







有n个机器零件{J1,J2,…,Jn},每个零件必须先由机器1处理,再由机器2处理。零件Ji需要机器1、机器2的处理时间为t1i、t2i。如何安排零件加工顺序,使第一个零件从机器1上加工开始到最后一个零件在机器2上加工完成,所需的总加工时间最短?
根据问题描述,不同加工顺序,加工完所有零件所需的时间不同。
例如:现在有3个机器零件{J1,J2,J3},在第一台机器上的加工时间分别为2、5、4,在第二台机器上的加工时间分别为3、1、6。
(1)如果按照{J1,J2,J3}的顺序加工,如图所示。

(2)如果按照{J1,J3,J2}的顺序加工,如图所示。

可以看出一个有趣的现象:第一台机器可以连续加工,而第二台机器开始加工的时间是当前第一台机器的下线时间和第二台机器下线时间的最大值。就是图中连线的两个数值中的最大值。
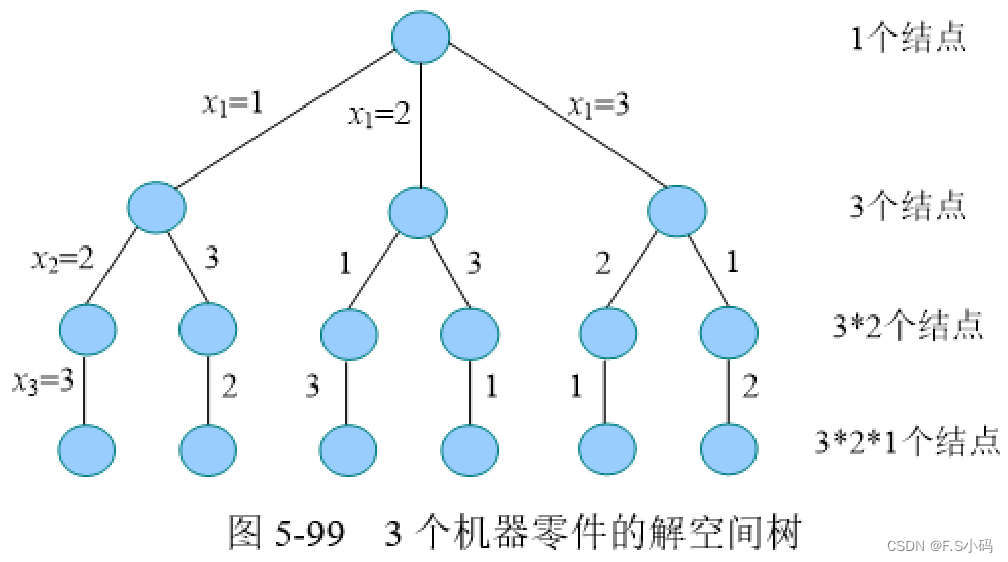
3个机器零件有多少种加工顺序呢? 即3个机器零件的全排列,共有6种:
1 2 3
1 3 2
2 1 3
2 3 1
3 2 1
3 1 2
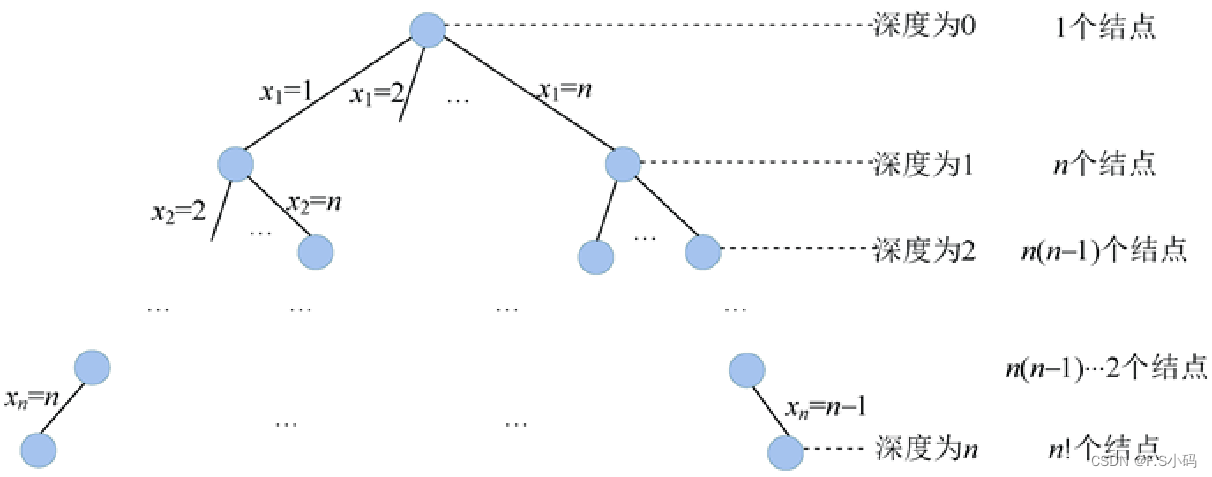
最优加工顺序问题实际上就是找到n个机器零件的一个排列,使总加工时间最短。n个机器零件一共有n!种排列顺序,每一个排列都是一个可行解。解空间是一棵排列树。
如何得到这n个机器零件的排列呢?(见《趣学算法》附录G)。
(1)定义问题的解空间
机器零件加工问题解的形式为n元组:{x1,x2,…,xi,…,xn}。分量xi表示第i个加工的零件号,n个零件组成的集合为S={1,2,…,n},xi的取值为S−{x1,x2,…,xi−1},i=1,2,…,n。
(2)解空间的组织结构
机器零件加工问题解空间是一棵排列树,树的深度为n。
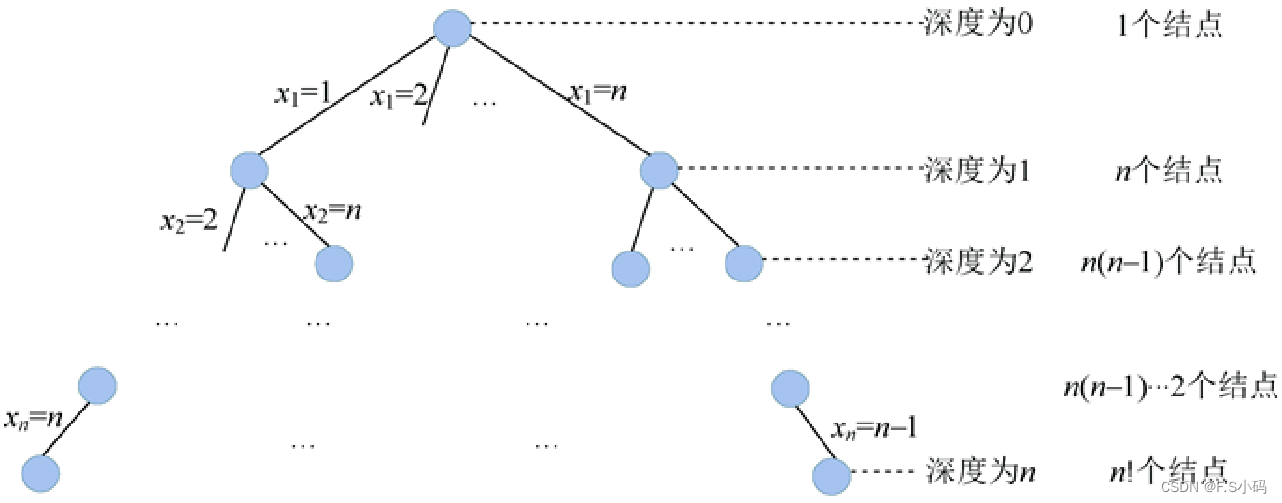
(3)搜索解空间
· 约束条件
任何一种零件加工次序不存在无法调度的情况,不需要约束条件。
· 限界条件
f2表示当前已完成的零件在第二台机器加工结束所用的时间,bestf 表示当前找到的最优加工方案的完成时间。显然,继续向深处搜索时,f2只会增加不会减少。因此,当f2≥bestf时,没有继续向深处搜索的必要。限界条件可描述为:f2<bestf,f2的初值为0,bestf的初值为无穷大。
· 搜索过程
扩展结点沿着某个分支扩展时需要判断限界条件,如果满足,则进入深一层继续搜索;如果不满足,则剪掉该分支。搜索到叶子结点时,即找到当前最优解。搜索直到全部的活结点变成死结点为止。
现在有3个机器零件{J1,J2,J3},在第一台机器上的加工时间分别为2,5,4,在第二台机器上的加工时间分别为3,1,6。求最优加工顺序。

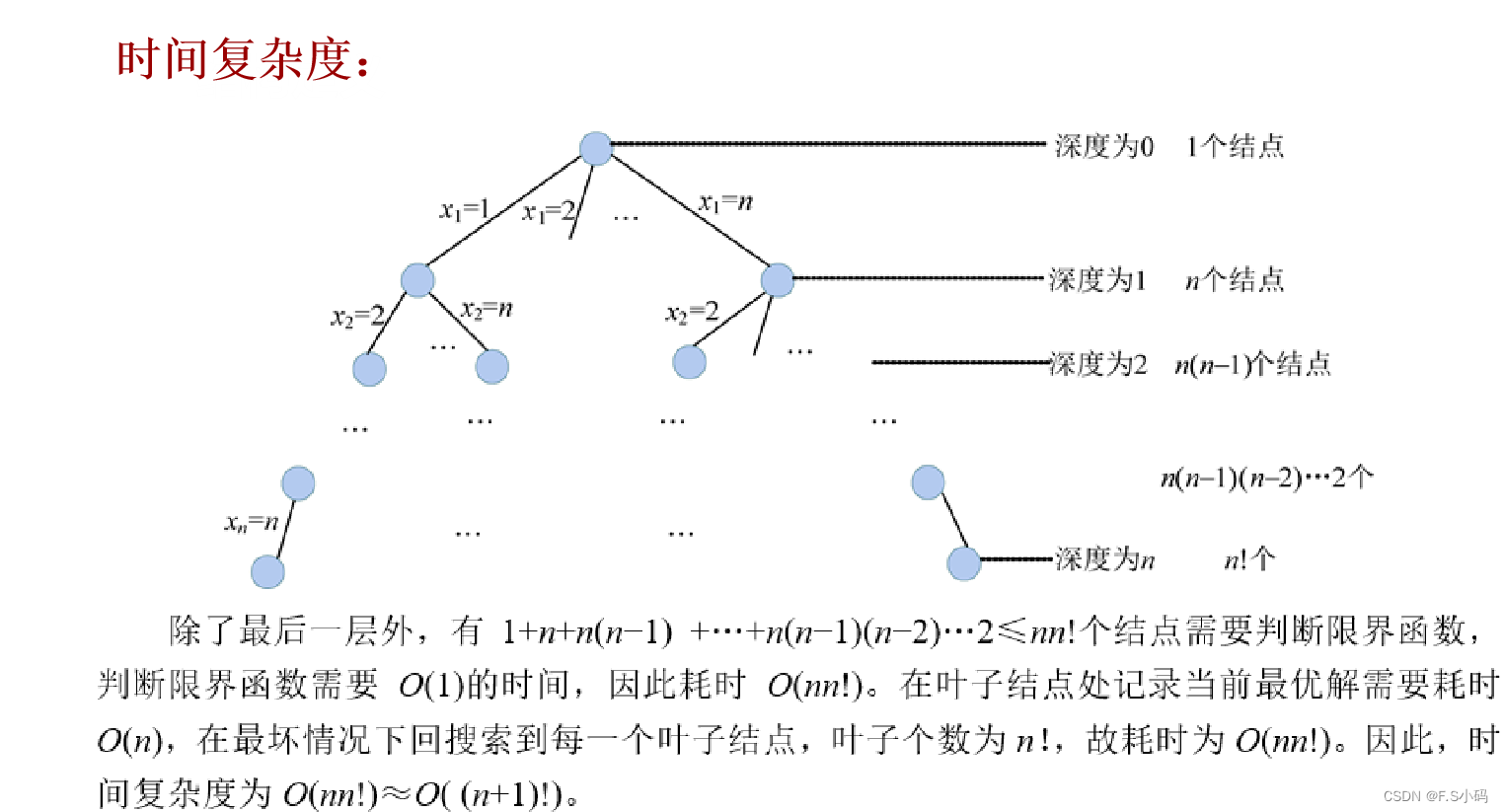
空间复杂度:
程序中使用x[]数组记录可行解,空间复杂度为O(n)。
算法优化拓展:
使用贝尔曼规则进行优化,算法时间复杂度提高到O(nlogn)。(见《趣学算法》附录H)
//program 5.6 机器零件加工顺序
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn=105;
const int inf=0x3f3f3f3f;
int n,bestf,f1,f2;//f1在第一台机器上加工的完成时间,f2在第二台机器上加工的完成时间
int x[maxn],bestx[maxn]; //x[i]表示第i个皇后放置在第i行第x[i]列
struct node{
int x,y;//机器零件在第一台机器上的加工时间x和第二台机器上的加工时间y
}T[maxn];
void backtrack(int t){
if(t>n){
for(int i=1;i<=n;i++) //记录最优解
bestx[i]=x[i];
bestf=f2; //记录最优值
return ;
}
for(int i=t;i<=n;i++){//排列树
f1+=T[x[i]].x;
int temp=f2;
f2=max(f1,f2)+T[x[i]].y;
if(f2<bestf){ //限界条件
swap(x[t],x[i]); //交换
backtrack(t+1); //继续深搜
swap(x[t],x[i]); //还原现场,复位反操作
}
f1-=T[x[i]].x;//还原现场
f2=temp;
}
}
void print(){
cout<<"最优机器零件加工顺序:";
for(int i=1;i<=n;i++) //输出最优加工顺序
cout<<bestx[i]<<" ";
cout<<endl;
}
int main(){
int t;//测试用例数
cin>>t;
while(t--){
cin>>n;
for(int i=1;i<=n;i++){
cin>>T[i].x>>T[i].y;
x[i]=i;
}
bestf=inf; //初始化为无穷大
f1=f2=0;
memset(bestx,0,sizeof(bestx));
backtrack(1); // 深搜排列树
cout<<bestf<<endl;
//print();
}
return 0 ;
}
/*测试数据
2
6
5 7
1 2
8 2
5 4
3 7
4 4
7
3 7
8 2
10 6
12 18
6 3
9 10
15 4
*///program 5-6-2
#include<iostream>
#include<algorithm>
using namespace std;
const int MX=10000+5;
int n;
struct node{
int id;
int x,y;
}T[MX];
bool cmp(node a,node b){
return min(b.x,a.y)>=min(b.y,a.x);//按照贝尔曼规则排序
}
int main(){
cout<<"请输入机器零件的个数 n:";
cin>>n;
cout<<"请依次输入每个机器零件在第一台机器上的加工时间x和第二台机器上的加工时间y:";
for(int i=0;i<n;i++){
cin>>T[i].x>>T[i].y;
T[i].id=i+1;
}
sort(T,T+n,cmp);//排序
int f1=0,f2=0;
for(int i=0;i<n;i++){ //计算总时间
f1+=T[i].x;
f2=max(f1,f2)+T[i].y;
}
cout<<"最优的机器零件加工顺序为:";
for(int i=0;i<n;i++) //输出最优加工顺序
cout<<T[i].id<<" ";
cout<<endl;
cout<<"最优的机器零件加工的时间为:";
cout<<f2<<endl;
return 0;
}
/*测试数据
6
5 7
1 2
8 2
5 4
3 7
4 4
*/
















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









