






3.Scrapy框架基本的使用
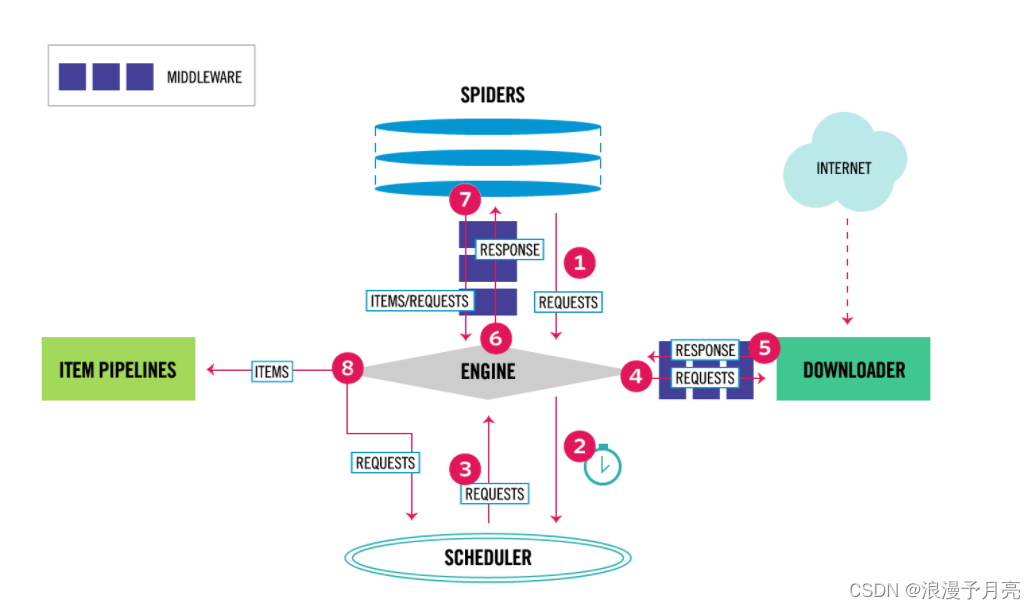
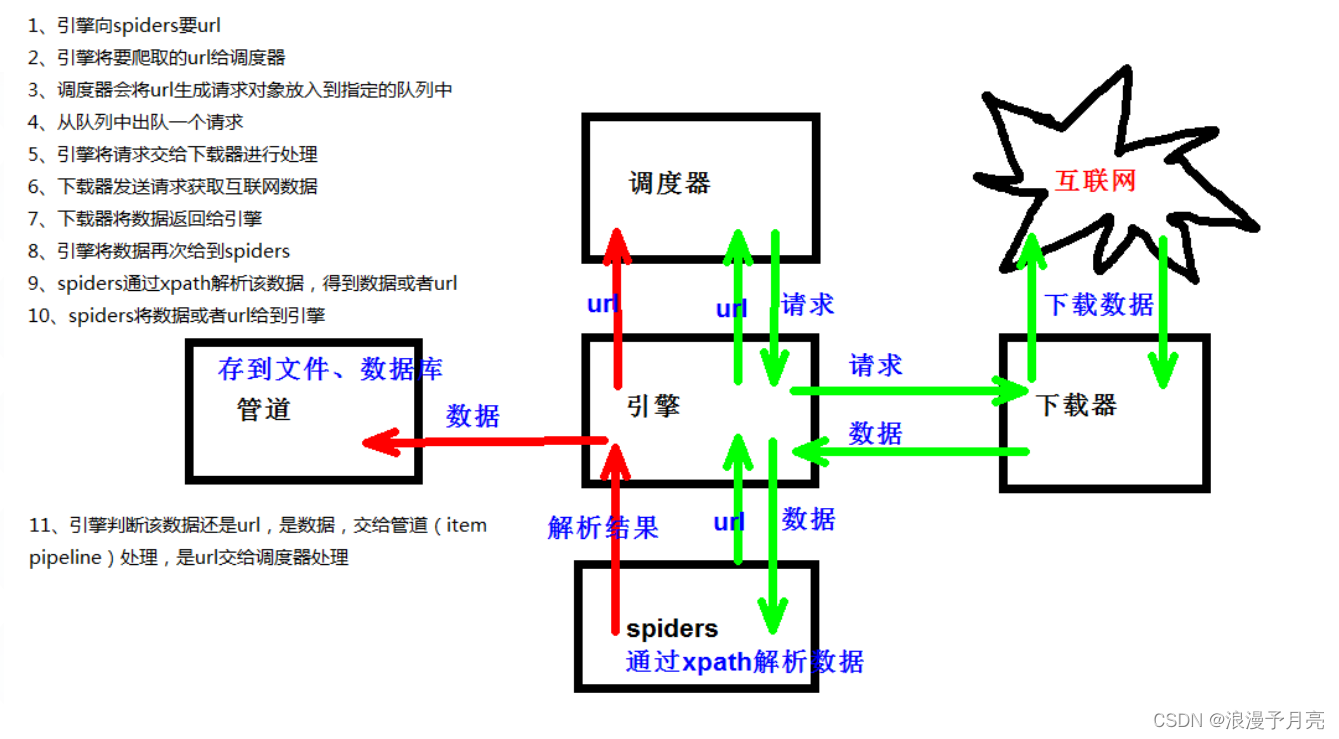
3.1.Scrapy的基本组件和功能
- Engine:引擎,用来处理整个系统的数据流和事件,整个框架的核心,整个框架的中央处理器,负责数据的流转和逻辑的处理
- Item:定义了爬取结果的数据结构,爬取的数据会被初始化为Ttem对象
- Scheduler:调度器,用来接受Engine发送的requests并将其加入队列当中,主要维护requests的逻辑调度
- Spiders:蜘蛛,定义了站点的爬取逻辑和页面的解析规则,主要负责响应并生成Item和新的请求,然后发送给Engine进行处理
- Downloader:下载器
- Ttem Pipelines:项目通道,主要负责由Spider从页面抽取的Item,做一些数据清洗,验证和存储的工作
- Downloader Middlewares:下载器中间键,负责downloader和engine之间的请求和响应过程
3.2 Scrapy入门
Scrapy创建
使用如下的命令进行scrapy项目的创建:scrapy startproject ___
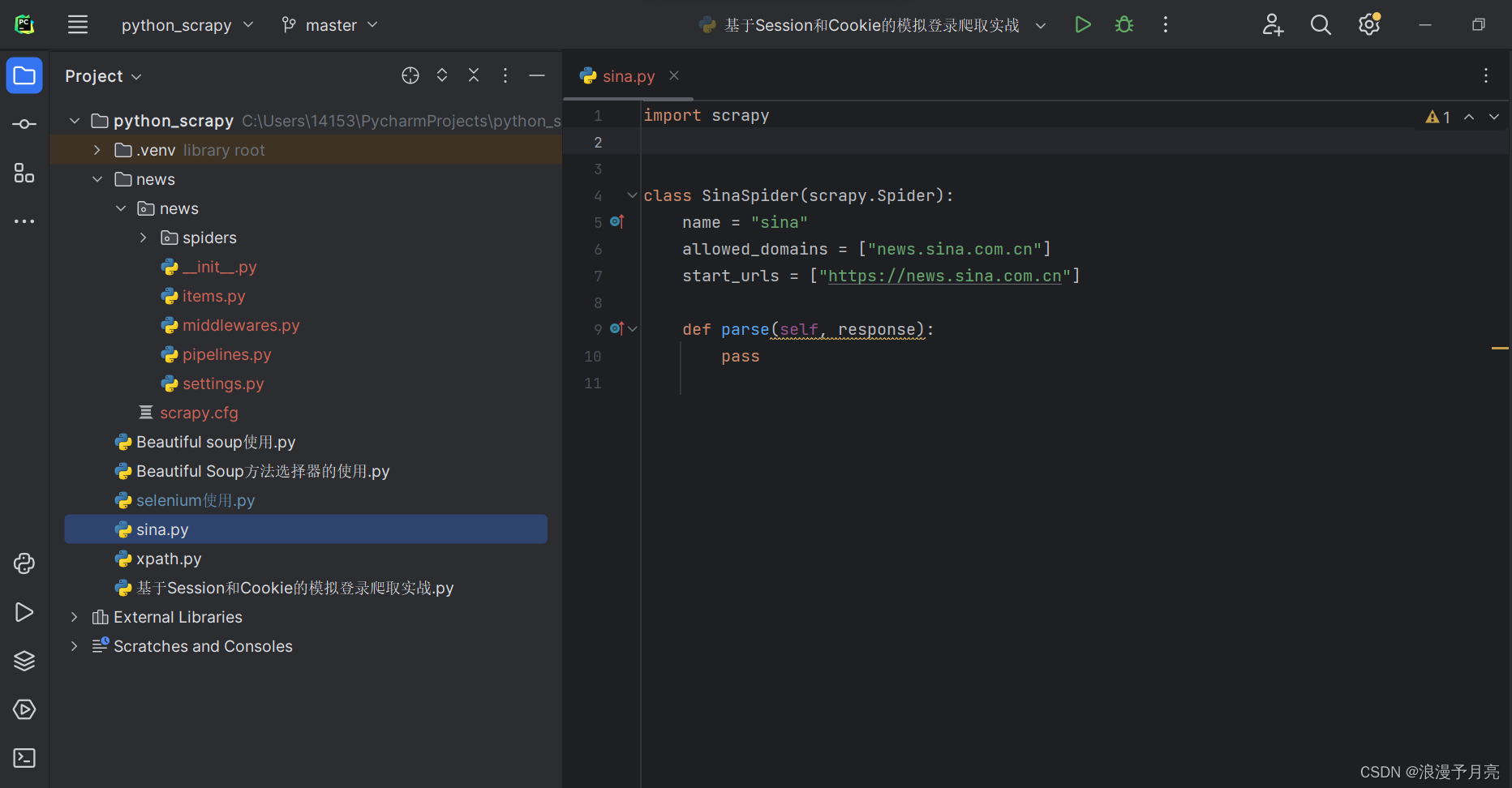
创建特定的爬取内容:scrapygenspider ___ ___
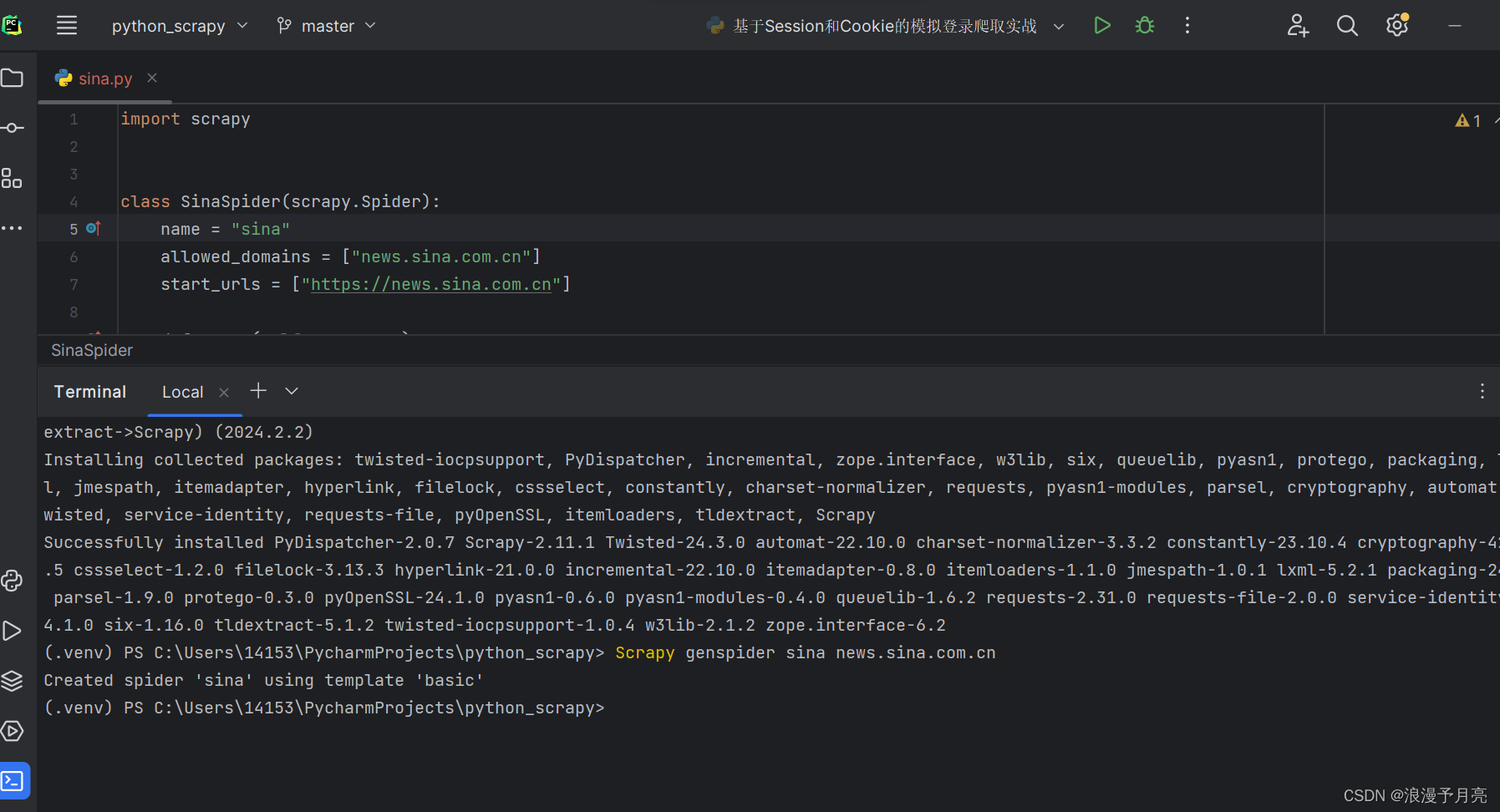
Scrapy基本参数介绍
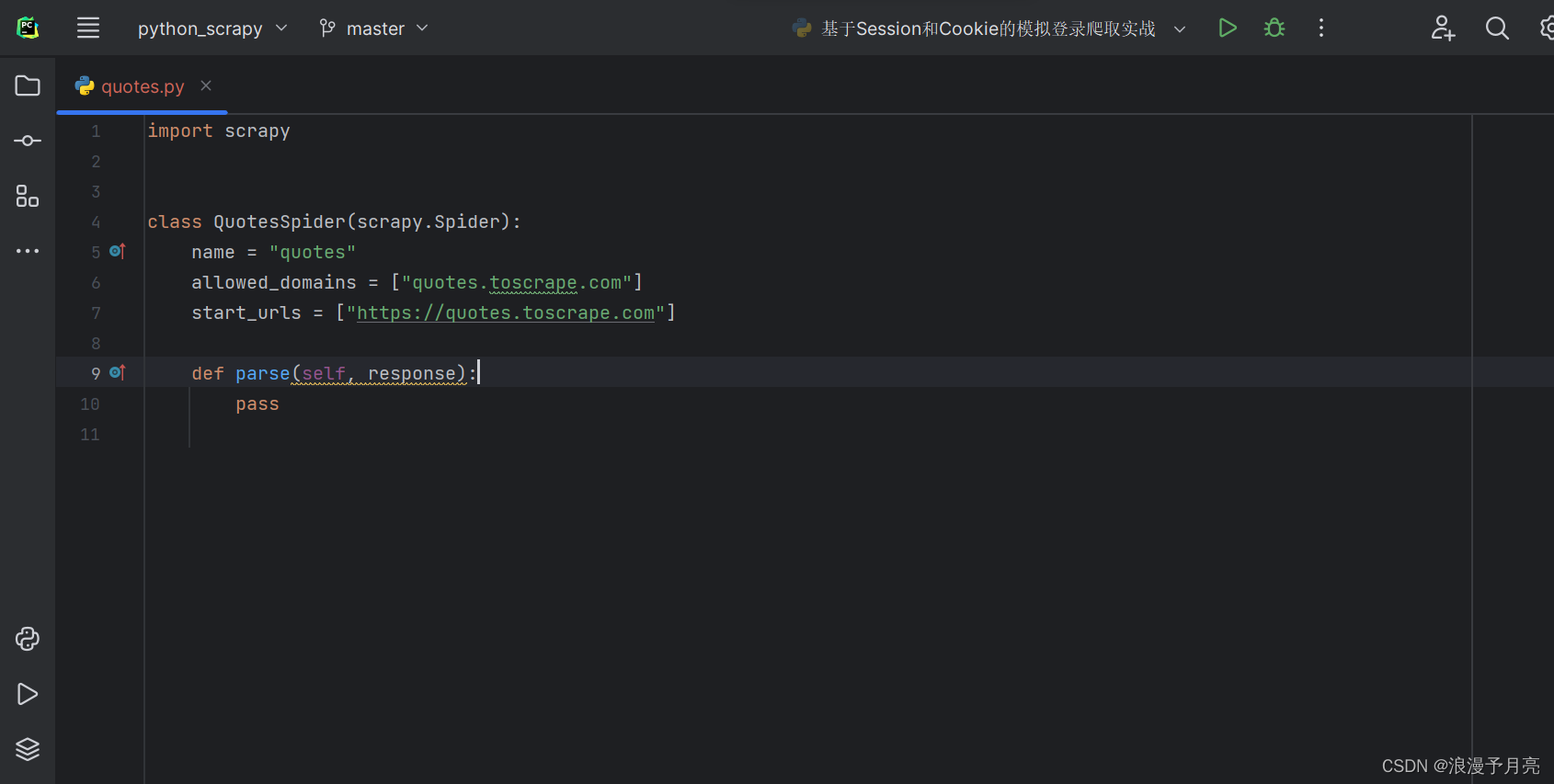
name:项目名称,用于进行区别
allowed_domains:允许爬取的域名
start_urls:包含在启动时的URL列表,初始请求是由他来定义的
parse:start_urls里面的链接构成的请求完成下载后,parse的下载方法就会被调用,返回的响应就会作为唯一的参数传递给parse方法
scrapy crawl __ 进行执行的命令
3.3 Selector的使用
1.直接使用
from scrapy import Selector
body = '<html><head><title>hello world</title></head><body></body></html>'
selector = Selector(text=body)
title = selector.xpath('//title/text()').extract_first()
print(title)
2.Scrapy shell
使用方式:Scrapy shell + 网址
<!DOCTYPE html>
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' alt='image1'/></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' alt='image2'/></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' alt='image3'/></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' alt='image4'/></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' alt='image5'/></a>
</div>
</body>
</html>
3 使用XPath方式
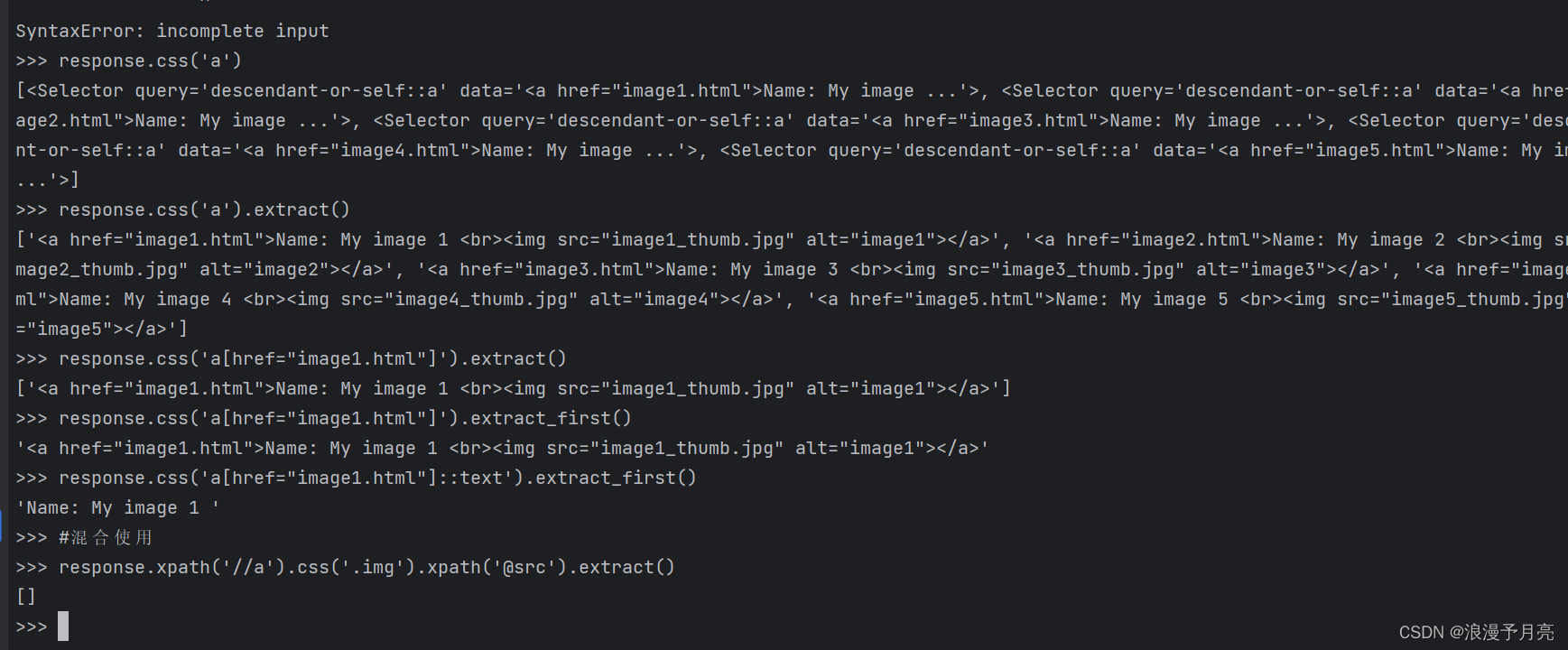
4.CSS选择器
3.4 Spider的使用
基础属性介绍
name:爬虫名称
allowed_domains:允许爬取的域名
start_status:开始时候的url列表
custom_settings:一个字典,专属于Spider的配置
crawler:该属性由from_crawler进行设置
settings:一个setting对象,可以直接获取项目的全局项目变量
实例展示
import scrapy
from scrapy import Request
class HttpbinSpider(scrapy.Spider):
name = "httpbin"
allowed_domains = ["www.httpbin.org"]
start_urls = ["https://www.httpbin.org/get"]
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
}
cookies = {'name':'germey', 'age':'26'}
# 重写 start_requests 方法
def start_requests(self):
for offset in range(5):
url = self.start_urls[0] + f'?offset={offset}'
# 访问 start_urls 中的第一个 URL
yield Request(url, headers=self.headers, cookies=self.cookies, callback=self.parse_response, meta={'offset': offset})
# 解析响应的方法
def parse_response(self, response):
print(response.url) # 请求的 URL
print(response.request) # 对应的请求对象
print(response.status) # 状态码
print(response.headers) # 响应头
print(response.text) # 响应体
print(response.meta) # 附加信息
3.4 Requests和Response
Requests
- url:requests的页面链接
- callback:Requests的回调方法,通常需要定义在Spider类里面,而且需要一个对应的response参数,如果不指定,则会默认使用parse
- method:Requests的方法,默认为get方法,还可以设置为Post,Put,Delete等
- meta:requests进行请求的时候附带的额外参数
- body:requests的内容
- headers:字典形式的头
- cookies:字典或者列表形式
- encoding:编码格式
- prority:requests的优先级,默认为0
- dont_filter:requests不去重,设置为True表示不进行去重操作
Response
- url:网页的链接
- status:response的状态码
- headers:响应头
- body:返回的源代码结果
- certificate:代表一个SSL证书对象
- urljoin:是一个对URL进行处理的方法
- follow:根据URL来生成后续的Requests方法
- text:同body属性,但是结果为Str类型
- selector:进一步的调用css和xpath方法进行
- css:传入CSS选择器进行内容提取
- json:直接将text属性转化为JSON对象
3.5 Downloader Middleware的使用
该为下载中间键,处于Engine和Downloader之间的处理模块,requests和response都会经过该模块的处理
每一个都是通过定义process_request和process_response方法分别对requests和response进行处理
process_request(request,spider)
在requests在被从Engine调用发送到Downloader之前,我们都可以使用process_request方法对request进行处理
request:Request对象,被处理的Request
spider:Spider对象,此时的Request对应的Spider对象
- 如果 process_request 返回 None,则表示不对请求进行任何修改,直接发送到下载器。
process_request(self, request, spider): # 在这里可以对请求进行处理 return None
- 如果 process_request 返回一个新的 Request 对象,则表示将返回的新请求对象发送到下载器,而不发送原始请求对象。这允许你创建一个新的请求来替代原始请求,通常用于重定向或者过滤请求。
process_request(self, request, spider): # 创建一个新的请求对象来替代原始请求 new_request = Request(url="https://example.com/new_url", callback=self.parse_new) return new_request
- 如果 process_request 返回一个 Response 对象,则表示直接将这个响应对象发送给引擎,绕过下载器直接处理响应。这通常用于返回预先获取的响应或者错误处理。
process_request(self, request, spider): # 直接返回一个响应对象 return Response(url=request.url, body=b"Response content", status=200)
process_response(reqeust,response,spider)
- 当返回为Request对象时:该对象会重新放入调度队列当中等待被调度,相当与一个全新的reqeust,会被process_request方法顺次处理
- 当返回为Response对象时:会继续被调用,对该对象进行处理
- 如果抛出IgnoreRequest异常:reqeust的errorback方法会回调,如果异常没有被处理,则其被忽略掉
process_exception(request,exception,spider)
- 当返回为None时,其Process_exception会依次被调用,直到所有的方法被调用完毕
- 当返回为response对象时,更低优先级的process_exception方法不再被继续调度,process_response转而被调度
- 返回为requests对象时,其不再被调度,reqeust对象会重新放到调度队列中等待被调度,相当于一个全新的request,该request会被process_request顺次处理
,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
3.6 Spider Middleware的使用
核心方法
process_spider_input(response,spider)
- 如果返回的为None,Scrapy会继续处理该response,调用其他的所有spider middleware,直到spider处理该response
- 如果抛出的是一个异常,不会调用spider middleware的process_spider_input方法,并调用requests的errback方法,errback的输出则会以另一个方向被重新输入中间件,使用process_spider_output方法来处理,当其再抛出异常,则使用process_spider_exception来处理
process_spider_output(response,result,spider)
- 必须返回包含requests和Item对象的迭代对象
process_spider_exception(response,exception,spider)
- 如果返回的为None 那scrapy将继续处理该异常,调用该模块当中的process_spider_exception方法,直到所有的都被调用
- 如果返回的为一个可迭代对象(requests和response),则其他的process_spider_out方法被调用,其他的则不会被调用
process_start_requests(start_requests,spider)
- 必须返回另一个包含requests的可迭代对象
HttpErrorMiddleware
主要作用是过滤我们需要忽略的Response
from scrapy.exceptions import IgnoreRequest
from scrapy.spidermiddlewares.httperror import HttpError
class HttpErrorMiddleware:
def process_spider_input(self, response, spider):
if isinstance(response, HttpError):
spider.logger.warning(f"Ignoring HTTP error for URL: {response.request.url}")
raise IgnoreRequest()
return None
@classmethod
def from_crawler(cls, crawler):
return cls()
OffsiteMiddleware
过滤不符合allowed_domains的Request
from scrapy.exceptions import IgnoreRequest
class OffsiteMiddleware:
def process_spider_input(self, response, spider):
if response.request.url not in spider.allowed_domains:
spider.logger.warning(f"Ignoring offsite request for URL: {response.request.url}")
raise IgnoreRequest()
return None
@classmethod
def from_crawler(cls, crawler):
return cls()
UrlLengthMiddleware
主要作用是根据Request的URL长度对Request进行过滤,如果URL过长就会被忽略
from scrapy.exceptions import IgnoreRequest
class UrlLengthMiddleware:
def __init__(self, max_url_length=100):
self.max_url_length = max_url_length
def process_spider_input(self, response, spider):
if len(response.request.url) > self.max_url_length:
spider.logger.warning(f"Ignoring request with long URL: {response.request.url}")
raise IgnoreRequest()
return None
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings.getint('MAX_URL_LENGTH', 100))
3.7 Item Pipeline的使用
主要功能:
- 清洗HTML数据
- 验证爬取数据,检查爬取字段
- 查重并丢弃重复的内容
- 将爬取结果存储到数据库中
process_item(item,spider)
- 如果返回的为Item对象,则该Item会被低优先级的Item Pipeline的process_item方法处理,直到所有的方法被调用完毕
- 如果抛出DropItem异常,则该Item会被丢弃,不会再进行处理
open_spider(self,spider)
在Spider开启的时候自动进行调用,我们可以做一些收尾的工作,如关闭数据库连接等等
close_spider(spider)
该是在Spider关闭的时候自动进行调用的
from_crawler(cls,crawler)
用@classmthod标识,接收一个crawler参数,通过这个参数,我们可以拿到所有的核心组件
3.8 Extension的使用
定义from_crawler类方法,其第一个参数为cls,第二个参数为crawler
自定义组件的实现















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









