







概述
分布式id生成已经有业界较为成熟的方案。现在公司使用的是美团的Leaf的号码段模式。之所以不用雪花算法模式还是因为雪花算法的自身缺陷,即时间回拨问题。本文就从源码角度剖析leaf项目的两种id生成模式。
Leaf这种分布式id生成系统是美团自研发,具有全局唯一、高可用、高明发、低延迟、接入灵活(支持http、rpc)等优点。
之前我们做全局唯一id的时候使用过雪花算法和UUID.这两者的缺点很明显。
1、雪花算法无法解决始终回拨,当然leaf的雪花算法一定程度上克服了这一个缺点。
2、UUID算法,uuid的值结构不够友好,杂乱无章,对mysql这种需要顺序id的情况不够友好。
tips:Leaf的性能在4C8G的机器上QPS能压测到近5万/s,TP999 1ms
看完本文,您能够收获:
- 代码级别的理解两种生成模式
- 两种模式的优缺点。
主要内容

1、 号段模式
1.1、号码段模式的概念
Leaf项目的号码段模式强依赖DB,在数据库上添加了一个库表。结构如下。
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT 1,
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;基于这个数据库表,我们要在leaf下配置两个参数:
leaf.name=zjtest
leaf.zk.list=172.1X.48.XX号码段的含义大体就是各个服务实例在请求leaf项目的时候leaf会加载一批号码加载到leaf当中。leaf项目维护了以下结构。
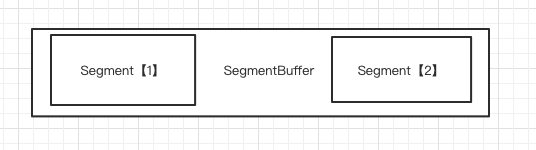
每一个biz_tag都会被包装成SegmentBuffer结构,而每一个SegementBuffer里面包含两个Segment.Segment也叫双Buffer模式。当前使用一个Buffer,如果当前Buffer使用到某个阈值就会开启一个线程,该线程请求数据库请求一批号码段缓存到新的Buffer当中。双Buffer能够解决号码耗尽加载数据库造成业务卡顿的现象。
除了双Buffer优化,号码段模式还对缓存的号码多少做了优化。具体的根据更新时间感知当前leaf服务的请求频繁程度调整每次请求个数。根据上一次的更新周期T和号段长度step来决定这一次更新的号段长度,T<15分钟则step=step*2,15<T<30,step不变,t>30则step=step/2。
1.2代码步骤
1.2.1、初始化阶段
1、获取库表中所有的biz_tag字段集合。
2、将其保存在内存insertTagsSet中。并将tag为key,包装成Segment放入缓存当中。
3、启动定时任务updateCacheFromDb,每隔1分钟执行一次
3.1、获取库表中所有的biz_tag字段集合。
3.2、将其保存在内存insertTagsSet中。并将tag为key,包装成Segment放入缓存当中。
1.2.2、获取号码节点
1、判断初始化是否成功,不成功抛异常。
2、判断缓存是否有该请求key。如果没有该key则抛异常
3、如果有该key则执行以下步骤
初次请求:从库表中缓存号码段缓存
3.1、更新库表该key的maxId,用step值给maxId增加一个step
3.2、将结果返回到内存,更新号码段缓存SegmentBuffer
再次请求:从本地缓存的号码段获取值
3.1、为buffer加读锁。
3.2、根据状态确认是否添加一个线程从db中获取新号段
3.3、释放读锁
3.4、为buffer再加写锁
3.5、获取segment的value字段,并+1,如果小于segment的max字段,则将value作为结果返回。
3.6、释放写锁
在从号码段缓存获取号码的过程中,每次都在判断以下几个状态
1、nextReady=false。如果这样说明本地没有可用号码段
2、segment的剩余号码量是否小于一个step的90%,说明这个剩余号码量不足了
3、获取该SegmentBuffer的threadRunning=false,如果为true说明该号码段有线程已经执行,不能重复启动线程。如果为false说明该SegmentBuffer可以启动一个线程。
如果满足以上三个条件,则启动一个线程。该线程逻辑如下:
1、获取双buffer中没有使用的segment 的下标。
2、更新数据库最大值,让然是当前max+1个step
3、然后将结果犯规给步骤1获得的闲置segment当中。
4、设置buffer的nextReady=true
5、threadRunning=false
1.2.3、优点
- leaf的segment方式可以很方便的进行水平扩展,轻松支撑比较大的业务场景。
- id号码趋势是递增的,对mysql的主键兼容性较好。
- 号段都缓存到了本地一部分,在本地号段消耗完毕之前,如果db挂了还可以继续提供服务。
- 从源码我们看出每一个服务器的初始值都是max_id开始的一段,所以如果迁移老业务,可以方面用该特性调整max_id的值,平滑迁移db行数据。
1.2.4、缺点
- ID 号码不够随机,能够泄露发号数量的信息,不太安全。
- DB 长时间宕机会造成整个系统不可用。
2、SNOWFLAKE 模式
2.1、SNOWFLAKE 模式的概念
leaf中在普通的雪花算法上做了优化,对少量的时钟回拨做了兼容。同时workId字段是通过zk上维护。同时snowFlake模式对wokId缓存到了本地内存,如果zk宕机也会正常使用,对zk形成了弱依赖。
2.2、初始化阶段
1、连接zk
2、获取/forever节点,判断其是否存在
2.1、如果不存在,
2.1.1、创建/forever/ip:port节点,并在其上写入数据(Endpoint对象),包括:ip,port和当前时间撮。
2.1.2、在本地创建文件workerID.properties,并写入数据workerID=0
2.1.3、在线程池(schedule-upload-time)设置一个周期任务,每三秒钟同步时间到2.1创建的节点下。
2.2、如果存在
2.2.1、远程获取zk的目录/forever下所有数据
2.2.2、从zk上获取取出本实例注册的workid,如果存在
则:
1、通过2.2.2获取的workId,更新本地workId信息.
2、检查从zk获取的时间撮是否小于当前时间。
2.1、如果不是,抛异常。服务无法启动
3、启动周期任务,每三秒钟同步时间到zk.
4、将远程获取的workId同步到本地文件workerID.properties中。
2.2.2、从zk上获取取出本实例注册的workid,如果不存在
则
1.创建/forever/ip:port节点到zk,返回/sonwflake/${leaf.name}/snowflake/zjtest/forever/10.8.0.132:2181-0000000000
2、获取远程workId(workId>=0 && workId<=2013)
3、启动周期任务,每三秒钟同步时间到zk.
4、将远程获取的workId同步到本地文件workerID.properties中。
2.3、获取id阶段(初次获取)
1、获取当前时间
2、如果是新开始,从1-100随机获取一个值(例如27)
3、lastTimestamp字段更新为当前时间
4、包装id
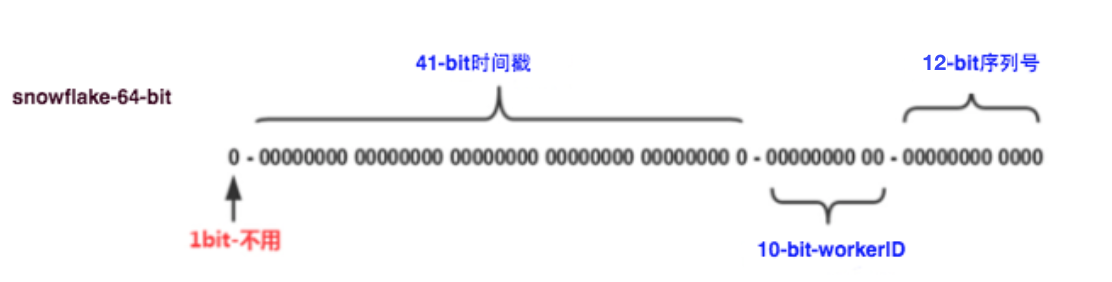
long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence;
举个例子1584855141251547163 (19位)
5、包装成Result返回给业务。
2.4、获取id阶段(并发获取)
1、如果lastTimestamp和当前时间相同,说明发生并发获取
2、并发度为4095,在这个范围内获取上一次sequence,并+1
3、如果获取sequence==0,
3.1、调整sequence为1-100之内随机数
3.2、时间撮调整为lastTimestamp之后的时间。
获取id阶段(时间回拨)
1、比较当前时间和上一次获取时间
2、如果当前时间比上一次获取时间小,并且在5秒范围内
2.1、等待一倍的时间
2.2、如果仍然小于上一次获取时间抛异常
3、如果回拨严重,直接抛异常。 new Result(-3, Status.EXCEPTION);
2.5、特点:
存内存算法
单台机器并发为4096
发生时钟回拨的时候,代码手动调整了时间,如果时间差异小于5秒,则代码自动阻塞了最大10秒的时间。如果回拨严重会给业务直接抛异常。
总结
leaf的两个分布式生成id模式各有自己的优缺点,在选择的时候可以根据实际情况去选择。
segment模式依赖数据库,雪花算法需要引入zk。
segment模式是缓存号码段,号码的顺序性强,雪花算法直接计算号码,号码顺序性不强。
segment模式使用了很多优化手段例如双buffer做预缓存,加载时间调整缓存批次中号码数量;雪花模式在雪花算法的基础上做了兼容少量时间回拨问题。














 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









