






 本文介绍了如何通过Python计算预测结果的评价指标,包括平均绝对误差(MAD)、相对误差绝对值的平均值(AARE)、方差(S^2)以及希尔不等系数(TheilIC)和修正的不等系数(RIC),这些指标帮助衡量预测精度并确定模型性能。
本文介绍了如何通过Python计算预测结果的评价指标,包括平均绝对误差(MAD)、相对误差绝对值的平均值(AARE)、方差(S^2)以及希尔不等系数(TheilIC)和修正的不等系数(RIC),这些指标帮助衡量预测精度并确定模型性能。
假设有 n 个历史数据,通过某种预测方法得到其模拟值
,对此,可以通过以下方法来评价预测结果:
1.平均绝对误差MAD
Python代码实现:
import numpy as np
def calculate_mad(y_hat, y):
n = len(y)
e = np.abs(y_hat - y)
mad = np.sum(e) / n
return mad
# 定义已知数据
y = np.array([y1, y2, ..., yn]) # 已知向量 y
y_hat = np.array([y_hat1, y_hat2, ..., y_hatn]) # 已知向量 y_hat
# 计算 MAD
mad = calculate_mad(y_hat, y)
print("MAD 的值为:", mad)
2.相对误差绝对值的平均值AARE
| AARE范围 | 预测模型精度 |
| 10%以下 | 精度较高 |
| 10%~20% | 精度良好 |
| 20%~50% | 预测较为可行 |
| 50%以上 | 预测不可行 |
Python代码实现:
import numpy as np
def calculate_aare(y_hat, y):
n = len(y)
e = np.abs((y_hat - y) / y)
aare = np.sum(e) / n
return aare
# 定义已知数据
y = np.array([y1, y2, ..., yn]) # 已知向量 y
y_hat = np.array([y_hat1, y_hat2, ..., y_hatn]) # 已知向量 y_hat
# 计算 AARE
aare = calculate_aare(y_hat, y)
print("AARE 的值为:", aare)
3.方差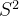
Python代码实现:
import numpy as np
def calculate_squared_error(y_hat, y):
n = len(y)
squared_error = np.sum((y_hat - y) ** 2) / n
return squared_error
# 定义已知数据
y = np.array([y1, y2, ..., yn]) # 已知向量 y
y_hat = np.array([y_hat1, y_hat2, ..., y_hatn]) # 已知向量 y_hat
# 计算 S^2
squared_error = calculate_squared_error(y_hat, y)
print("S^2 的值为:", squared_error)
4.希尔不等系数Theil IC
IC的值介于0和1之间,越接近0说明预测精度越高。
Python代码实现:
import numpy as np
def calculate_IC(y_hat, y):
n = len(y)
numerator = np.sqrt(np.sum((y_hat - y)**2) / n)
denominator = np.sqrt(np.sum(y_hat**2) / n) + np.sqrt(np.sum(y**2) / n)
IC = numerator / denominator
return IC
# 示例数据
y_hat = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 6, 8, 10])
# 计算IC
ic_value = calculate_IC(y_hat, y)
print("IC值:", ic_value)
5.修正的不等系数RIC
RIC的值介于0和之间,越接近0说明预测精度越高,RIC=0称为完美预测。
Python代码实现:
import numpy as np
def calculate_RIC(y_hat, y):
numerator = np.sqrt(np.sum((y_hat - y)**2))
denominator = np.sqrt(np.sum(y**2))
RIC = numerator / denominator
return RIC
# 示例数据
y_hat = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 6, 8, 10])
# 计算RIC
ric_value = calculate_RIC(y_hat, y)
print("RIC值:", ric_value)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









