







目录
一.无约束优化:
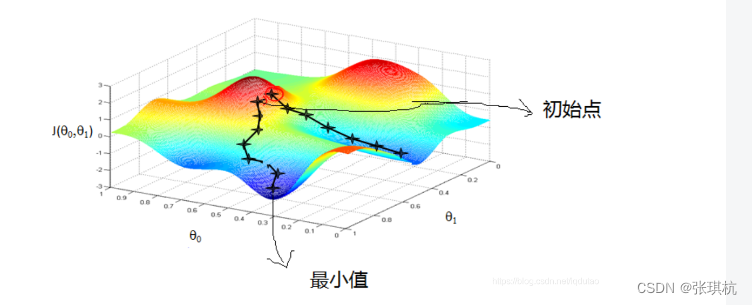
1.简单来说就是从所有可能的解中选择出依照某种指标来说最优的解,从数学上来说就是一个方程有许多个极值中找到最小或最大值
2.梯度下降:梯度下降法是一种算法,但不像多元线性回归那样是一个具体的算法,而是一个通用的,也就是许多算法(无约束优化问题)都可以用的一种优化算法。梯度就是导数,我们高中时都知道,对一个函数求导再令导数等于零,解出来就可以得到这个函数的所有极值
就如我们上面所说,比如二次函数求导后就很容易得到最小值和最大值,那么三次呢,四次呢,带指数,ln……当函数复杂的时候我们就不好求得最大值,最小值了。
从而有了下降,也就是它从一个起点开始,反复使用某种规则从移动到下一个点,因为我们对函数求导了,当导数等于零的时候就是极值点了,也就是我们以某种规则一直移动,直到收敛于零的时候,我们就找到了极值点了。
3.梯度下降的直观理解:就像我们再十万大山中的某个山顶开始下山,因为山很多山底也多,这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的方向走,然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷
4.梯度下降公式:
这里梯度下降法的公式就是一个式子指导计算机迭代过程中如何去调整 ,可以通过泰勒公式一阶展开来进行推导和证明:

这里的 wj就是 中的某一个 j = 0...m,这里的 就是梯度下降图里的 learning step,很多时候也叫学习率 learning rate,很多时候也 用
表示,这个学习率我们可以看作是下山迈的步子的大小,步子迈的大下山就快。如图

学习率一般为正数,比如下山的时候无论我们怎么向下走,都是要走出距离的,而距离没有负数。但是再机器学习里面数据一般都有许多个特征,也就是维度。而每一个特征都要迭代一次
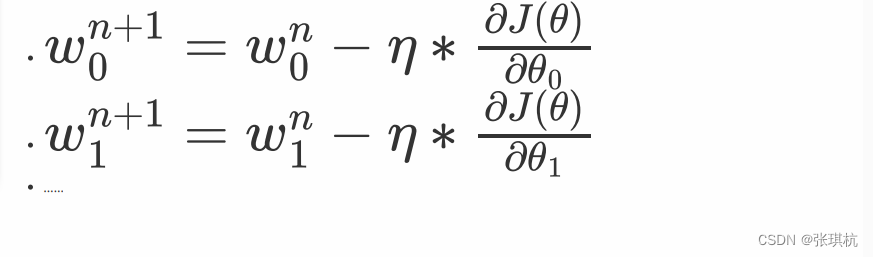
5.学习率大小:
学习率的大小就代表走我们每次迭代的大小,比如下山的时候每一步走的距离大小,人的腿不是无限长的,也不会特别短,所有学习率不能太大或者太小,太大就代表每次迭代后的数据太大,可能直接跨过去了,太小的话也不行,就像蜗牛也可以走长城,但跑的太慢太痛苦了,迭代次数多,算法太慢了。

我们再设置学习率的时候,一般会设置成一个较小又不能太小的值,0.1,0.01,0.001,0.0001。当然了,因为学习率是我们自己设置的,它是一个常数,但是也可以让他随着我们迭代的时候逐渐变小,防止设置的太大而跳过极值。
6.全局最优:
再上面我们从十万大山下来的时候,会有许多的山底,那么我们如何走到最低的山底呢?如果我们走的是右边那条路就是局部最小值,也就是极值但不是最小值。那么我们要如何保证走的是左边那条路呢?

7.梯度下降步骤:
1.先随机生成一个值,也就是我们准备下山的起点,就比如我们多元线性方程中的,随机生成一组数据w0,w1。。。。wn,期望为0方差为1的正太分布数据。
2.求梯度g,梯度计算导数,也就是曲线上的点的切线斜率,像着这个切线方向往下走
3.如果梯度g小于0,变大反之变小。也就是多元线性方程中的W值变大变小
4.判断本次下降是否收敛于山低,如果收敛跳出迭代,如果没有则继续第2~4步直到收敛,收敛的判断标准是:随着迭代进行损失函数Loss,变化非常微小甚至不再改变,即认为达到收敛。

举个栗子:

二:梯度下降方法:
1.梯度下降分三类:批量梯度下降BGD(Batch Gradient Descent)、小批量梯度下降MBGD(Mini-Batch Gradient Descent)、随机梯 度下降SGD(Stochastic Gradient Descent)。
这三种方法不一样的地方在于,批量梯度下降BGD再每一次下降迭代过程要使用全部样本跟新
小批量梯度下降MBGD每次下降迭代过程使用一部分样本跟新
随机梯 度下降SGD每次下降迭代过程随机选择一个样本来进行更新
2.线性回归梯度下降更新:
线性回归在上个文章说到了
最小二乘法公式:
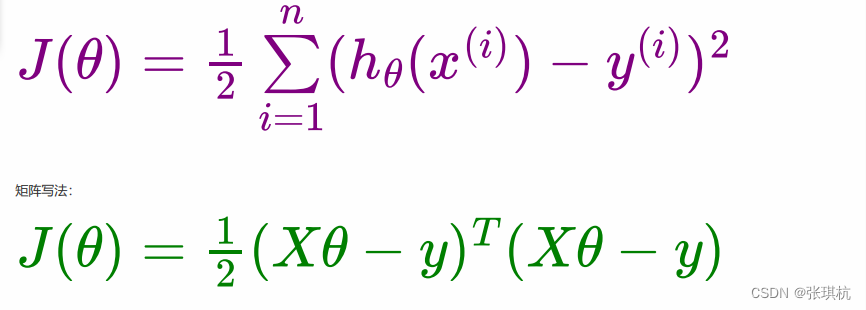
接着我们来讲解如何求解上面梯度下降的第 2 步,即我们要推导出损失函数的导函数来。
带入最小二乘法,两边对求导
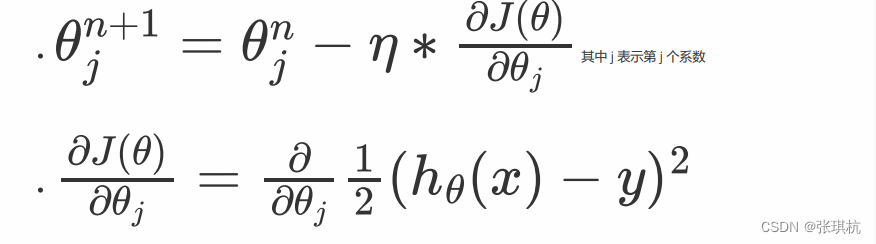
因为是对那么将括号中的数看成x,x**2的导数就对于2x根据链式求导法则得到(1)
h0(x)在线性方程中就是w0x0+w1x1+w2x2+.......+wnxn即是到这里我们是对
i来求偏导,那么和 wi没有关系的可以忽略不计,所以只剩下 xi。
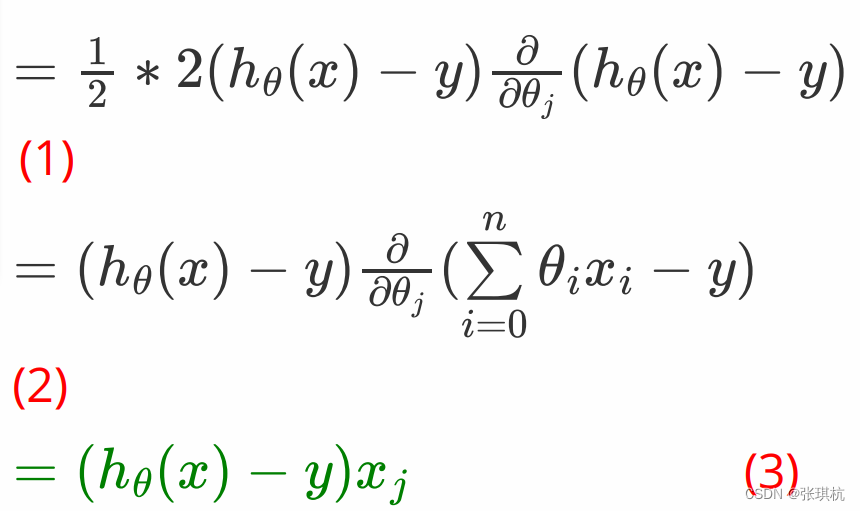
所以:

批量梯度下降BGD:
每次都要用所有样本跟新,所以梯度是所有样本的梯度和

优点:1.一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。2.由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得 到全局最优。
缺点:当样本数目 n 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
随机梯度下降SGD:
随机选择一个样本来进行梯度下降,也就是梯度里面的样本x,y是随机取一个来做本次迭代

优点: 由于不是在全部训练数据上的更新计算,而是在每轮迭代中,随机选择一条数据进行更新计算,这样每一轮参数的更新速度大大 加快。
缺点:准确度下降。由于即使在目标函数为强凸函数的情况下,SGD仍旧无法做到线性收敛,也就是会走许多弯路。可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
小批量梯度下降MBGD
每次使用样本中的一部分来对本次下降迭代跟新,也就是在我们样本又1000个的时候,我们取10个来跟新。对应到公式里就是将梯度里的x,y取10个样本来求和跟新

相对于随机梯度下降算法,小批量梯度下降算法降低了收敛波动性, 即降低了参数更新的方差,使得更新更加稳定。相对于全量梯度下降, 其提高了每次学习的速度。并且其不用担心内存瓶颈从而可以利用矩阵运算进行高效计算。
一般情况下,小批量梯度下降是梯度下降的推荐变体,特别是在深度学习中。每次随机选择2的幂数个样本来进行学习,例如:8、16、32、 64、128、256。因为计算机的结构就是二进制的。但是也要根据具体问题而选择,实践中可以进行多次试验, 选择一个更新速度与更次次 数都较适合的样本数。
















 1300
1300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









