







目录
一.线性回归的基本概念:
线性回归是机器学习中有监督机器学习下的一种算法。 回归问题主要关注的是因变量(需要预测的值y,可以是一个y也可以是多个y)和一个或多个数值型的自变量x(预测变量)之间的关系。也就是初中学的一元一次方程,但是这里的x和y可以有多个
二.简单的线性回归:
也就是初中学的一元一次方程y=kx+b ,但是在机器学习里面习惯将k写称w,也解说y=wk+b,初中都学过y为因变量也就是我们要预测的值,x是自变量我们获得的数据,b为截距,
而简单的线性回归就是一个自变量对应一个因变量,我们都知道这个函数画出来是一条线,那么为什么叫线性回归呢,回归的概念是:回归分析是通过规定因变量y和自变量x来确定变量之间的因果关系,建立回归模型(这里的回归模型就是y=wx+b),并根据实测数据来求解模型的各个参数,然后评价回归模型是否能够很好的拟合实测数据;如果能够很好的拟合,则可以根据自变量作进一步预测y。
三.最优解:
真实值:y
预测值:y(这里是的y后面会说)
误差:真实值和预测值的差距
最优解:尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失 Loss
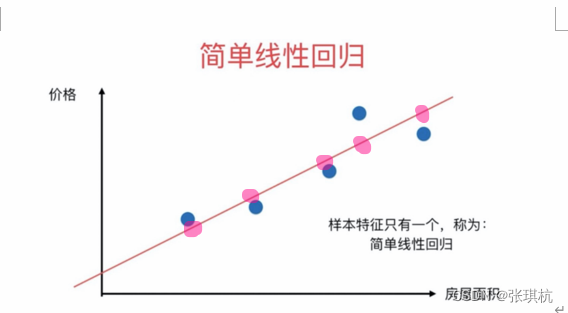
如下图,我们假设下面图中的线是y=2x+3我们的真实值就是图上的点(蓝色),预测值就是当x相同时对应的线上的点(粉红色),总体误差就是真实值减去预测值的绝对值求和
我们要做的就是找到一个模型y=wx+b使得Loss最小
四.多元线性回归:
多元,顾名思义就是多个自变量x来预测,公式就变成了y=w1x1+w2x2+….wnxn+b,在机器学习里面大佬喜欢将b写成w0
学过线性代数的都知道x1,x2,……xn可以用一维向量表示记作大写的X,w写成W公式就变成了y=W的转置乘X,转置不知道的要去学一下线性代数
五.正规方程:
最小二乘法表示:最小二乘法概率论里的知识,没学过的朋友可以去看看,不需要将概率论全部学一便。最小二乘法可以将误差方程转化为有确定解的代数方程组(其方程式数目正好等于未知数的个数),从而可求解出这些未知参数。这个 有确定解的代数方程组称为最小二乘法估计的正规方程。公式如下:
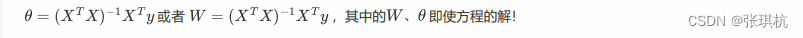
六.最小二乘法公式推导:
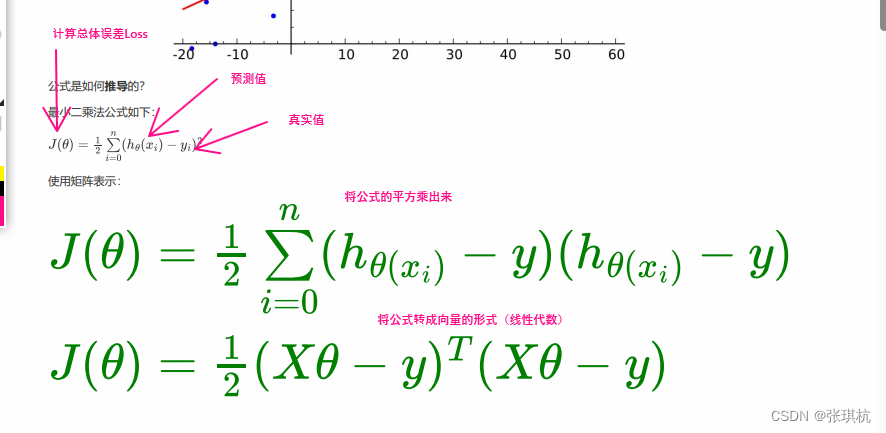

至此公式推导完毕,公式中求出来的theta就是W变量(w1,w2,w3....wn)最优解的时候我们说要找到一个Loss最小情况下的模型,我们可以用最小二乘法来总误差最小的情况下的W变量(w1,w2,w3....wn)在加上我们以知数据X变量(x1,x2,x3....xn)
就得到了多元线性模型y=w1x1+w2x2+w3x3......wnxn

七. 凸函数:
在初中我们知道二次函数开口向上的叫凹函数,开口向下的叫凸函数,但是在我们机器学习中,同一叫凸函数。因为不论开口向上还是向下我们都可我们求的极值一定是最大的。判定损失函数是凸函数的好处在于我们可能很肯定的知道我们求得的极值即最优解,一定是全局最优解。
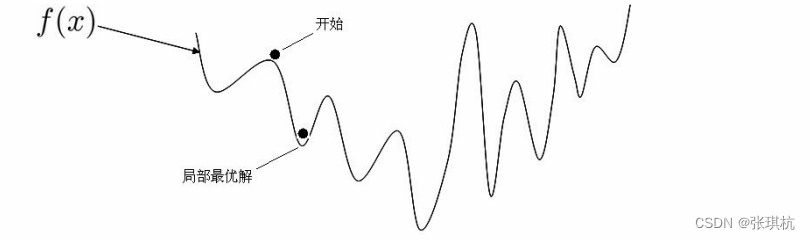
如果不是凸函数,我们求的极值可能是局部最优解,如图:
我们在做模型的时候也不可能画图,那么怎么判断是不是凸函数呢?
判定凸函数的方式: 判定凸函数的方式非常多,其中一个方法是看黑塞矩阵是否是半正定的。 黑塞矩阵(hessian matrix)是由目标函数在点 X(以后大写的X都代表变量也就是(x1,x2,x3....xn)) 处的二阶偏导数组成的对称矩阵。 对于我们的式子来说就是在导函数的基础上再次对θ来求偏导,结果就是X 的转置乘上X。所谓正定就是X 的转置乘上X的特征值全为正数,半正定就是 X 的转置乘上X的特征值大于等于 0, 就是半正定。如果不知道特征值是什么的朋友去看看线性代数
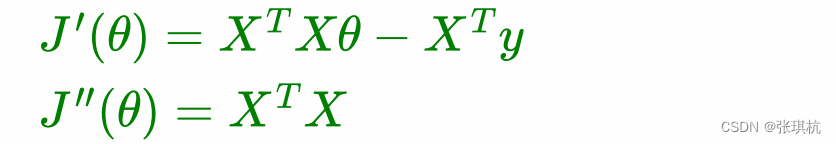
也就是通过最小二乘法求导的时候对 θ来求偏导所得到的这个值、
这里我们对 损失函数求二阶导数的黑塞矩阵是 ,得到的一定是半正定的,自己和自己做点乘嘛! 这里不用数学推导证明这一点。在机器学习中往往损失函数都是凸函数,到深度学习中损失函数往往是非凸函数,即找到的解未必是全局最 优,只要模型堪用就好!机器学习特点是:不强调模型 100% 正确,只要是有价值的,堪用的,就Okay!
八.线性回归算法推导
回归简单来说就是“回归平均值”(regression to the mean)。但是这里的 mean 并不是把 历史数据直接当成未来的预测值,而是会把期 望值当作预测值。 追根溯源回归这个词是一个叫高尔顿的人发明的,他通过大量观察数据发现:父亲比较高,儿子也比较高;父亲比较矮,那 么儿子也比较矮!正所谓“龙生龙凤生凤老鼠的儿子会打洞”!但是会存在一定偏差~
这里不就得说说正态分布了(概率论里的知识,不需要把概率论都学一遍)
某一个样本的误差等于这个样本的真实值减去预测值的绝对值,因为误差没有负数因为预测的多了一点或者少了一点,都是和真实值的距离有多大,而距离没有负数。对于所有样本的误差:假定所有的样本的误差都是独立的,有上下的震荡,震荡认为是随机变量,足够多的随机变量叠加之后形成的分布,它服从的就是正态 分布,因为它是正常状态下的分布,也就是高斯分布!均值是某一个值,方差是某一个值。 方差我们先不管,均值我们总有办法让它去等于 零 0 的,因为我们这里是有截距b, 所有误差我们就可以认为是独立分布的,1<=i<=n,服从均值为 0,方差为某定值的高斯分布。机器学习 中我们假设误差符合均值为0,方差为定值的正态分布!!!画成图的就是:
最大似然估计(概率论):
最大似然估计(maximum likelihood estimation, MLE)一种重要而普遍的求估计量的方法。最大似然估计明确地使用概率模型,其目标 是寻找能够以较高概率产生观察数据的系统发生树。最大似然估计是一类完全基于统计的系统发生树重建方法的代表。 是不是,有点看不懂,太学术了,我们举例说明~ 假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,但我们不能 把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过 程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占 的比例最有可能是多少?
很多小伙伴,甚至不用算,凭感觉,就能给出答案:70%! 下面是详细推导过程: 最大似然估计,计算 白球概率是p,黑球是1-p(罐子中非黑即白) 罐子中取一个请问是白球的概率是多少? 罐子中取两个球,两个球都是白色,概率是多少? 罐子中取5个球都是白色,概率是多少? 罐子中取10个球,9个是白色,一个是黑色,概率是多少呢?

正太分布-概率密度函数 :
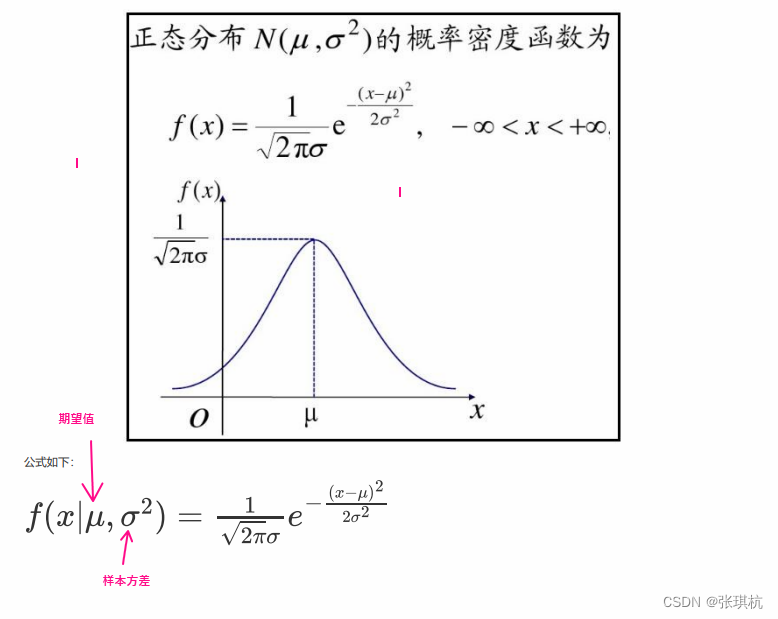
随着参数μ和σ变化,概率分布也产生变化。 下面重要的步骤来了,我们要把一组数据误差出现的总似然,也就是一组数据之所以对应误差出 现的整体可能性表达出来了,因为数据的误差我们假设服从一个高斯分布,并且通过截距项来平移整体分布的位置从而使得μ=0,所以样本 的误差我们可以表达其概率密度函数的值如下:

现在问题我们要求W变量,就变换成了,求最大似然问题了!不过,等等~ 累乘的最大似然,求解是非常麻烦的! 接下来,我们通过,求对数把累乘问题,转变为累加问题(加法问题,无论多复杂,都难不倒我了!)


其实都是概率论的知识


















 4176
4176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









