






算法原理
1
)回溯搜索算法是一种穷举搜索的算法,通过逐个尝试所有可能的皇后放置位置,并利用剪枝策略减少无效的搜索路径,直到找到满足问题要求的解或者搜索完所有可能的情况。
2
)分支定界搜索算法是一种基于深度优先搜索的剪枝算法,其主要思想是通过逐行放置皇后,并在每一行确定皇后位置时进行剪枝,排除不可能出现解的分支,从而减少搜索空间。
测试数据
针对
N 皇后问题
,可以选择不同的 N 值进行测试,如 N=4、N=8 等。以 N = 4 为例,测试数据为一个 4×4 的棋盘。
主要流程
1.
初始化棋盘和解的列表:在开始解决问题之前,需要初始化一个棋盘,表示 N*N
的棋盘格子,以及一个解的列表,用于存储每个解的位置信息。
2. 放置皇后并检查冲突:在每一行中,依次尝试放置皇后,并检查当前位置是否与已放置的皇后冲突。冲突可能包括同一列、同一行或对角线上已存在皇后
3.
递归放置下一行的皇后:如果当前位置没有冲突,则将该位置标记为放置皇后,并递归调用函数处理下一行。
4.
判断是否找到完整的解:当放置到最后一行时,如果找到一个完整的解,即每一行都放置了一个皇后,则将解添加到结果列表中。
5.
回溯到上一行并继续尝试:如果当前位置无法放置皇后或已找到完整的解,需要回溯到上一行,并尝试下一个可行的位置。
主要模块功能
回溯搜索
- 初始化棋盘:创建一个 N×N 的二维数组,用于表示棋盘。
- 回溯搜索函数:负责递归地尝试放置皇后和回溯操作。
- 冲突判断函数:判断当前位置是否与已放置的皇后冲突。
- 记录解函数:将找到的解记录下来。
分支定界搜索
- place_queen(row, queens, n):放置皇后的函数,判断当前位置是否与已放置的 皇后冲突,并进行剪枝。
- backtrack(row, queens, n, solutions):回溯搜索函数,递归地放置下一行的皇后, 并判断是否找到完整的解。
- n_queens(n):N 皇后问题的入口函数,初始化数据结构并调用回溯搜索函数。
- is- solve_safe(row, col, queens):判断当前位置是否与已放置的皇后冲突。
数据结构设计
回溯搜索
- 棋盘:使用一个 N×N 的二维数组表示棋盘,其中每个位置可以用 0 表示 空,1 表示放置了皇后。
- 解空间:使用一个一维数组表示解空间,数组的索引表示行数,数组的值 表示该行皇后所在的列数。
分支定界搜索
- 使用一个一维数组 queens[] 来表示每行皇后的位置。数组的索引表示行号, 数组的值表示列号。
运行结果

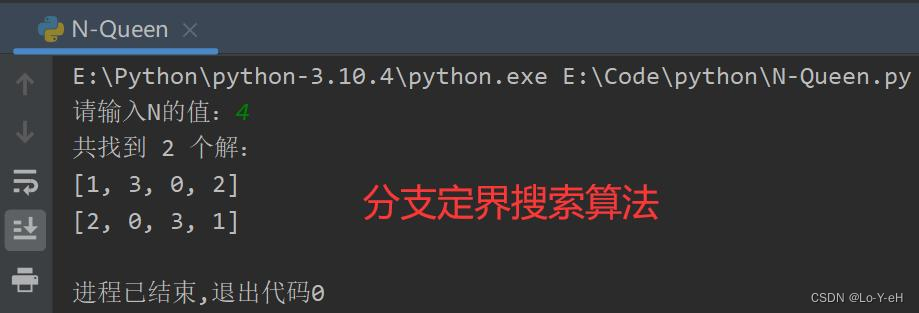
源码
回溯搜索算法代码
class NQueens:
def __init__(self, n):
self.n = n
self.board = [[0] * n for _ in range(n)]
self.solutions = []
def solveNQueens(self):
self.backtrack(0)
return self.solutions
def backtrack(self, row):
if row == self.n:
solution = []
for i in range(self.n):
col = self.board[i].index(1)
solution.append('.' * col + 'Q' + '.' * (self.n - col - 1))
self.solutions.append(solution)
return
for col in range(self.n):
if self.isSafe(row, col):
self.board[row][col] = 1
self.backtrack(row + 1)
self.board[row][col] = 0
def isSafe(self, row, col):
# Check if the current position is safe for the queen
for i in range(row):
if self.board[i][col] == 1:
return False
j = row - i
if col - j >= 0 and self.board[i][col - j] == 1:
return False
if col + j < self.n and self.board[i][col + j] == 1:
return False
return True
# 获取用户输入的N值
n = int(input("请输入N的值:"))
# 解决N皇后问题
queens = NQueens(n)
solutions = queens.solveNQueens()
# 输出解
print(f"{n}皇后的所有解如下:")
for solution in solutions:
for row in solution:
print(row)
print()分支定界搜索算法代码
def is_safe(row, col, queens):
# 检查当前位置与已放置皇后的位置是否冲突
for i in range(row):
# 检查是否同列或在对角线上
if queens[i] == col or queens[i] - col == i - row or queens[i] - col == row - i:
return False
return True
def place_queen(row, queens, n, solutions):
# 放置皇后的函数
if row == n:
# 找到一个完整解,将解添加到结果列表中
solutions.append(queens.copy())
else:
for col in range(n):
if is_safe(row, col, queens):
# 当前位置安全,放置皇后并继续递归放置下一行的皇后
queens[row] = col
place_queen(row + 1, queens, n, solutions)
def backtrack(n):
queens = [-1] * n # 存储每行皇后的位置,初始化为-1
solutions = [] # 存储所有解的列表
place_queen(0, queens, n, solutions)
return solutions
def solve_n_queens(n):
solutions = backtrack(n)
print(f"共找到 {len(solutions)} 个解:")
for solution in solutions:
print(solution)
# 从用户输入获取N的值
n = int(input("请输入N的值:"))
solve_n_queens(n)时间复杂度
回溯搜索算法
回溯搜索算法的时间复杂度取决于搜索的解空间大小。对于
N
皇后问题,解空间的大小为 N^N
,因为每一行有
N
个选择,共
N
行。最坏情况下,需
要遍历所有的解空间,因此时间复杂度为
O(N^N)
。
分支定界搜索算法
分支定界搜索算法的时间复杂度取决于解的数量。
N
皇后问题,最坏情况下的时间复杂度是指数级的,即 O(N!)
。这是因为搜索空间的大小与阶乘级别的全排列相关。实际上,剪枝操作可以大大减少搜索的次数,因此实际运行时间往往会远小于最坏情况。
小结
回溯搜索算法通过穷举搜索的方式, 递归地尝试所有可能的解,并通过剪枝操作来减少搜索空间。分支定界搜索算法在回溯搜索的基础上,通过剪枝策略排除不可能出现解的分支,从而更加高效地搜索到解。在问题规模较大时,分支定界搜索算法的效率更高。















 2878
2878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









