






第一章 爬虫基础
1.1.HTTP基本原理
1.URI,URL,URN
URI:统一资源标志符
URL:统一资源定位符
URN:统一资源名称
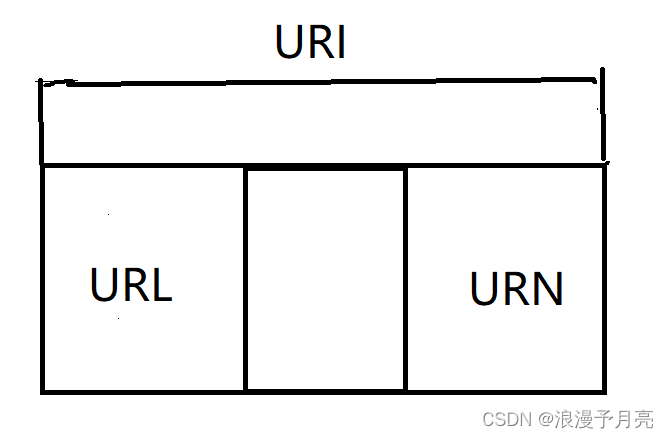
URL是URI的子集,也就是说每一个URL都是URI,但是并非每一个URI都是URL
URL的基本格式规范 scheme://host[:port]/path[?query][#fragment]
基本参数介绍
- scheme:协议,常用的协议具有http,https,ftp等等
- username,password:用户名和密码,一些时候需要提供用户名和密码才能进行访问,我们需要将其放在host前面
- port:端口号。服务器设定的服务端口
- path:路径,网络资源在服务器当中的指定地址
- paeamenters:参数,访问某一个资源时候的附加信息
- query:查询,用来查询某一类资源,如果有多个查询,使用&进行隔开
- fragment:片段,他是对于资源描述的部分补充,具有两个主要的应用,其中一个做页面抽取,一个为HTML锚点
2.HTTP和HTTPS
HTTP:中文名称为超文本传输协议
作用:把超文本数据从网络传输到本地的浏览器,能保证高效和准确的传输超文本协议
HTTPS:简单的说,为HTTP的安全版
安全基础为:SSL
SSL的作用:
- 建立一个信息的安全通道,保证数据传输的有效性
- 确认网站的真实性,凡是使用了HTTPS协议的网站,都可以通过单机浏览器地址栏的锁头标志来查看网站认证之后的真实信息
3.HTTP的请求过程


//可以将其显示未英文的格式
4.请求
请求的组成部分
- 请求方法
- 请求的网址
- 请求头
- 请求体
请求方法
请求方法,用于标识请求客户端请求服务端的方式,常见的请求方法有两种:GET和POST
GET与POST的区别:
- GET请求中的参数包含在URL当中,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体当中
- GET请求提交的数据最多只有1024子节,POST方法则没有限制
请求网址
请求的网址,它可以唯一确定客户端想请求的资源
请求头
- Accept:请求头域,用于指定客户端可接受哪些类型的信息
- Accept-Language:用于指定客户端可接受的语言类型
- Accept-Encoding:用于指定客户端可接受的编码类型
- Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置
- cookie:也常用于复数的形式cookies,这是网站为了辨别用户,进行会话跟踪而存储,主要的功能是维持当前访问会话
- Referer:用于标识请求是从哪一个网页发过来的
- User-Agent:简称UA,这是一种特殊的字符串头,可以使服务器识别客户端使用的操作系统以及版本,浏览器及版本信息
- Content-Type:也叫互联网媒体类型,用来表示具体请求中的媒体类型信息
请求体
请求体,一般承载的内容是POST请求中的表单数据,对于GET请求,请求体为空
5.响应
响应,也就是Response,由服务器返回给客户端,可以划分为三部分,响应状态码,响应头和响应体
响应状态码
| 200 | OK - 请求成功 |
| 301 | Moved Permanently - 永久重定向 |
| 302 | Found - 临时重定向 |
| 400 | Bad Request - 请求错误 |
| 401 | Unauthorized - 未授权 |
| 403 | Forbidden - 禁止访问 |
| 404 | Not Found - 资源未找到 |
| 500 | Internal Server Error - 服务器内部错误 |
| 502 | Bad Gateway - 网关错误 |
| 503 | Service Unavailable - 服务不可用 |
| 504 | Gateway Timeout - 网关超时 |
响应头
响应头,包含了服务器对请求的应答信息
Date:用于标识响应产生的时间
Last_Modified:用于指定资源的最后修改时间
Content-Encoding:用于指定响应内容的编码
Server:包含服务器的信息,例如名称,版本号等
Content-Type:文档类型,指定返回的数据是什么类型
Set-Cookie:设置Cookie
Expires:用于指定响应过期的时间
响应体
需要在网络上爬取出来的数据
1.2.Web网页基础
1.网页的组成
HTML:超文本标记语言
是一种用来描述网页的语言
CSS:层叠样式表,进行网页的美化
javascript:实现一种动态,实时,交互的页面功能
2.节点树以及节点间的关系
- 整个网站文档是一个文档节点
- 每一个HTML标签对应一个根节点
- 节点内的文本是文本节点
- 每一个节点的属性是属性节点
- 注释是注释节点

3.选择器
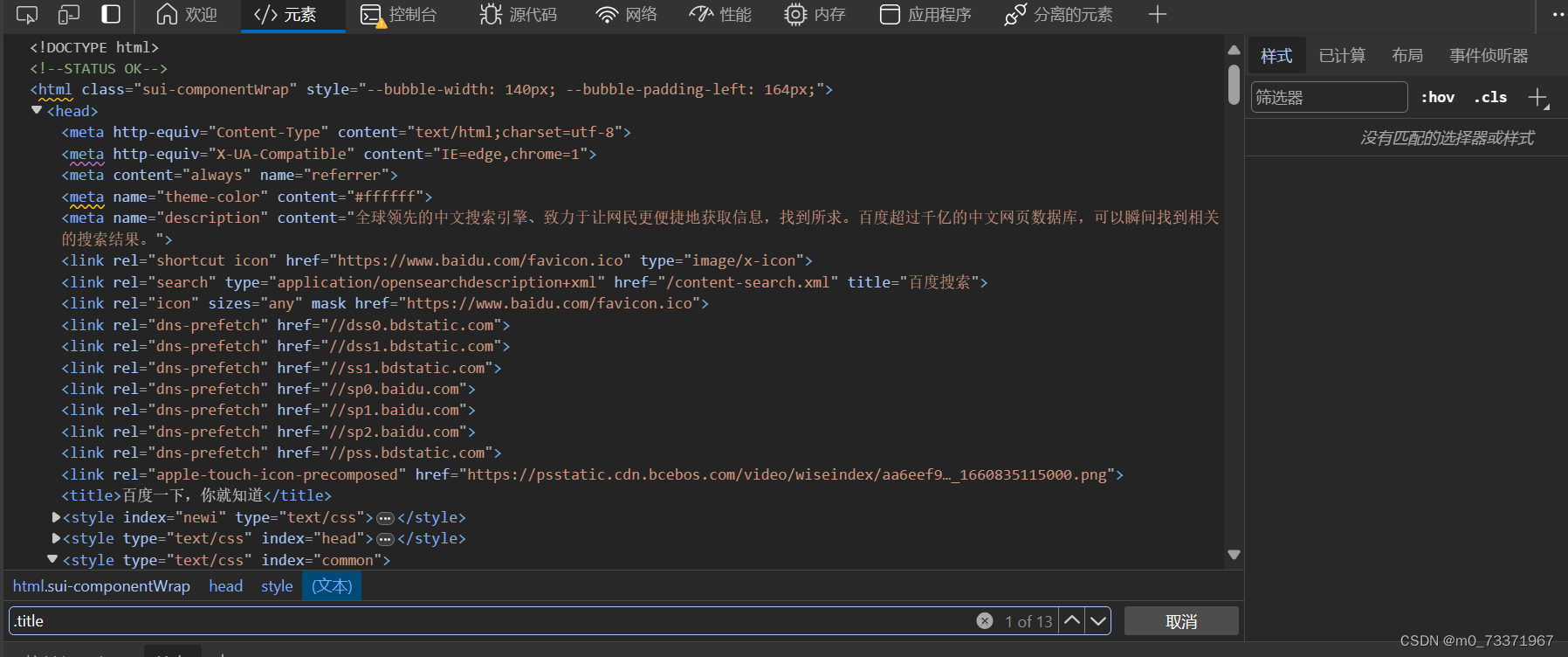
当中的.title,也就是选择了class为title的节点,该节点会在网页中进行高亮的显示
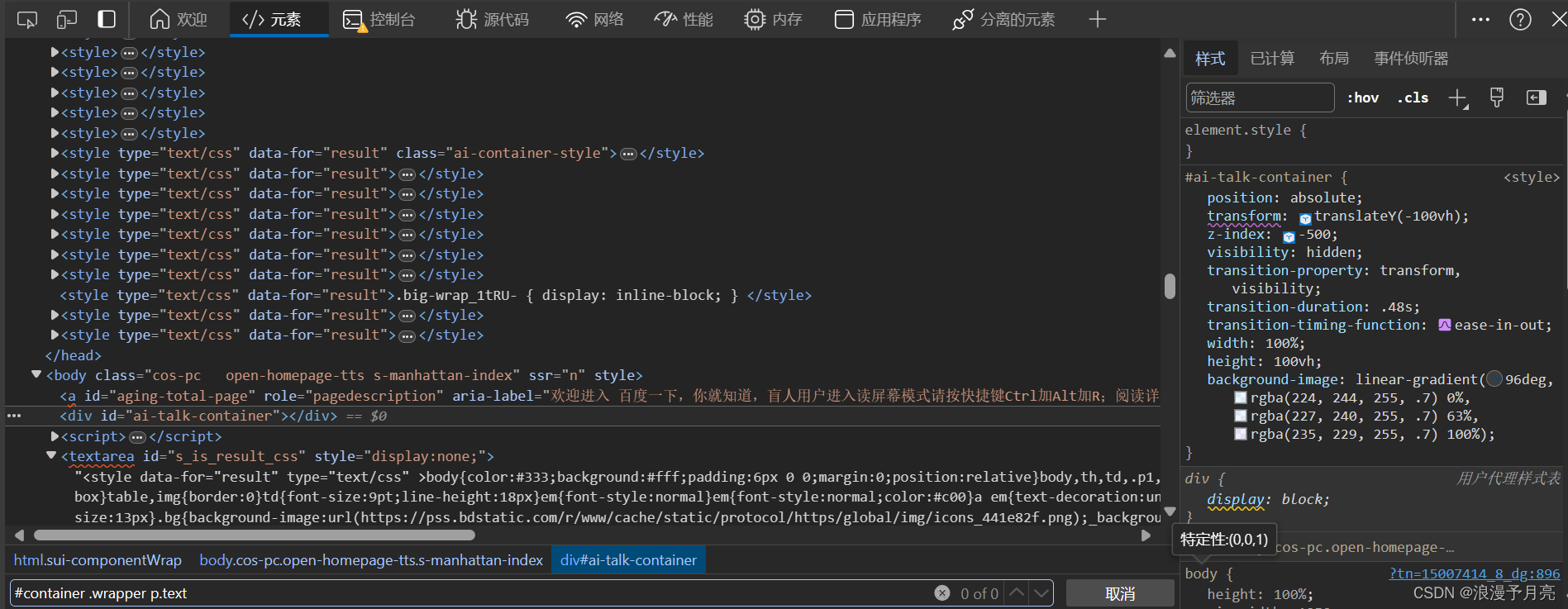
#container .wrapper p.text 也就逐层的选中了ID为container的节点中的class为wrapper的节点中的P节点
| 选择器 | 描述 | 示例 |
| 通用选择器 (*) | 选择所有元素 | * {...} |
| 元素选择器 | 通过标签名选择元素 | p {...} |
| ID选择器 | 通过ID属性选择元素 | #myId {...} |
| 类选择器 | 通过类名选择元素 | .myClass {...} |
| 属性选择器 | 通过属性及其值选择元素 | [attribute="value"] {...} |
| 后代选择器 | 选择指定元素的所有后代元素 | div p {...} |
| 子元素选择器 | 选择指定元素的直接子元素 | ul > li {...} |
| 相邻兄弟选择器 | 选择紧接在另一元素之后的元素 | h2 + p {...} |
| 通用兄弟选择器 | 选择与另一元素相邻的同级元素 | h2 ~ p {...} |
| 伪类选择器 | 根据元素的状态或条件选择元素 | a:hover {...} |
| 伪元素选择器 | 选择元素的特定部分 | p::first-line {...} |
1.3爬虫的基本原理
1.爬虫概述
- 获取网页
- 提取信息
- 保存数据
- 自动化程序
2.能爬怎样的数据
只要是具有对应的URL,URL基于HTTP和HTTPS协议,只要是这种数据,爬虫均可以进行抓取
1.4.Session和Cookie
1.静态网页和动态网页
静态网页:加载速度快,编写简单,但是可维护性差,不能根据URL灵活多变的显示内容
动态网页:可以动态解析URL参数的变化,关联数据库并动态的呈现不同的页面内容,十分的灵活多变
2.无状态HTTP
无状态HTTP:是指HTTP协议对事物处理是没有记忆能力的,或者说服务器并不知道客户端处于什么状态
3.Session
中文当中称为会话,其本义是指有始有终的一些系列动作,消息
4.Cookie
指一些网站为了鉴别出用户身份,使用Session跟踪而存储在用户本地终端上的数据
属性结构
| 属性 | 描述 | 示例 |
| Name | Cookie的名称 | username |
| Value | Cookie的值 | john_doe |
| Domain | 可以访问该Cookie的域名 | .example.com |
| Path | 可以访问该Cookie的路径 | /admin |
| Expires | Cookie的过期时间 | Sat, 31 Dec 2022 23:59:59 GMT |
| Max-Age | Cookie的最大存活时间(以秒为单位) | 3600 |
| Secure | Cookie是否仅通过HTTPS传输 | true |
| HttpOnly | Cookie是否仅限服务器访问,无法通过脚本访问 | true |
| SameSite | 控制跨站点请求时是否发送Cookie | Strict or Lax or None |
1.5爬虫代理
1.代理
代理实际上指的是代理服务器,功能是代网络用户取得网络信息,作为网络信息的中转站
2.代理的作用
- 突破自身ID的访问限制,访问一些之前不能进行访问的节点
- 访问一些单位或团体的内部资源
- 提高访问的速度
- 隐藏真实的IP
3.爬虫代理
使用代理隐藏真实的IP,让服务器误认为代理服务器在请求自己,不断的更换IP,防止被封
4.代理分类
根据协议划分
| HTTP代理 | 通过HTTP协议进行通信的代理服务器,用于转发HTTP请求。可进一步分为普通HTTP代理、HTTPS代理、透明HTTP代理和匿名HTTP代理。 |
| SOCKS代理 | 一种通用的代理协议,支持多种应用层协议(如HTTP、FTP、SMTP等),并且可以进行TCP和UDP的数据转发。可分为SOCKS4、SOCKS4a和SOCKS5。 |
| FTP代理 | 用于转发FTP(文件传输协议)流量的代理服务器。可分为普通FTP代理和透明FTP代理。 |
根据匿名程度划分
| 透明代理 | 完全透明地传递请求,目标服务器能够获取到客户端的真实IP地址。 |
| 匿名代理 | 隐藏了客户端的真实IP地址,但向目标服务器透露了客户端使用了代理。目标服务器无法获取真实IP地址。 |
| 高匿代理 | 完全隐藏了客户端的真实IP地址,向目标服务器透露的是代理服务器的IP地址,目标服务器无法获取真实IP地址。 |
5.常见代理设置
- 网上的免费代理
- 使用付费代理服务
- ADSL拨号
- 蜂窝代理
1.6多线程和多进程的基本原理
1.多线程的含义
进程是线程的几何,进程是由一个或多个线程构成的,线程是操作系统进行运算调度的最小单位,是进程中的最小运行单元,多进程是在一个进程中同时执行多个线程
2.并发和并行
并发:是多个线程对应的多条指令被快速轮换的执行
并行:指同一个时刻有多条指令在多个处理器上面同时执行,意味着并行必须依赖多个处理器
3.多线程使用场景
在程序的进程当中个,一些操作是比较耗费时间或者需要等待的,如果使用多进程,处理器就可以在某一个进程处于等待态的时候,去处理其他的线程,从而提高整体的效率
对于处理计算(cpu)密集型任务,任务的运行一直需要处理器的参与,如果在这种情况,我们开启了多线程,那么处理将不会进行停歇,始终忙于计算,不利于整体的效率
总结:如果任务不全是计算密集型任务,就可以使用多线程来提高程序整体的执行效率,尤其是网络爬虫这种IO密集型任务,使用多线程可以大大的提高程序整体的爬取效率
4.多进程的含义
进程:是具有一定独立功能的程序在某个数据集上面进行的一次运行活动,是系统进行资源分配和调度的一个独立单位















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









