







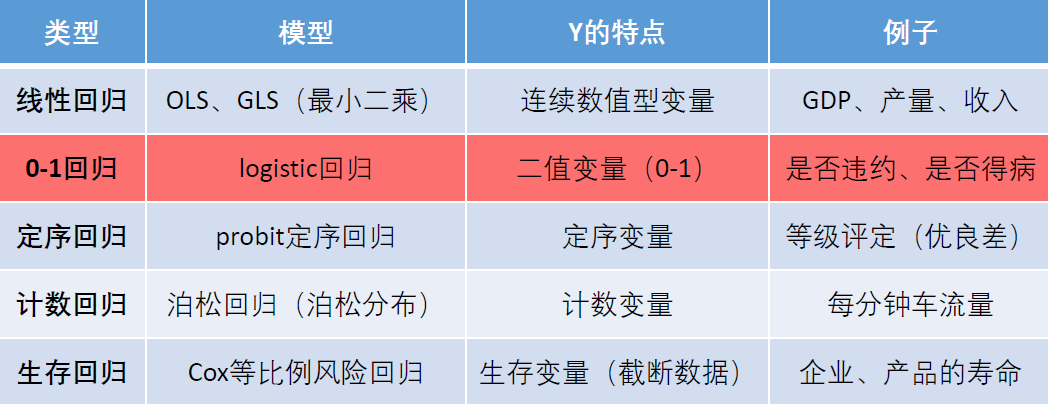
分类模型
二分类模型
对于二分类模型,介绍逻辑回归(logistic regression)和Fisher线性判别分析两种分类算法;对
于多分类模型,将简单介绍Spss中的多分类线性判别分析和多分类逻辑回归的操作步骤
水果分类例子

这个实际上就是一个二分类问题,通过属性推断类别。
逻辑回归logistic regression
注意:对于因变量为分类变量的情况,我们可以使用逻辑回归进行处理。把y看成事件发生的概率,y>=0.5表示发生;y<0.5表示不发生
线性概率模型(Linear Probability Model,简记LPM)

但是会出现问题。预测值可能会出现大于1以及小于0的情况,这种是不符合概率的异常。
两点分布(伯努利分布)

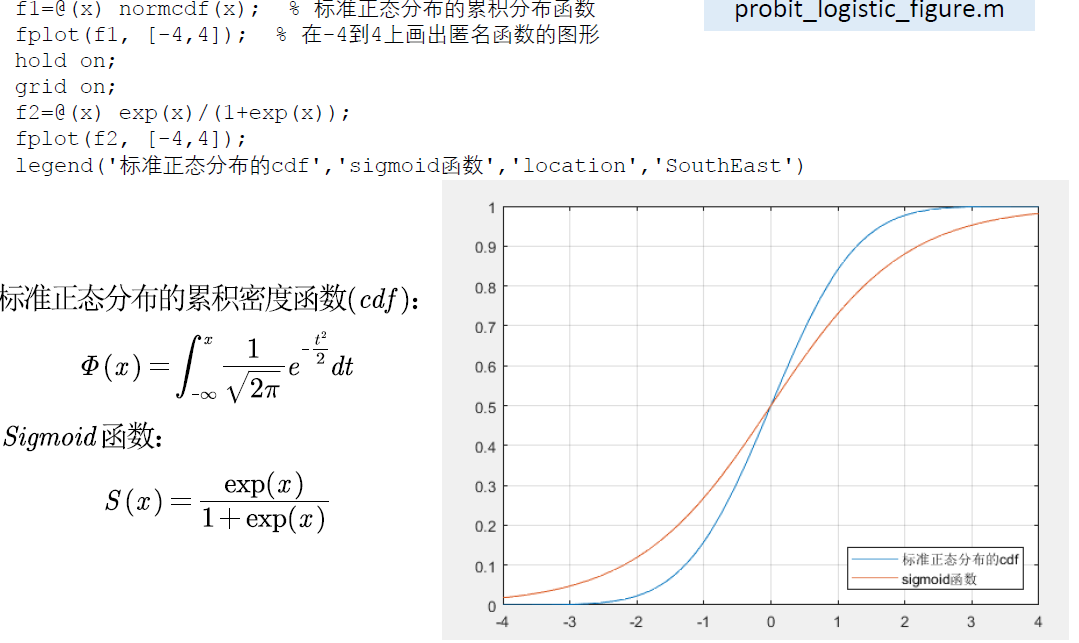
连接函数的取法

由于后者有解析表达式(而标准正态分布的cdf没有),所以计算logistic模型比probit模型更为方便
函数图像对比
怎么求解?

怎么用于分类?

将求出来的beta代入得到的结果大于0.5则预测的y = 1,否则 y =0
spss求解二分类
数据预处理:生成虚拟变量
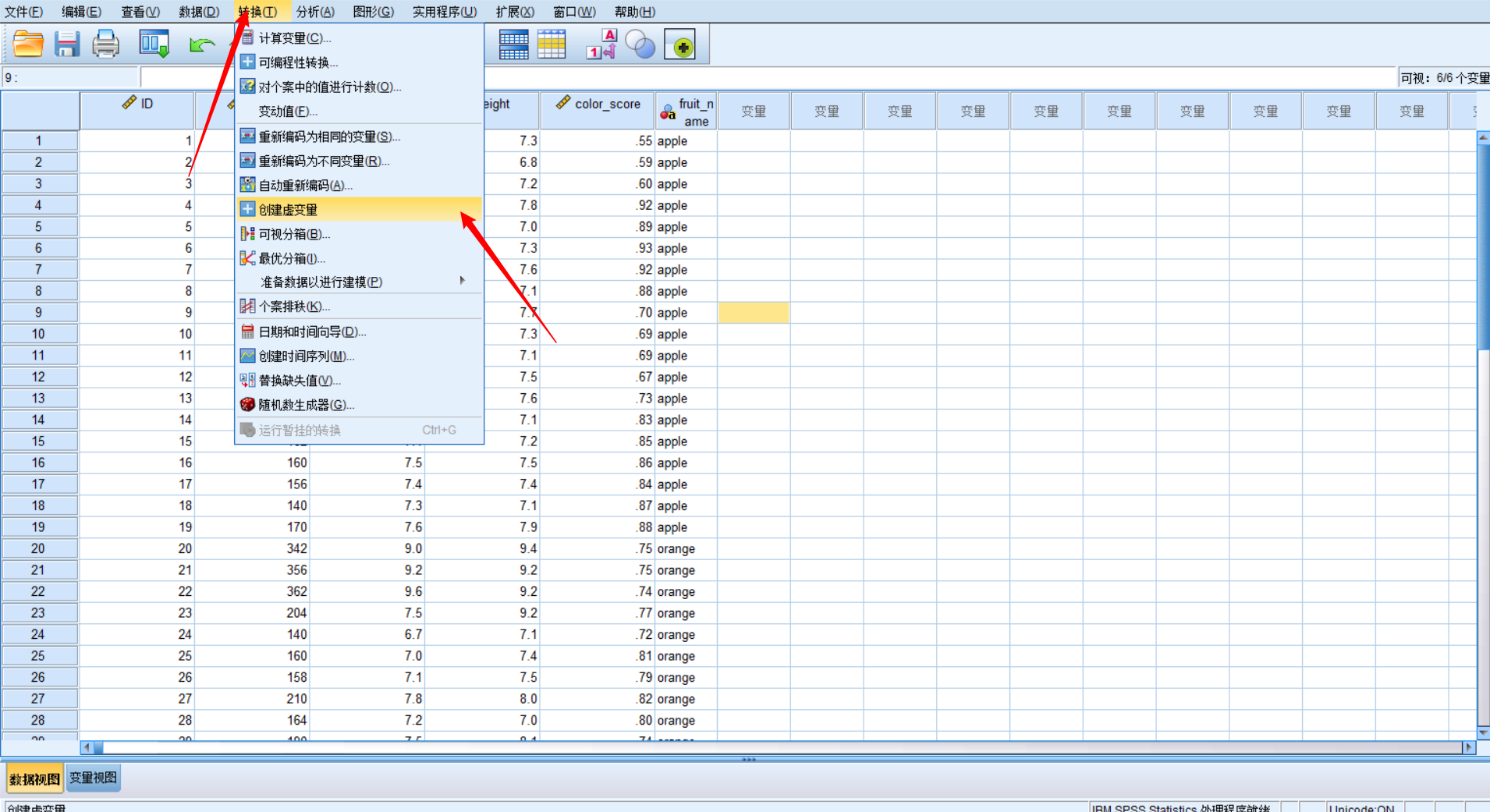
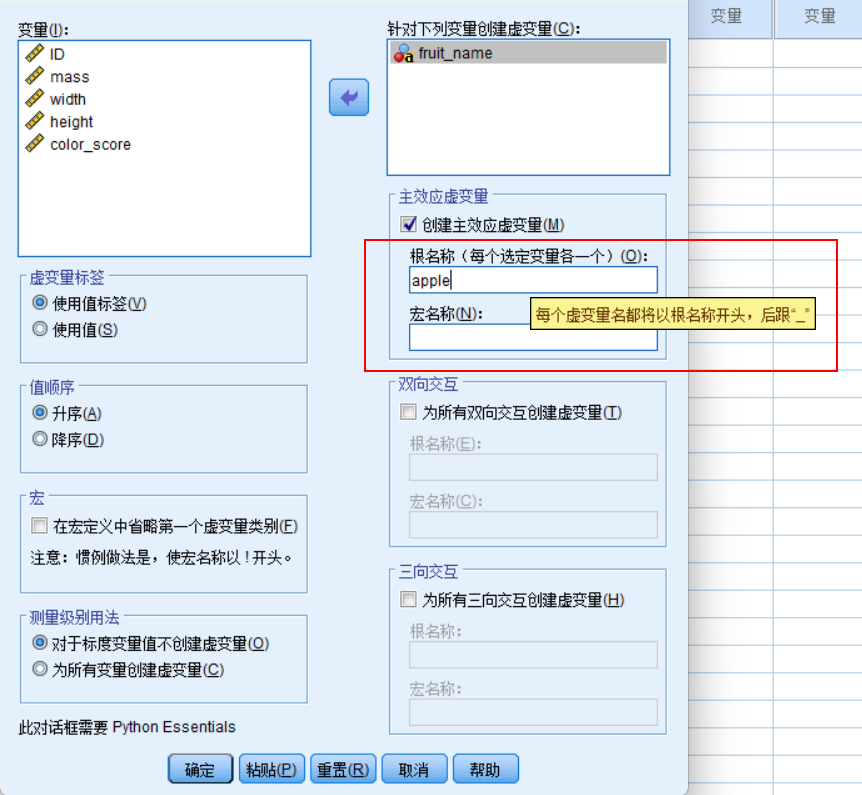
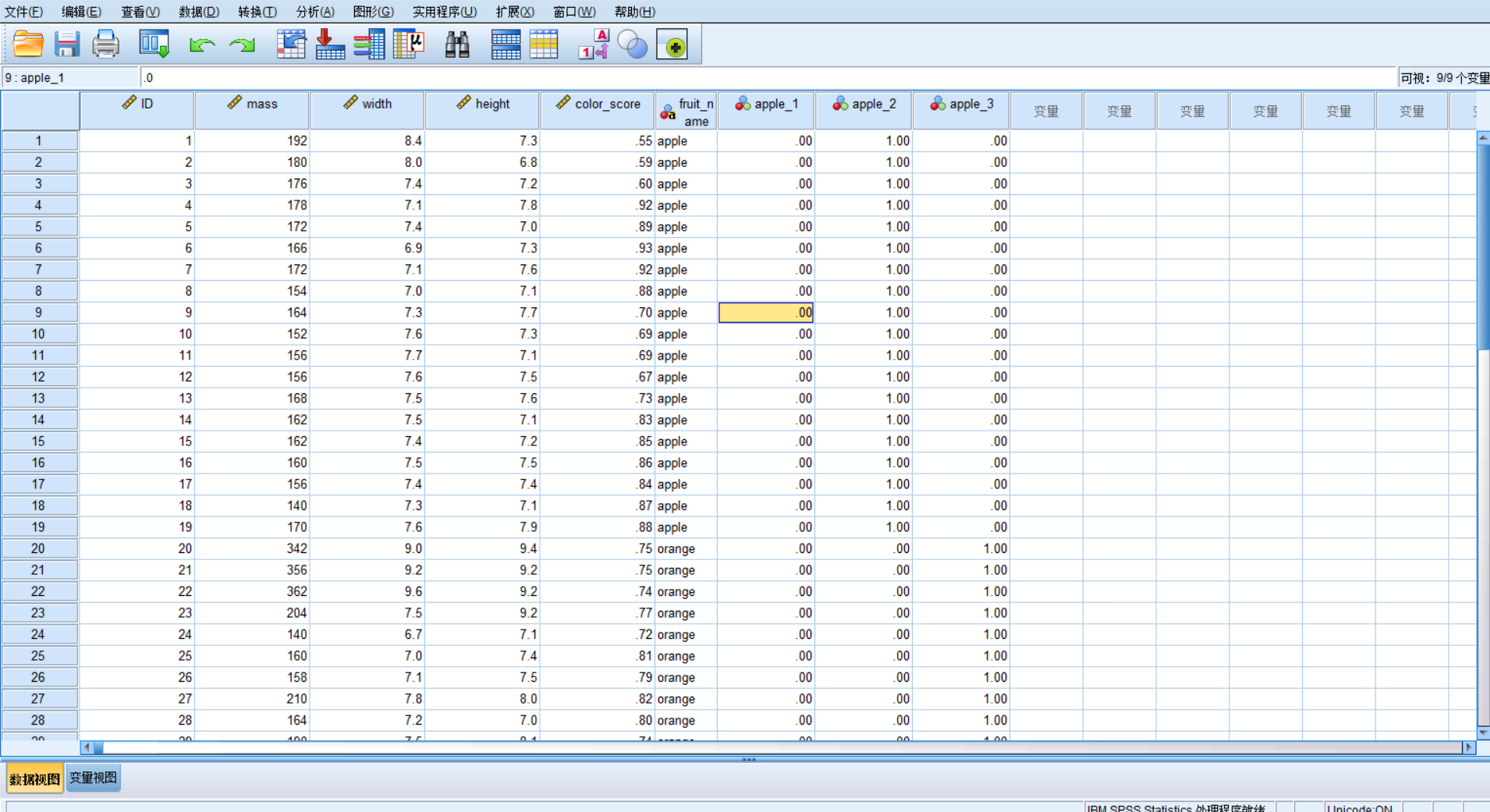
这样就变成了数值变量了。
Spss求解逻辑回归
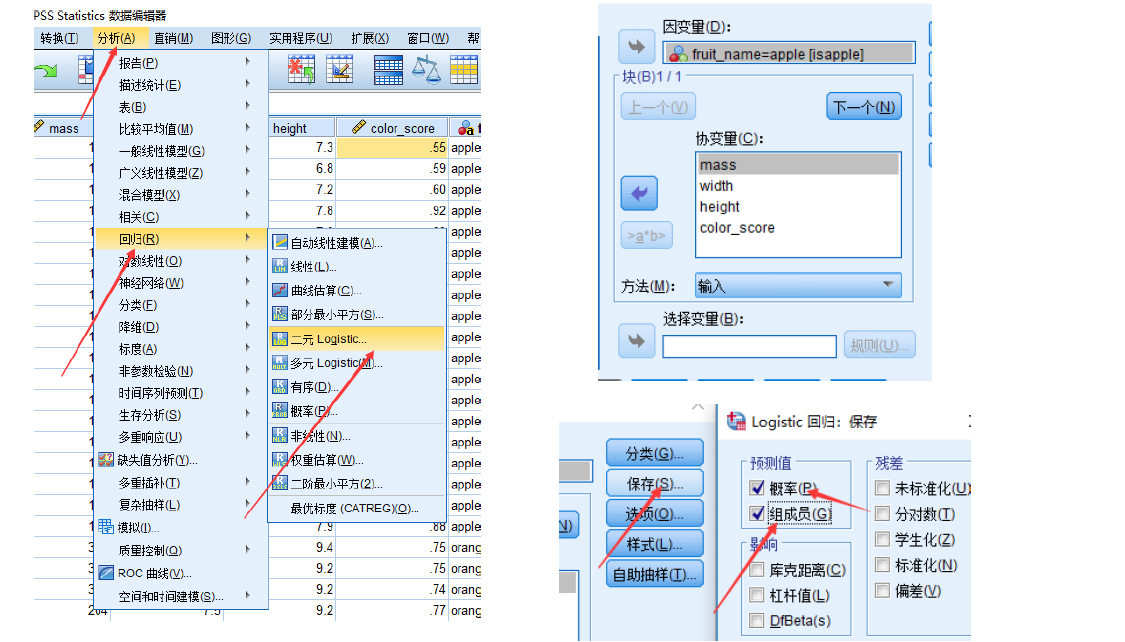
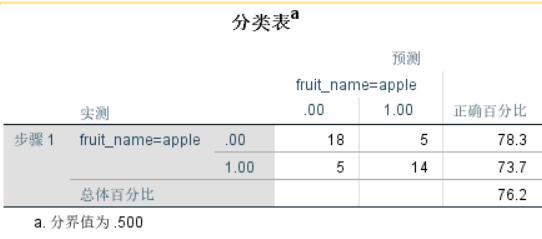
预测成功率
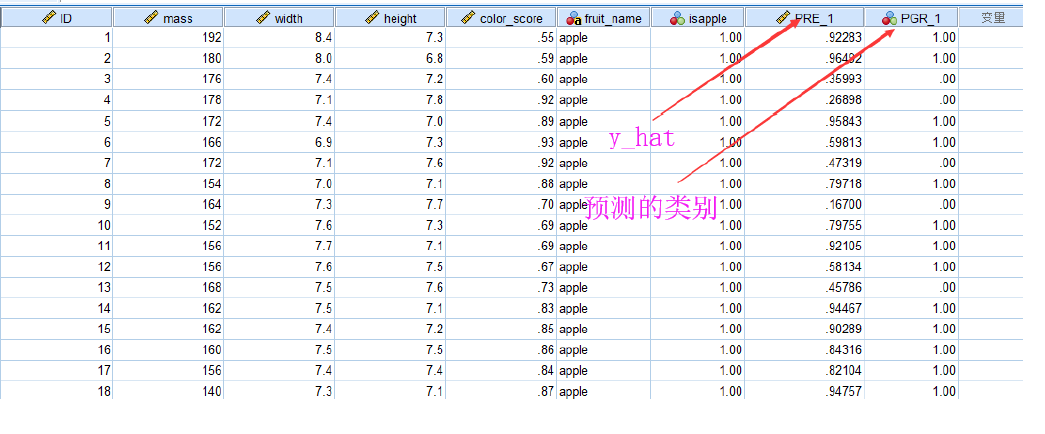
逻辑回归系数表


表格中新添的两列解读
逐步回归分析
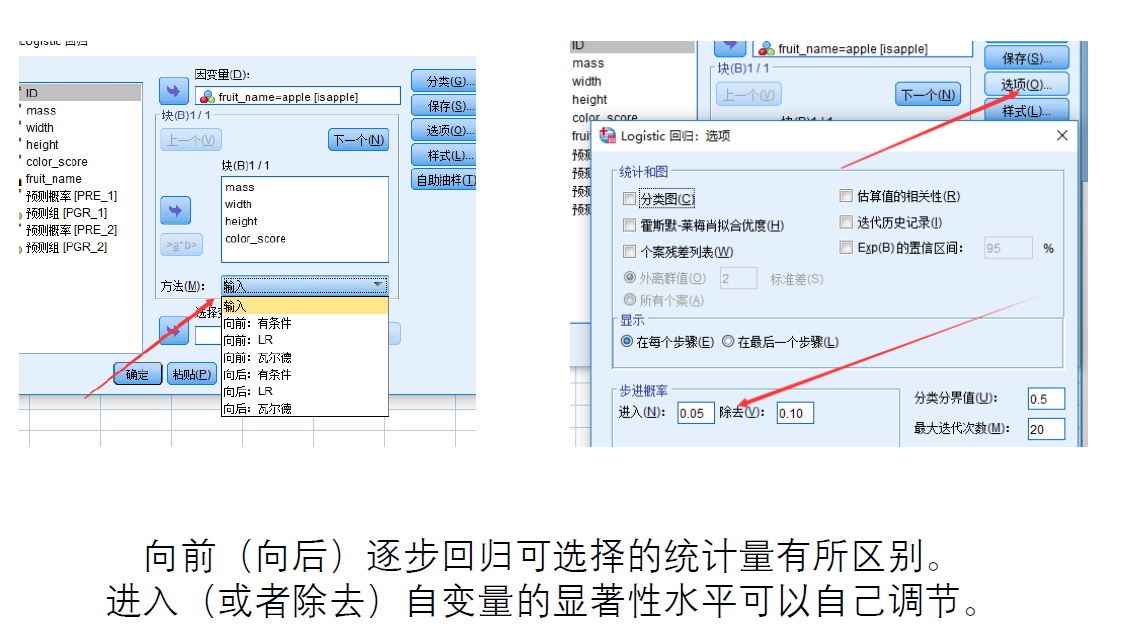
假如自变量有分类变量怎么办?
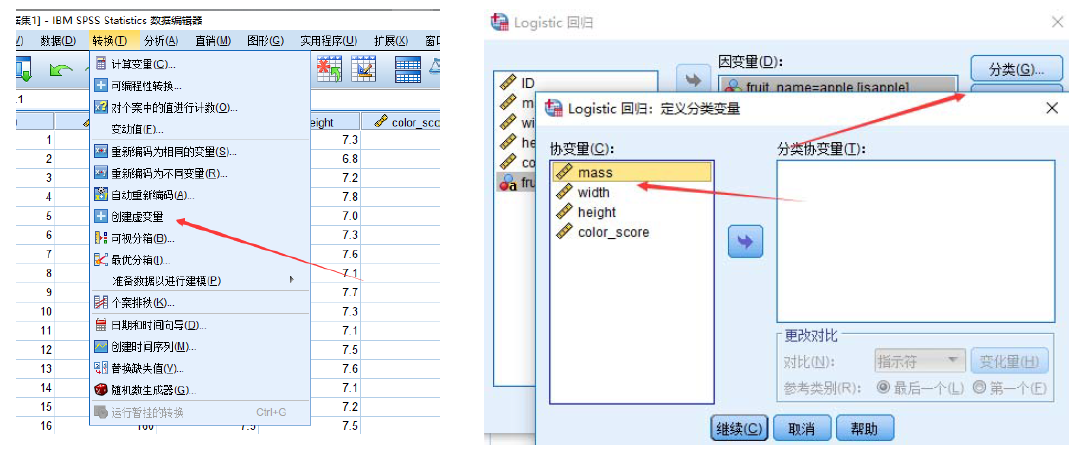
两种方法
(1)先创建虚拟变量,然后删除任意一列以排除完全多重共线性的影响;
(2)直接点击分类,然后定义分类协变量,Spss会自动帮我们生成。
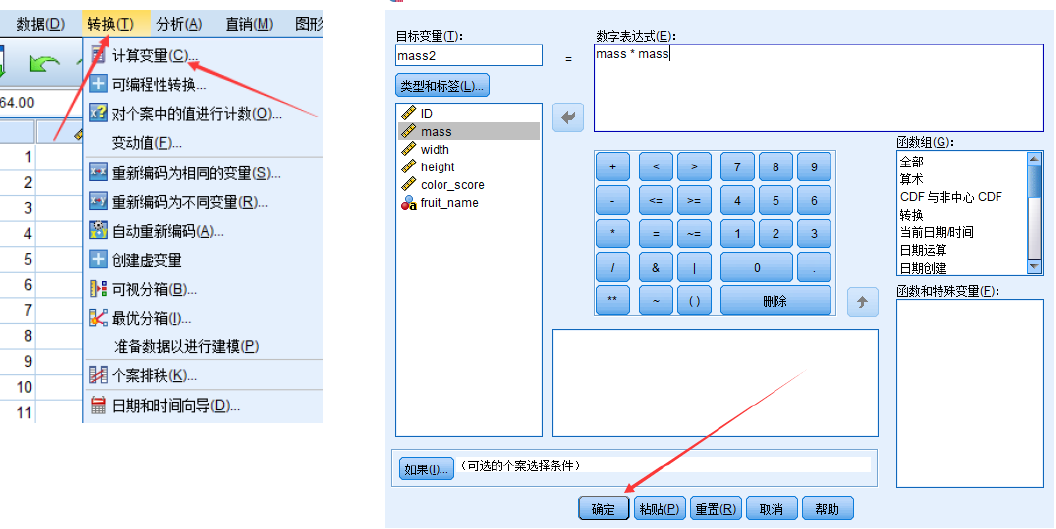
预测结果较差怎么办?
可在logistic回归模型中加入平方项、交互项等
加入平方项后结果
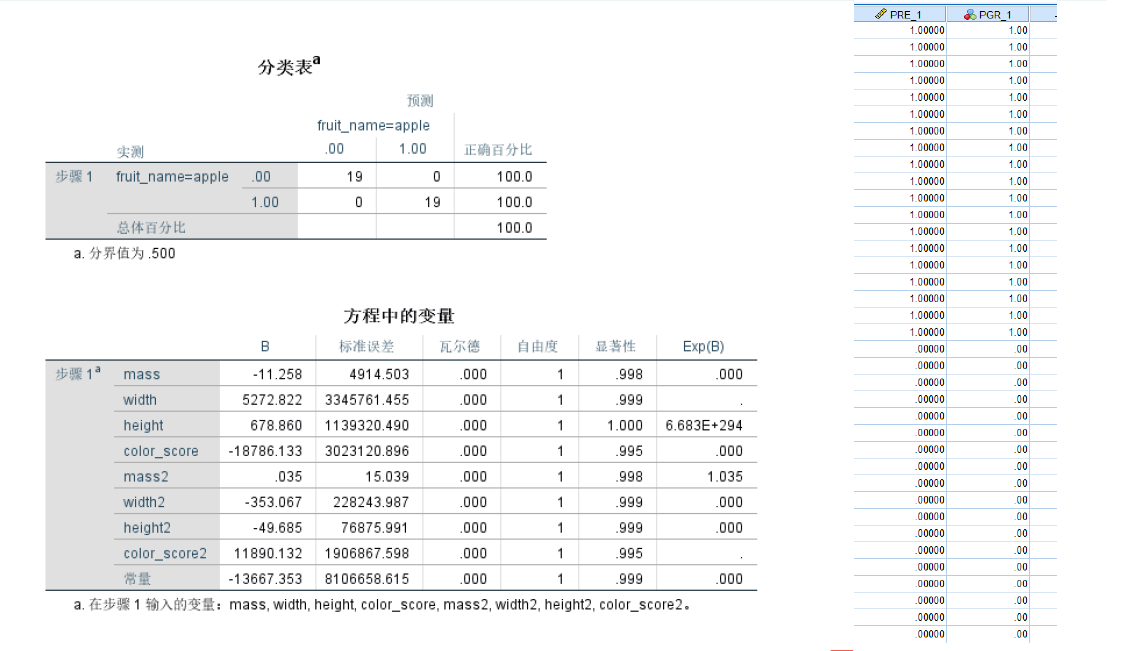
过拟合现象

不是说高次项越多越好的!
如何确定合适的模型
把数据分为训练组和测试组,用训练组的数据来估计出模型,再用测试组的数据来进行测试。(训练组和测试组的比例一般设置为80%和20%)
已知分类结果的水果ID为1‐38,前19个为苹果,后19个为橙子。
每类水果中随机抽出3个ID作为测试组,剩下的16个ID作为训练组。(比如:17‐19、36‐38这六个样本作为测试组)比较设置不同的自变量后的模型对于测试组的预测效果。
为了消除偶然性的影响,可以对上述步骤多重复几次,最终对每个模型求一个平均的准确率,这个步骤称为交叉验证
欢迎订阅

本文由博客一文多发平台 OpenWrite 发布!

















 4774
4774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











