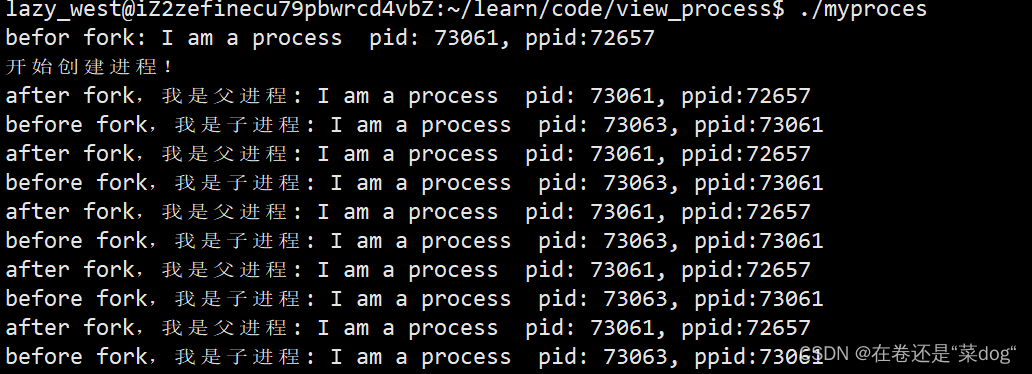
我们发现在fork之后父进程和子进程在while死循环中都在跑,那么为什么在fork之后两个死循环都在执行? fork之后代码共享是怎么共享的?
我们都知道进程 = 内核数据结构 + 可执行程序的代码和数据,当一个程序调用fork函数后,父进程会创建一个新的进程,系统中会多出一个进程!在操作系统层面上,创建了一个子进程那么就要为这个子进程,单独创建一个task_struct,程序运行的时候,进程就会获取程序相应的代码和数据,但是子进程是在运行中被创建的,那么新创建的子进程会和父进程共用同一份代码。
通过fork不同的返回值,来让父子进程执行不同的代码块,但是所有的代码还是父进程的。
在创建子进程时,父进程会将自己的PCB中的大量的属性拷贝给子进程,所以子进程才能看到父进程的数据和代码。
用例4
const int num = 10;
void Worker()
{
int cnt = 12;
while(cnt)
{
printf("child %d is running,cnt:%d\n",getpid(),cnt);
cnt--;
sleep(1);
}
}
int main()
{
for(int i = 0; i < num; i++)
{
pid_t id = fork();
if(id < 0) break;
if(id == 0)
{
//子进程
Worker();
exit(0);//让子进程退出
}
printf("父进程创建子进程成功,子进程pid: %d\n",id);
sleep(1);
}
sleep(14);
return 0;
}
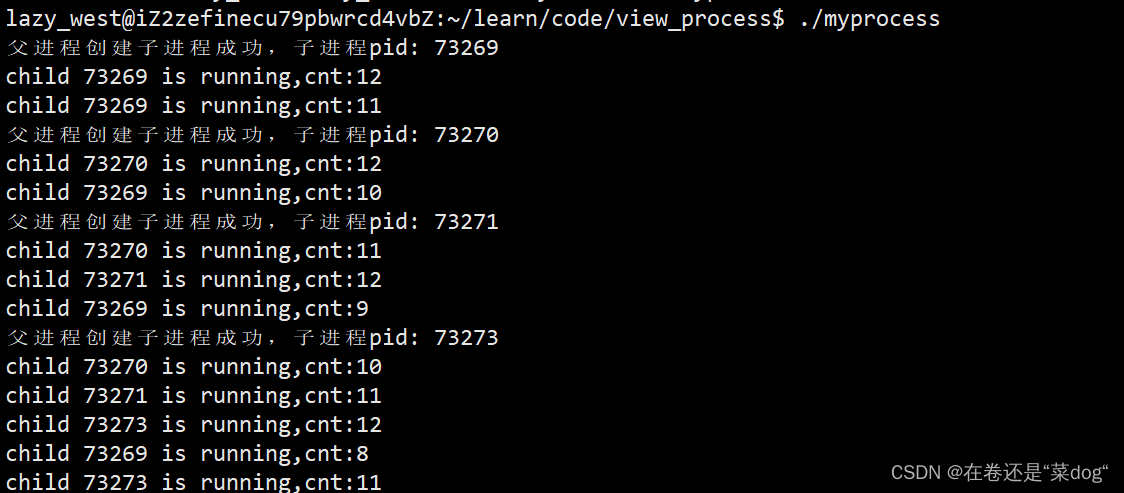
上面代码的目的是让父进程连续创建多个子进程,让每个子进程执行worker函数,执行结束后子进程就退出,循环10次。
运行结果
本专栏为“小菜”linux学习之路
该文章仅供学习参考,如有问题,欢迎在评论区指出。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









