







目录
2.RelativeMultiHeadAttention 类
这里的代码来自:Transformer XL,这里对代码做了详细解释
一、相对位置编码概述
相对位置编码(Relative Position Encoding)是Transformer模型中用于捕捉序列元素间相对位置关系的一种方法,与绝对位置编码(如BERT中的固定位置嵌入)不同,它直接建模元素之间的相对距离,从而更灵活地处理长序列或不同长度的序列。以下是详细解释:
1. 为什么需要相对位置编码?
- 绝对位置编码的局限:传统Transformer使用正弦/余弦函数或可学习的绝对位置嵌入,为每个位置分配固定编码。但这种方式无法直接建模元素间的相对关系(例如距离为2的两个词的关系)。
- 相对位置的优势:自然语言中,词语的语义常依赖相对位置(如"相邻"或"距离为3"),相对位置编码能更直接地捕捉这种关系。
2. 核心思想
相对位置编码通过以下方式改进注意力机制:
- 键-值分离:在计算注意力权重时,不仅考虑内容的匹配(Query和Key的点积),还显式加入相对位置的影响。
- 距离敏感:相对位置的权重随距离增大而衰减,符合语言中局部依赖更强的特性。
3. 公式
在论文《Self-Attention with Relative Position Representations》中,作者提出:
- 相对位置嵌入矩阵:定义一个可学习的矩阵 P∈R(2k+1)×d,其中 k 是最大相对距离(如窗口大小),d 是维度。
- 修改注意力计算:
- 绝对注意力:
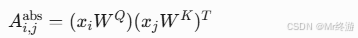
- 加入相对位置:
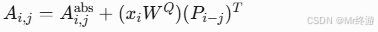
- 其中 Pi−j 是从 P 中查到的相对位置嵌入(若 ∣i−j∣>k,则截断)。
- 绝对注意力:
4. Transformer-XL 的改进
在《Transformer-XL》中,作者进一步优化:
- 相对位置嵌入与内容解耦:将位置信息分离,避免与内容混淆:
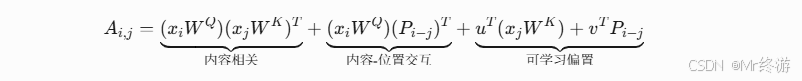
- u,v 是可学习参数,分别捕捉内容无关的位置偏置。
| 方法 | 公式 |
|---|---|
| 绝对位置编码 | |
| Shaw相对位置 | |
| Transformer-XL |
二、代码实现:
1、shift_right函数
1. 功能说明
- 输入:任意维度的张量
x,但要求至少是 2D 的(例如形状[B, C, H, W],常见于图像数据)。 - 输出:将
x的第 1 维(dim=1)的数据向右平移一位,最左侧补零,最右侧的数据被丢弃。 - 效果举例:
- 若输入是
[[1, 2, 3], [4, 5, 6]](形状[2, 3]),输出为[[0, 1, 2], [0, 4, 5]]。
- 若输入是
2. 代码逐行解析
(1) 补零列
zero_pad = x.new_zeros(x.shape[0], 1, *x.shape[2:])
x_padded = torch.cat([x, zero_pad], dim=1)-
zero_pad:创建一个全零张量,形状与x的第 0 维和其他维度相同,但第 1 维是 1(即一列零)。- 例如,若
x形状为[B, C, H, W],则zero_pad形状为[B, 1, H, W]。
- 例如,若
-
torch.cat:将zero_pad拼接到x的右侧(沿dim=1),此时x_padded形状变为[B, C+1, H, W]。
(2) 重塑并截断
x_padded = x_padded.view(x.shape[1] + 1, x.shape[0], *x.shape[2:])
x = x_padded[:-1].view_as(x)-
view操作:将x_padded的形状从[B, C+1, ...]重塑为[C+1, B, ...](交换第 0 维和第 1 维)。- 目的是通过后续切片
[:-1]直接丢弃最后一个元素(即原张量的最右侧数据)。
- 目的是通过后续切片
-
view_as:恢复原始形状,完成右移。
假设输入 x 为 2D 张量:
x = torch.tensor([[1, 2, 3],
[4, 5, 6]]) # shape [2, 3]运行后输出:
[[0, 1, 2],
[0, 4, 5]]3.完整代码
# 数据右移函数
def shift_right(x:torch.Tensor): # x.shape=(seq_len,batch_size,heads,d_k)
# 创建一个第一维(从0开始)和x不一样的全为0的tensor
zero_pad = x.new_zeros(x.shape[0], 1, *x.shape[2:]) # shape(seq_len,1,batch_size,heads,d_k)
# inspect(zero_pad)
# 将x和零矩阵按第一维结合
x_padded = torch.cat([x, zero_pad], dim=1) #shape(seq_len,batch_size+1,heads,d_k)
# inspect(x_padded)
x_padded = x_padded.view(x.shape[1] + 1, x.shape[0], *x.shape[2:]) # shape(batch_size+1,seq_len,heads,d_k)
# inspect(x_padded)
x = x_padded[:-1].view_as(x)
return x2.RelativeMultiHeadAttention 类
定义了一个 RelativeMultiHeadAttention 类,继承自标准的 MultiHeadAttention,并引入了相对位置编码机制(Relative Positional Encoding)
1. 核心功能
- 目标:在多头注意力机制中,通过相对位置编码(而非绝对位置)增强模型对序列中元素相对位置的感知能力。
- 适用场景:机器翻译、语音识别等需要建模序列中元素相对位置的任务。
2. 关键组件解析
(1) 初始化参数
super().__init__(heads, d_model, dropout_prob, bias=False)- 继承父类
MultiHeadAttention,但禁用线性变换的偏置(bias=False),因为相对位置编码会显式引入偏置(key_pos_bias和query_pos_bias)。
(2) 相对位置编码参数
-
self.P = 2 ** 12
定义最大相对位置距离(4096),即允许模型处理的最远相对位置偏移量。 -
self.key_pos_embeddings- 形状:
[2P, heads, d_k](d_k = d_model // heads)。 - 作用:为每个头(
heads)和每个可能的相对位置(从-P到P)学习独立的嵌入向量。 - 例如,若
P=2,则编码范围为[-2, -1, 0, 1, 2]。
- 形状:
-
self.key_pos_bias- 形状:
[2P, heads]。 - 作用:为每个头和相对位置学习偏置项,增强位置感知。
- 形状:
-
self.query_pos_bias- 形状:
[heads, d_k]。 - 作用:与查询位置无关的全局偏置,用于调整查询向量的表示。
- 形状:
3. 相对位置编码的原理
(1) 相对位置的作用
- 在计算注意力分数时,不仅考虑键(Key)和查询(Query)的内容相似性,还考虑它们的相对位置距离。
- 例如,在句子中,距离较近的词对通常比距离远的词对更相关。
(2) 实现方式
- 键的相对位置嵌入:
对每个键位置j和查询位置i,使用key_pos_embeddings[j - i + P]获取嵌入(+P将负偏移映射到正索引)。 - 偏置项:
key_pos_bias和query_pos_bias直接加到注意力分数上,无需与内容交互。
(3) 数学形式
注意力分数计算扩展为:
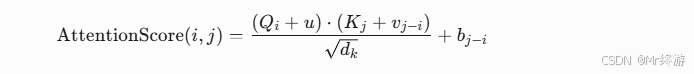
其中:
- u:
query_pos_bias(与位置无关)。 - vj−i:
key_pos_embeddings(相对位置嵌入)。 - bj−i:
key_pos_bias(相对位置偏置)。
4.完整代码
# 重写多头注意力模块
class RelativeMultiHeadAttention(MultiHeadAttention):
def __init__(self,heads,d_model,dropout_prob):
super().__init__(heads,d_model,dropout_prob,bias=False)
# 定义相对位置范围:4090
self.P=2**12
# 为每个头和每个可能的相对位置学习独立的嵌入向量(从-P到P),形状(2*P,heads,d_k)
self.key_pos_embeddings=nn.Parameter(torch.zeros((self.P*2,heads,self.d_k)),requires_grad=True)
# 为每个头和相对位置学习偏置项,增强位置感知(2*P,heads)
self.key_pos_bias=nn.Parameter(torch.zeros((self.P*2,heads)),requires_grad=True)
# 与查询位置无关的全局偏置,用于调整查询向量的表示(heads,d_k)
self.query_pos_bias=nn.Parameter(torch.zeros((heads,self.d_k)),requires_grad=True)
5.getsorce()函数,计算q和k相对位置编码得分
这段代码实现了 RelativeMultiHeadAttention 中的注意力分数计算部分,结合了内容相关性和相对位置信息。
1. 函数功能
- 输入:
query: 形状[seq_len_q, batch, heads, d_k]key: 形状[seq_len_k, batch, heads, d_k]
- 输出:注意力分数矩阵,形状
[seq_len_q, seq_len_k, batch, heads],包含内容与相对位置的综合得分。
2. 关键步骤解析
(1) 获取相对位置嵌入和偏置
key_pos_emb = self.key_pos_embeddings[self.P - key.shape[0]:self.P + query.shape[0]]
key_pos_bias = self.key_pos_bias[self.P - key.shape[0]:self.P + query.shape[0]]-
key_pos_embeddings:从预定义的相对位置嵌入矩阵中切片,选取与当前序列长度相关的部分。- 切片范围
[P - seq_len_k : P + seq_len_q],覆盖所有可能的相对位置偏移(从-seq_len_k到seq_len_q)。 - 形状:
[seq_len_q + seq_len_k, heads, d_k]
- 切片范围
-
key_pos_bias:同理切片相对位置偏置,形状[seq_len_q + seq_len_k, heads]。
(2) 查询位置偏置
query_pos_bias = self.query_pos_bias[None, None, :, :]- 扩展全局查询偏置
query_pos_bias的维度,形状从[heads, d_k]变为[1, 1, heads, d_k],便于广播。
(3) 计算内容相关分数 (ac)
ac = torch.einsum('ibhd,jbhd->ijbh', query + query_pos_bias, key)- 公式:
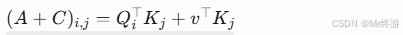
query + query_pos_bias:将查询向量与全局偏置结合(v对应query_pos_bias)。einsum计算查询和键的点积,生成基础注意力分数矩阵,形状[seq_len_q, seq_len_k, batch, heads]。
(4) 计算相对位置相关分数 (b 和 d)
b = torch.einsum('ibhd,jhd->ijbh', query, key_pos_emb)
d = key_pos_bias[None, :, None, :]-
b(公式 $ B'_{i,k} = Q_i^\top R_k \):- 计算查询与相对位置嵌入的点积,形状
[seq_len_q, seq_len_q + seq_len_k, batch, heads]。
- 计算查询与相对位置嵌入的点积,形状
-
d(公式 ( D'_{i,k} = S_k \):- 直接扩展相对位置偏置的维度,形状
[1, seq_len_q + seq_len_k, 1, heads]。
- 直接扩展相对位置偏置的维度,形状
(5) 合并相对位置分数 (bd)
bd = shift_right(b + d)
bd = bd[:, -key.shape[0]:]-
shift_right:将b + d的矩阵右移一位(参考前文的shift_right函数),使得第k列对应相对偏移i-j = k。 - 切片:保留最后
seq_len_k列,确保输出形状与ac一致[seq_len_q, seq_len_k, batch, heads]。
(6) 最终分数
return ac + bd- 公式:( \text{Score}{i,j} = A{i,j} + B_{i,j} + C_{i,j} + D_{i,j} $
ac:内容相关性 + 全局查询偏置。bd:相对位置相关性 + 相对位置偏置。
3.完整代码
# 计算相对位置注意力得分矩阵
def get_scores(self,query,key):
# 从预定义的相对位置矩阵中切片,获取与当前位置相关的部分,[P - seq_len_k : P + seq_len_q]
key_pos_emb=self.key_pos_embeddings[self.P-key.shape[0]:self.P+query[0]]
# 从预定义的相对位置偏置中获取与当前位置相关的部分,[P-seq_len_k, P+seq_len_q]
key_pos_bias=self.key_pos_bias[self.P-key.shape[0]:self.P+query.shape[0]]
# 扩展全局偏置的维度,从(heads,d_k)->(1,1,heads,d_k)
query_pos_bias=self.query_pos_bias[None,None,:,:]
# 计算内容相关分数,使用查询向量加上全局偏置与键向量点积,生成基础注意力分数矩阵
ac=torch.einsum('ibhd,jbhd->ijbh',query+query_pos_bias,key)
# 计算查询与相对位置的点积
b=torch.einsum('ibhd,jhd->ijbh',query,key_pos_emb)
# 扩展相对位置维度,(1,seq_len_q+seq_len_k,1,heads)
d=key_pos_bias[None,:,None,:]
# 将b和d相加得到相对位置分数,传入shift_right中使数据向右移一位,获得每个词的在规定范围(P)中的前后词的相对位置分数
bd=shift_right(b+d)
# 将seq_len_q切去,保留seq_len_k部分,保证与ac一致。(seq_len_q,seq_len_k,heads,d_k)
bd=bd[:,-key.shape[0]:]
# 将内容相关分数与位置相关分数相加得到相对位置注意力
return ac+bd三、完整代码带测试
# 导入相关包
import torch
import torch.nn as nn
# inspect:打印数据的一个函数
from labml.logger import inspect
# 导入多头注意力模块
from labml_nn.transformers import MultiHeadAttention
# 数据右移函数
def shift_right(x:torch.Tensor): # x.shape=(seq_len,batch_size,heads,d_k)
# 创建一个第一维(从0开始)和x不一样的全为0的tensor
zero_pad = x.new_zeros(x.shape[0], 1, *x.shape[2:]) # shape(seq_len,1,batch_size,heads,d_k)
# inspect(zero_pad)
# 将x和零矩阵按第一维结合
x_padded = torch.cat([x, zero_pad], dim=1) #shape(seq_len,batch_size+1,heads,d_k)
# inspect(x_padded)
x_padded = x_padded.view(x.shape[1] + 1, x.shape[0], *x.shape[2:]) # shape(batch_size+1,seq_len,heads,d_k)
# inspect(x_padded)
x = x_padded[:-1].view_as(x)
return x
# 重写多头注意力模块
class RelativeMultiHeadAttention(MultiHeadAttention):
def __init__(self,heads,d_model,dropout_prob):
super().__init__(heads,d_model,dropout_prob,bias=False)
# 定义相对位置范围:4090
self.P=2**12
# 为每个头和每个可能的相对位置学习独立的嵌入向量(从-P到P),形状(2*P,heads,d_k)
self.key_pos_embeddings=nn.Parameter(torch.zeros((self.P*2,heads,self.d_k)),requires_grad=True)
# 为每个头和相对位置学习偏置项,增强位置感知(2*P,heads)
self.key_pos_bias=nn.Parameter(torch.zeros((self.P*2,heads)),requires_grad=True)
# 与查询位置无关的全局偏置,用于调整查询向量的表示(heads,d_k)
self.query_pos_bias=nn.Parameter(torch.zeros((heads,self.d_k)),requires_grad=True)
# 计算相对位置注意力得分矩阵
def get_scores(self,query,key):
# 从预定义的相对位置矩阵中切片,获取与当前位置相关的部分,[P - seq_len_k : P + seq_len_q]
key_pos_emb=self.key_pos_embeddings[self.P-key.shape[0]:self.P+query[0]]
# 从预定义的相对位置偏置中获取与当前位置相关的部分,[P-seq_len_k, P+seq_len_q]
key_pos_bias=self.key_pos_bias[self.P-key.shape[0]:self.P+query.shape[0]]
# 扩展全局偏置的维度,从(heads,d_k)->(1,1,heads,d_k)
query_pos_bias=self.query_pos_bias[None,None,:,:]
# 计算内容相关分数,使用查询向量加上全局偏置与键向量点积,生成基础注意力分数矩阵
ac=torch.einsum('ibhd,jbhd->ijbh',query+query_pos_bias,key)
# 计算查询与相对位置的点积
b=torch.einsum('ibhd,jhd->ijbh',query,key_pos_emb)
# 扩展相对位置维度,(1,seq_len_q+seq_len_k,1,heads)
d=key_pos_bias[None,:,None,:]
# 将b和d相加得到相对位置分数,传入shift_right中使数据向右移一位,获得每个词的在规定范围(P)中的前后词的相对位置分数
bd=shift_right(b+d)
# 将seq_len_q切去,保留seq_len_k部分,保证与ac一致。(seq_len_q,seq_len_k,heads,d_k)
bd=bd[:,-key.shape[0]:]
# 将内容相关分数与位置相关分数相加得到相对位置注意力
"""
总结:
1.通过公式,我们要计算先准备好三个参数:一个相对位置学习嵌入向量,一个相对位置学习篇偏置,一个全局偏置
2.获取每个batch_size中的相对位置、偏置、全局偏置,
3.通过公式:先将q与全局偏置相加后与k点积,得到内容相关分数
4.计算位置注意力分数,
5.将位置注意力分数和内容相关分数相加得到相对位置注意力分数
"""
return ac+bd
def _test_shift_right():
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
inspect(x)
inspect(shift_right(x))
x = torch.arange(1, 6)[None, :, None, None].repeat(5, 1, 1, 1)
inspect(x[:, :, 0, 0])
inspect(shift_right(x)[:, :, 0, 0])
x = torch.arange(1, 6)[None, :, None, None].repeat(3, 1, 1, 1)
inspect(x[:, :, 0, 0])
inspect(shift_right(x)[:, :, 0, 0])
if __name__ == '__main__':
_test_shift_right()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









