







今天来分享下最近研究的分布式 ID 生成系统 —— Leaf ,一起来思考下这个分布式ID的设计吧 👇
什么是分布式ID?
ID 最大的特点是 唯一
而分布式 ID,就是指分布式系统下的 ID,它是 全局唯一 的。
为啥需要分布式ID呢?
这就和 唯一 息息相关了。
比如我们用 MySQL 存储数据,一开始数据量不大,但是业务经过一段时间的发展,单表数据每日剧增,最终突破 1000w,2000w …… 系统开始变慢了,此时我们已经尝试了优化索引, 读写分离 ,升级硬件,升级网络 等操作,但是 单表瓶颈 还是来了,我们只能去 分库分表 了。
而问题也随着而来了,分库分表后,如果还用 数据库自增ID 的方式的话,那么在用户表中,就会出现 两个不同的用户有相同的ID 的情况,这个是不能接受的。
而 分布式ID全局唯一 的特点,正是我们所需要的。
分布式ID的生成方式
-
UUID
-
数据库自增ID (MySQL,Redis)
-
雪花算法
基本就上面几种了,UUID 的最大缺点就是太长,36个字符长度,而且无序,不适合。
而其他两种的缺点还有办法补救,可能这也是 Leaf 提供这两种生成 ID 方式的原因。
项目简介
Leaf ,分布式 ID 生成系统,有两种生成 ID 的方式:
-
号段模式
-
Snowflake模式

号段模式
在 数据库自增ID 的基础上进行优化
-
增加一个 segement ,减少访问数据库的次数。
-
双 Buffer 优化,提前缓存下一个 Segement,降低网络请求的耗时(降低系统的TP999指标)
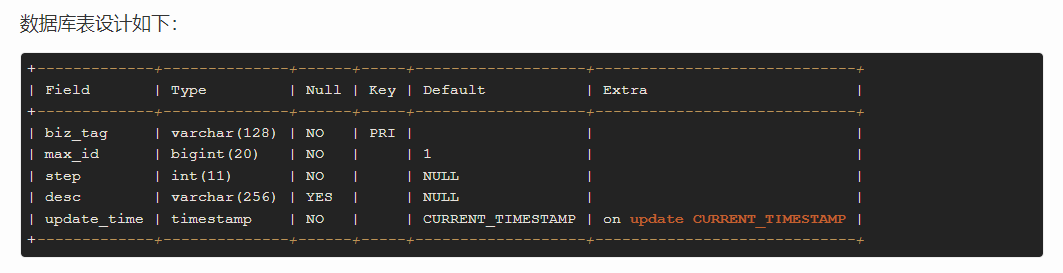
来自美团技术团队
biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度
没优化前,每次都从 db 获取,现在获取的频率和 step 字段相关。

双 Buffer 优化思路 👇

号段模式源码解读

SegmentService 构造方法
作用 👇
-
配置 dataSource
-
设置 MyBatis
-
实例化 SegmentIDGenImpl
-
执行 init 方法

这段代码我也忘了 哈哈,已经多久没直接用 mybatis 了,还是重新去官网翻看的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2739
2739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









