






https://blog.csdn.net/m0_73477762/article/details/144848785?spm=1001.2014.3001.5502
五、数据集划分
5.1 数据处理
(1)标签:satisfaction_level 对公司的满意度、last_evaluation 绩效评估、number_project参加过的项目、average_montly_hours 平均每月工作的时长、time_spend_company 工作年限、Work_accident 是否发生过工作差错、promotion_last_5years 五年内是否升职、salary 薪资水平
预测目标:left,离职情况
#(6)获取特征
X = train_data.drop('left', axis=1) # 'left' 是目标变量的列名
#(7)获取标签
y = train_data['left']
#(8)对标签y进行类型转换为numpy
y = y.to_numpy()
#(9)将标签y进行形状修改为1列
y = y.reshape(-1, 1)(2)对原始数据进行缩放(对数据进行标注化)
标准化的原因就是统一量纲。
transform方法会根据之前拟合得到的均值和标准差,将数据进行标准化处理。标准化的公式为:,其中x是原始数据
是该特征的均值,
是该特征的标准差。
这样,经过缩放后,X中的数据就都被标准化到了均值为 0,标准差为 1 的分布。
#(10)对原始特征数据进行缩放
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)(3)降维(PCA降维)
PCA降维(主成分分析):它的基本思想是通过线性变换将原始数据投影到一个新的低维空间中,同时尽可能保留原始数据的方差信息。
- 具体来说,PCA会寻找数据中方差最大的方向作为新的坐标轴(主成分)。第一个主成分是数据中方差最大的方向,第二个主成分是与第一个主成分正交(垂直)且方差第二大的方向,以此类推。通过选择前几个主成分,可以将原始高维数据转换为低维数据。
- 从数学角度看,PCA是通过对数据的协方差矩阵进行特征值分解来实现的。协方差矩阵的特征向量就是主成分的方向,特征值表示相应主成分的方差大小。
降维的原因:
- 降低计算成本:在处理高维数据时,计算量会随着维度的增加而急剧增加。例如,在一些机器学习算法(如 K - 近邻算法)中,计算样本之间的距离需要考虑所有维度,维度越高,计算复杂度越大。通过降维,可以减少数据的维度,从而降低计算成本,提高算法的运行效率。
- 缓解维度灾难:当维度很高时,数据变得非常稀疏,并且在高维空间中,样本之间的距离可能变得难以区分,这被称为维度灾难。降维可以将数据压缩到一个更合理的低维空间,使得数据在这个空间中的分布更加紧凑,有利于模型的学习和泛化。
- 去除噪声和冗余信息:原始数据中可能包含一些噪声或者冗余的特征。通过降维,可以在一定程度上过滤掉这些噪声,同时保留数据中最主要的信息。例如,某些特征之间可能存在很强的相关性,PCA 可以将这些相关特征合并为一个主成分,从而减少数据的冗余。
#(11)对原始数据进行使用降维技术进行降维(维度数自己选择)
#PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 选择一个合适的维度数
X_pca = pca.fit_transform(X_scaled)
(4)数据集划分
#(12)划分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_pca, y, test_size=0.2, random_state=42)数据集划分为训练集和测试集,训练集:测试集=4:1
五、模型选择及训练
5.1 逻辑回归模型
- 基本原理
- 逻辑回归是一种用于分类问题的广义线性模型。它的基本假设是,数据服从伯努利分布(对于二分类问题),即目标变量只有两种可能的取值(例如 0 和 1)。
- 逻辑回归通过一个逻辑函数(通常是 sigmoid 函数)将线性组合的输入特征转换为概率值。
- sigmoid 函数的表达式为
,其中,
是模型的
权重参数,
是输入特征,p是预测为正类(例如类别 1)的概率。
- 模型的训练过程是通过最大化似然函数(或最小化负对数似然函数)来估计最佳的权重参数
- 优点
- 简单易懂,模型的解释性强。逻辑回归的参数具有明确的含义,可以直观地理解每个特征对分类结果的影响程度(通过权重的大小和正负)。
- 计算效率高。训练和预测过程相对简单,不需要复杂的计算,能够快速处理大规模的数据。
- 对于线性可分的数据能够取得较好的效果,并且在数据经过适当的特征工程后,也能对一些非线性问题有一定的处理能力。
- 缺点
- 假设数据是线性可分的,对于复杂的非线性数据,其分类效果可能不佳。需要通过引入多项式特征等方式来处理非线性问题,这可能会增加模型的复杂度。
- 容易受到多重共线性(特征之间高度相关)的影响。当存在多重共线性时,模型的估计参数会变得不稳定,影响模型的准确性和解释性。
- 应用场景
- 广泛应用于二分类问题,如信用风险评估(判断客户是否会违约)、疾病诊断(判断患者是否患病)、营销中的客户响应预测(判断客户是否会对营销活动做出响应)等。也可以通过一对多(One - vs - Rest)或一对一(One - vs - One)的策略扩展到多分类问题。
# 逻辑回归模型
from sklearn.linear_model import LogisticRegression
import joblib
#初始化逻辑回归模型
logistic_model=LogisticRegression()
#逻辑回归训练模型
logistic_model.fit(X_train,y_train)
joblib.dump(logistic_model,'logistic_model.pkl')5.2 随机森林
- 基本原理
- 随机森林是一种基于决策树的集成学习算法。它由多个决策树组成,每个决策树是一个独立的分类器。
- 构建决策树时,首先从训练数据中有放回地随机抽取样本(这称为自助采样,Bootstrapping),构建多个不同的训练数据集。然后,对于每个决策树,在构建节点分裂规则时,从所有特征中随机选择一部分特征(通常是
个特征,m是总特征数)来寻找最佳分裂点。这样可以降低决策树之间的相关性,提高模型的泛化能力。
- 当进行预测时,对于分类问题,随机森林通过投票的方式(每个决策树投出自己的分类结果)来确定最终的类别;对于回归问题,则是取所有决策树预测结果的平均值。
- 优点
- 具有很高的准确性和鲁棒性。由于它是由多个决策树组成的集成模型,能够学习到数据中复杂的模式和关系,并且对于噪声和异常值有较强的容忍能力。
- 能够处理高维数据和大量的数据,并且不需要对数据进行复杂的预处理(如归一化等),对数据的分布和缺失值也有一定的适应性。
- 可以提供特征重要性的评估。通过计算每个特征在决策树分裂过程中的贡献程度,可以评估特征的相对重要性,这对于特征选择和理解数据很有帮助。
- 缺点
- 模型的解释性相对较弱。虽然可以评估特征重要性,但由于随机森林是由多个决策树组成的复杂模型,很难像逻辑回归那样直观地解释每个特征是如何影响分类结果的。
- 计算成本较高。由于需要构建多个决策树,在训练过程中需要消耗大量的计算资源和时间,特别是当数据量很大或者树的深度很深时。
- 容易过拟合。虽然通过随机采样和随机特征选择等方法在一定程度上缓解了过拟合问题,但如果参数设置不当(如树的数量过多、树的深度过深等),仍然可能导致过拟合。
- 应用场景
- 适用于各种类型的分类和回归问题,特别是在数据具有复杂的结构和关系、存在噪声和缺失值的情况下。例如,在图像识别、自然语言处理、生物信息学等领域都有广泛的应用。
from sklearn.ensemble import RandomForestClassifier
#初始化随机森林模型
rf_model=RandomForestClassifier()
#随机森林模型训练
rf_model.fit(X_train,y_train)
joblib.dump(logistic_model,'rf_model.pkl')5.3 支持向量机
- 基本原理
- SVM 最初是为二分类问题设计的。它的基本思想是找到一个最优的超平面,将不同类别的数据点尽可能地分开,并且使得两类数据点到这个超平面的最小距离(称为 margin)最大。
- 对于线性可分的数据,这个超平面可以用一个线性方程
来表示,其中
是超平面的法向量,
是输入特征向量,
是偏置项。通过求解一个优化问题(最大化 margin)来确定
- 当数据是非线性可分的时候,SVM 通过核函数(Kernel Function)将原始数据映射到一个高维空间,使得在高维空间中数据变得线性可分。常见的核函数有线性核、多项式核、高斯核(RBF 核)等。例如,高斯核函数的表达式为
,其中
是一个参数,
表示两个样本之间的欧氏距离的平方。
- 优点
- 在处理小样本、高维数据时表现出色。SVM 通过寻找最优超平面,能够有效地利用有限的数据进行学习,并且对于高维数据可以通过核函数进行处理,避免了维度灾难。
- 对于非线性问题有很好的处理能力。通过选择合适的核函数,可以将非线性数据映射到高维空间进行线性分类,能够捕捉到数据中的复杂模式。
- 泛化能力强。SVM 的目标是最大化 margin,这使得它在新数据上的预测能力较强,能够有效避免过拟合。
- 缺点
- 对于大规模数据,训练时间较长。由于 SVM 需要求解复杂的二次规划问题,当数据量很大时,计算复杂度会急剧增加。
- 核函数的选择和参数调整比较困难。不同的核函数和参数设置会对模型的性能产生很大的影响,需要通过交叉验证等方法进行大量的实验来选择合适的核函数和参数。
- 应用场景
- 广泛应用于分类问题,如文本分类、图像分类、生物医学数据分类等。在数据量不是特别大,但对模型的准确性和泛化能力要求较高的场景中表现出色。
from sklearn.svm import SVC
#初始化SVM模型
svm_model=SVC()
#SVM
svm_model.fit(X_train,y_train)
joblib.dump(logistic_model,'SVM_model.pkl')5.3 预测及评估
(1)加载模型并在测试集上进行预测:
#给定测试数据并加载各模型进行预测
import joblib
# 加载逻辑回归模型
logistic_model = joblib.load('logistic_model.pkl')
# 加载随机森林模型
rf_model = joblib.load('rf_model.pkl')
# 加载支持向量机模型
svm_model = joblib.load('svm_model.pkl')
# 使用逻辑回归模型进行预测
y_pred_logistic = logistic_model.predict(X_test)
# 使用随机森林模型进行预测
y_pred_rf = rf_model.predict(X_test)
# 使用支持向量机模型进行预测
y_pred_svm = svm_model.predict(X_test)(2)评价指标及ROC曲线绘制
评价指标:
- 准确率(Accuracy)
- 定义:准确率是指模型正确预测的样本数占总样本数的比例。计算公式为:
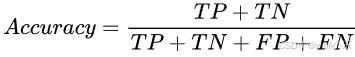 ,其中TP(True Positive)是真正例,即模型正确预测为正类的样本数;TN(True Negative)是真反例,即模型正确预测为反类的样本数;FP(False Positive)是假正例,即模型错误地将反类预测为正类的样本数;FN(False Negative)是假反例,即模型错误地将正类预测为反类的样本数。
,其中TP(True Positive)是真正例,即模型正确预测为正类的样本数;TN(True Negative)是真反例,即模型正确预测为反类的样本数;FP(False Positive)是假正例,即模型错误地将反类预测为正类的样本数;FN(False Negative)是假反例,即模型错误地将正类预测为反类的样本数。 - 意义:准确率是评估模型整体性能的一个直观指标,它能够反映模型在所有预测中正确的比例。例如,准确率为 0.9 表示模型在所有预测中有 90% 是正确的。但是,当数据存在类别不平衡的情况时,准确率可能会产生误导。例如,在一个数据集中正类样本占 99%,即使模型总是预测为正类,准确率也能达到很高的值,但实际上模型可能并没有真正学习到如何区分正类和反类。
- 定义:准确率是指模型正确预测的样本数占总样本数的比例。计算公式为:
- 召回率(Recall)
- 定义:召回率也称为查全率,是指模型正确预测为正类的样本数占实际正类样本数的比例。计算公式为:
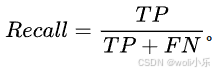 。
。 - 意义:召回率主要关注模型对正类样本的识别能力。例如,在疾病诊断中,召回率表示模型正确诊断出患病患者的比例。高召回率意味着模型能够尽可能多地找出所有正类样本,但是可能会导致较多的假正例,即把一些非正类样本也预测为正类。
- 定义:召回率也称为查全率,是指模型正确预测为正类的样本数占实际正类样本数的比例。计算公式为:
- F1 值(F1 - Score)
- 定义:F1 值是综合考虑了准确率和召回率的一个指标,它是准确率和召回率的调和平均数。计算公式为:
 ,其中
,其中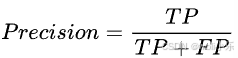 (精确率,表示预测为正类的样本中真正为正类的比例)。
(精确率,表示预测为正类的样本中真正为正类的比例)。 - 意义:当我们希望在准确率和召回率之间取得一个平衡时,F1 值是一个很好的评估指标。例如,在信息检索中,我们既希望检索出的结果尽可能准确(高准确率),又希望尽可能多地检索出相关的内容(高召回率),此时 F1 值能够综合评估模型在这两个方面的性能。F1 值越高,说明模型在准确率和召回率上的综合表现越好。
- 定义:F1 值是综合考虑了准确率和召回率的一个指标,它是准确率和召回率的调和平均数。计算公式为:
# 计算ROC曲线和AUC值
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 假设 X, y 是原始特征和标签数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化模型
logistic_model = LogisticRegression()
rf_model = RandomForestClassifier()
svm_model = SVC(probability=True) # 注意:SVC需要probability=True来启用predict_proba方法
# 训练模型
logistic_model.fit(X_train, y_train)
rf_model.fit(X_train, y_train)
svm_model.fit(X_train, y_train)
# 模型预测
y_pred_logistic = logistic_model.predict(X_test)
y_pred_rf = rf_model.predict(X_test)
y_pred_svm = svm_model.predict(X_test)
# 1. 模型评估
print('逻辑回归模型分类报告:\n', classification_report(y_test, y_pred_logistic))
print('随机森林模型分类报告:\n', classification_report(y_test, y_pred_rf))
print('SVM模型分类报告:\n', classification_report(y_test, y_pred_svm))
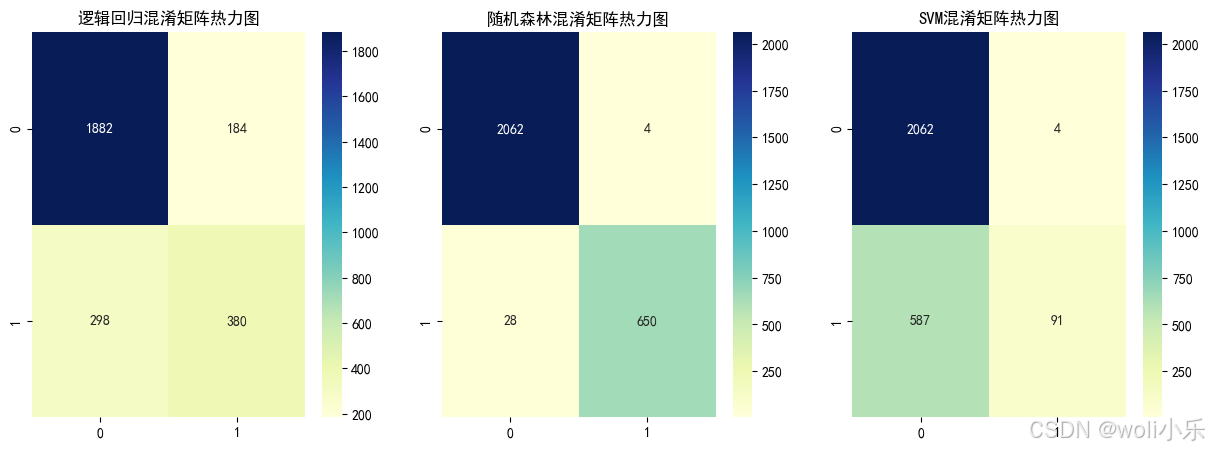
# 2. 混淆矩阵热力图
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.heatmap(confusion_matrix(y_test, y_pred_logistic), annot=True, fmt='d', cmap='YlGnBu')
plt.title('逻辑回归混淆矩阵热力图')
plt.subplot(1, 3, 2)
sns.heatmap(confusion_matrix(y_test, y_pred_rf), annot=True, fmt='d', cmap='YlGnBu')
plt.title('随机森林混淆矩阵热力图')
plt.subplot(1, 3, 3)
sns.heatmap(confusion_matrix(y_test, y_pred_svm), annot=True, fmt='d', cmap='YlGnBu')
plt.title('SVM混淆矩阵热力图')
plt.show()
# 3. ROC曲线绘制
y_prob_logistic = logistic_model.predict_proba(X_test)[:, 1]
y_prob_rf = rf_model.predict_proba(X_test)[:, 1]
y_prob_svm = svm_model.predict_proba(X_test)[:, 1]
fpr_logistic, tpr_logistic, _ = roc_curve(y_test, y_prob_logistic)
roc_auc_logistic = auc(fpr_logistic, tpr_logistic)
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_prob_rf)
roc_auc_rf = auc(fpr_rf, tpr_rf)
fpr_svm, tpr_svm, _ = roc_curve(y_test, y_prob_svm)
roc_auc_svm = auc(fpr_svm, tpr_svm)
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
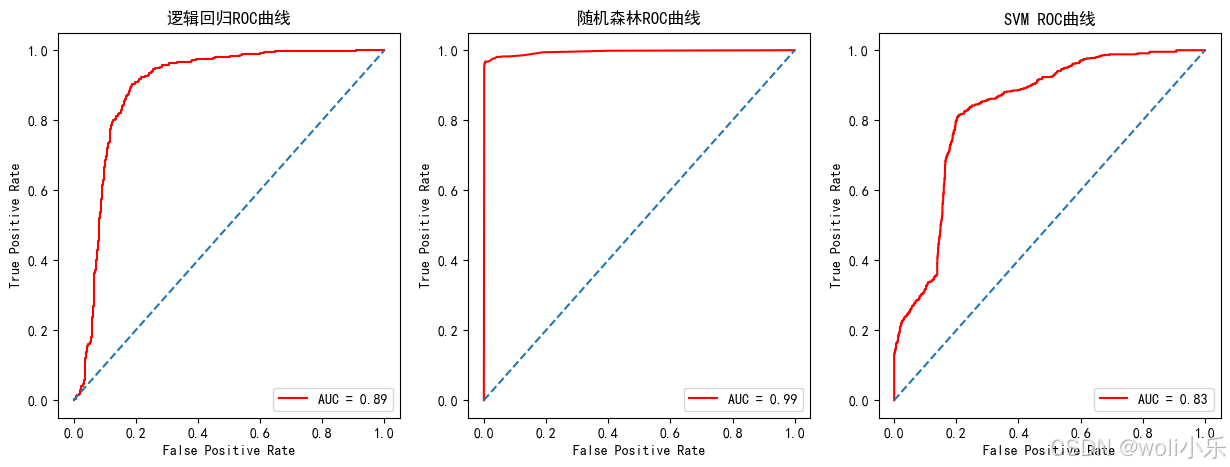
plt.plot(fpr_logistic, tpr_logistic, color='red', label='AUC = {:.2f}'.format(roc_auc_logistic))
plt.plot([0, 1], [0, 1], linestyle='--')
plt.title('逻辑回归ROC曲线')
plt.legend(loc='lower right')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.subplot(1, 3, 2)
plt.plot(fpr_rf, tpr_rf, color='red', label='AUC = {:.2f}'.format(roc_auc_rf))
plt.plot([0, 1], [0, 1], linestyle='--')
plt.title('随机森林ROC曲线')
plt.legend(loc='lower right')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.subplot(1, 3, 3)
plt.plot(fpr_svm, tpr_svm, color='red', label='AUC = {:.2f}'.format(roc_auc_svm))
plt.plot([0, 1], [0, 1], linestyle='--')
plt.title('SVM ROC曲线')
plt.legend(loc='lower right')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
#绘制各模型学习曲线分析
# 3. ROC曲线绘制
y_prob_logistic = logistic_model.predict_proba(X_test)[:, 1]
y_prob_rf = rf_model.predict_proba(X_test)[:, 1]
y_prob_svm = svm_model.predict_proba(X_test)[:, 1]
fpr_logistic, tpr_logistic, _ = roc_curve(y_test, y_prob_logistic)
roc_auc_logistic = auc(fpr_logistic, tpr_logistic)
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_prob_rf)
roc_auc_rf = auc(fpr_rf, tpr_rf)
fpr_svm, tpr_svm, _ = roc_curve(y_test, y_prob_svm)
roc_auc_svm = auc(fpr_svm, tpr_svm)
plt.figure(figsize=(10, 6))
plt.plot(fpr_logistic, tpr_logistic, color='blue', label=f'逻辑回归 (AUC = {roc_auc_logistic:.2f})')
plt.plot(fpr_rf, tpr_rf, color='green', label=f'随机森林 (AUC = {roc_auc_rf:.2f})')
plt.plot(fpr_svm, tpr_svm, color='red', label=f'SVM (AUC = {roc_auc_svm:.2f})')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray')
plt.title('ROC曲线比较')
plt.legend(loc='lower right')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()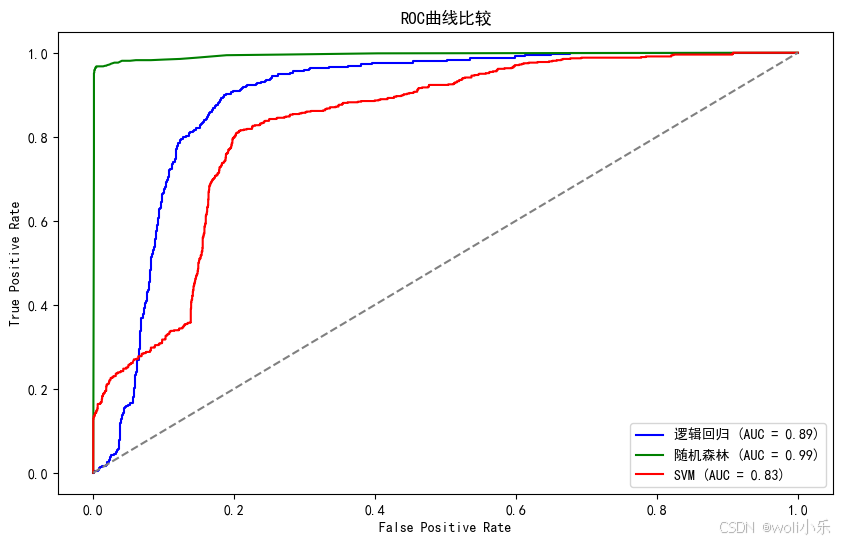
随机森林模型在这三种算法中表现最好,具有非常高的预测能力。逻辑回归模型虽然也具有一定的预测能力,但相对于随机森林来说略逊一筹。而SVM模型的表现则居中,既不如随机森林也不如逻辑回归(在真阳性率相同的情况下,由于其AUC值较低)。因此,在选择分类算法时,可以优先考虑使用随机森林模型。
(2)学习曲线
学习曲线分析通常涉及绘制训练集和验证集的性能(如准确率、损失等)随训练样本数量的变化。 这有助于我们理解模型是否从更多的数据中受益,以及是否存在过拟合或欠拟合的问题。
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.model_selection import learning_curve
# 1. 逻辑回归学习曲线绘制
logistic_model = LogisticRegression()
train_sizes_logistic, train_scores_logistic, test_scores_logistic = learning_curve(logistic_model, X, y, cv=5)
train_scores_mean_logistic = train_scores_logistic.mean(axis=1)
test_scores_mean_logistic = test_scores_logistic.mean(axis=1)
# 2. 随机森林学习曲线绘制
random_forest_model = RandomForestClassifier(n_estimators=100)
train_sizes_rf, train_scores_rf, test_scores_rf = learning_curve(random_forest_model, X, y, cv=5)
train_scores_mean_rf = train_scores_rf.mean(axis=1)
test_scores_mean_rf = test_scores_rf.mean(axis=1)
# 3. 支持向量机学习曲线绘制
svm_model = SVC()
train_sizes_svm, train_scores_svm, test_scores_svm = learning_curve(svm_model, X, y, cv=5)
train_scores_mean_svm = train_scores_svm.mean(axis=1)
test_scores_mean_svm = test_scores_svm.mean(axis=1)
# 绘制到同一张图上
plt.plot(train_sizes_logistic, train_scores_mean_logistic, label='Logistic Regression - Training', marker='o')
plt.plot(train_sizes_logistic, test_scores_mean_logistic, label='Logistic Regression - Testing', marker='s')
plt.plot(train_sizes_rf, train_scores_mean_rf, label='Random Forest - Training', marker='^')
plt.plot(train_sizes_rf, test_scores_mean_rf, label='Random Forest - Testing', marker='v')
plt.plot(train_sizes_svm, train_scores_mean_svm, label='Support Vector Machine - Training', marker='*')
plt.plot(train_sizes_svm, test_scores_mean_svm, label='Support Vector Machine - Testing', marker='+')
plt.xlabel('Training set size')
plt.ylabel('Score')
plt.title('Learning Curves of Different Models for Turnover Prediction')
plt.legend()
plt.show()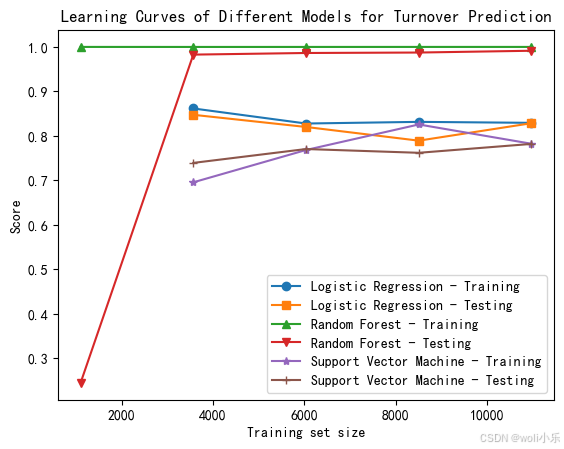
(1)逻辑回归:
训练集:随着训练集样本数量增加,蓝色曲线开始得分较低,然后逐渐上升,在大约4000个样本之后趋于平稳,最终稳定在0.85左右。
测试集(Testing):橙色曲线(逻辑回归 - 测试)与训练集曲线趋势类似,但得分略低,最终稳定在 0.8 左右。训练集和测试集得分差距相对较小,说明模型没有明显的过拟合或欠拟合问题,具有较好的泛化能力。
(2)随机森林 训练集(Training):绿色曲线(随机森林 - 训练)一开始就非常高,接近 1,并且随着训练集样本数量增加,始终保持在较高水平,几乎没有变化。
测试集(Testing):红色曲线(随机森林 - 测试)在开始时得分较低,随着样本数量增加,迅速上升到接近 1,并在之后保持稳定。训练集和测试集得分非常接近,表明随机森林模型在该数据集上表现出色,不仅在训练数据上拟合良好,而且在测试数据上也有很好的泛化能力。
(3)支持向量机
训练集(Training):紫色曲线(支持向量机 - 训练)起始得分较低,随着样本数量增加,缓慢上升,最终稳定在 0.75 左右。
测试集(Testing):棕色曲线(支持向量机 - 测试)与训练集曲线趋势相似,得分略低,稳定在 0.7 左右。训练集和测试集得分差距也不是很大,说明支持向量机模型在该任务上的泛化能力尚可,但相比逻辑回归和随机森林稍弱一些。
六、参数调节并进行分析以及可视化
(1)对随机森林的三个主要参数进行调节:树的最大深度(max_depth)、树的 总数(number of trees)、决策树生成的指标(criteion); 可视化展示不同深度、不同数的总数以及不同决策树生成的指标下,对f1的 影响;
# 1. 调节树的最大深度(max_depth)对F1分数的影响
max_depths = [None, 5, 10, 15, 20] # 可以尝试不同的深度值,None表示不限制深度
f1_scores_depth = []
for depth in max_depths:
model = RandomForestClassifier(n_estimators=100, max_depth=depth, criterion='gini', random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred)
f1_scores_depth.append(f1)
plt.plot(max_depths, f1_scores_depth, marker='o', label='max_depth')
plt.xlabel('Max Depth')
plt.ylabel('F1 Score')
plt.title('Effect of Max Depth on F1 Score')
plt.legend()
plt.show()
# 2. 调节树的总数(n_estimators)对F1分数的影响
n_estimators_list = [50, 100, 150, 200, 250] # 尝试不同数量的树
f1_scores_n_estimators = []
for n_estimators in n_estimators_list:
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=None, criterion='gini', random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred)
f1_scores_n_estimators.append(f1)
plt.plot(n_estimators_list, f1_scores_n_estimators, marker='s', label='n_estimators')
plt.xlabel('Number of Trees')
plt.ylabel('F1 Score')
plt.title('Effect of Number of Trees on F1 Score')
plt.legend()
plt.show()
# 3. 调节决策树生成的指标(criterion)对F1分数的影响
criteria = ['gini', 'entropy'] # 常用的两种指标
f1_scores_criterion = []
for criterion in criteria:
model = RandomForestClassifier(n_estimators=100, max_depth=None, criterion=criterion, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred)
f1_scores_criterion.append(f1)
plt.bar(criteria, f1_scores_criterion, label='criterion')
plt.xlabel('Criterion')
plt.ylabel('F1 Score')
plt.title('Effect of Criterion on F1 Score')
plt.legend()
plt.show()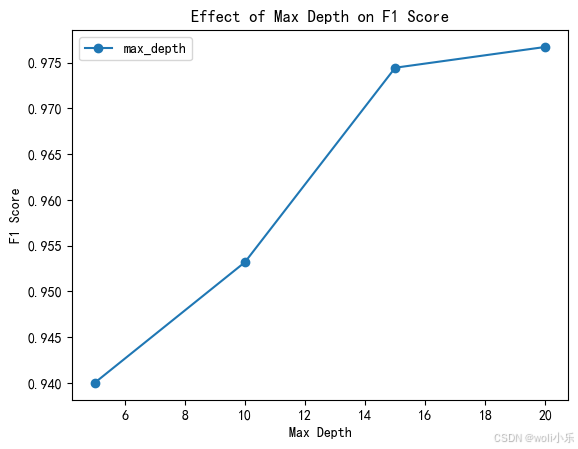
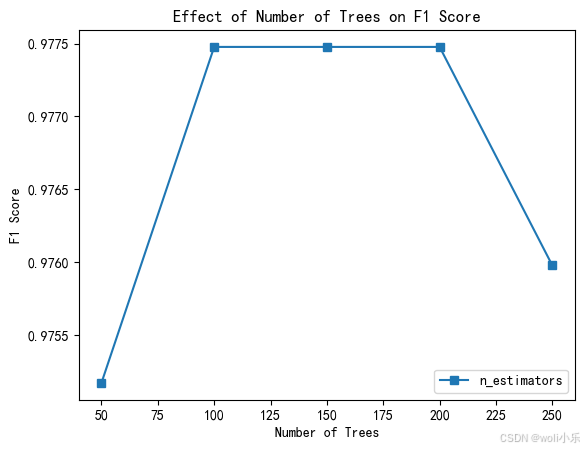
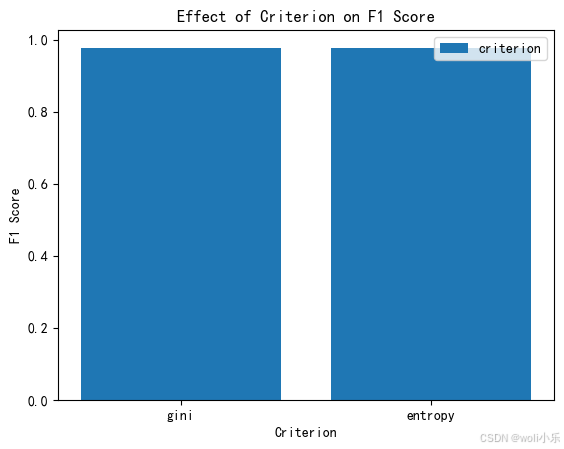
通过对三个参数的分析可以看出,树的最大深度(max_depth)在其变化范围内对 F1 分数的提升较为稳定且幅度较大;树的总数(n_estimators)虽然在初期有较大影响,但超过一定数量后影响较小,且存在性能下降的情况;决策树生成的指标(criterion)几乎没有影响。
(2)SVM算法训练时,分析出调整不同的核函数、不同的惩罚措施系数C值与 gamma系数对训练结果的影响,并形成分析报告;
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 1. 分析不同核函数的影响
kernels = ['linear', 'poly', 'rbf']
accuracy_kernels = []
for kernel in kernels:
model = SVC(kernel=kernel, C=1.0, gamma='scale')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracy_kernels.append(accuracy)
plt.bar(kernels, accuracy_kernels)
plt.xlabel('Kernel')
plt.ylabel('Accuracy')
plt.title('Effect of Different Kernels on Accuracy')
plt.show()
# 2. 分析不同C值的影响(以rbf核为例)
C_values = [0.1, 1, 10]
accuracy_C = []
for C in C_values:
model = SVC(kernel='rbf', C=C, gamma='scale')
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracy_C.append(accuracy)
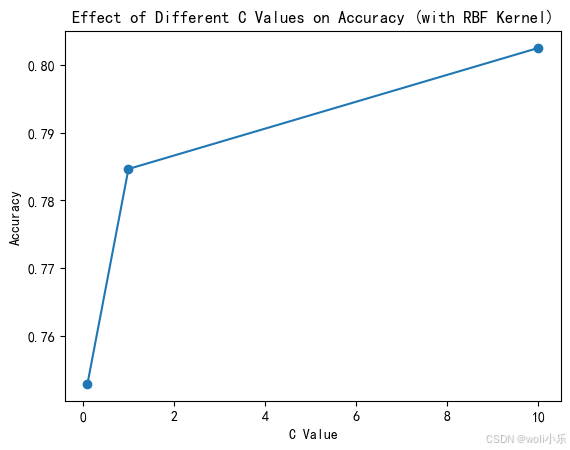
plt.plot(C_values, accuracy_C, marker='o')
plt.xlabel('C Value')
plt.ylabel('Accuracy')
plt.title('Effect of Different C Values on Accuracy (with RBF Kernel)')
plt.show()
# 3. 分析不同gamma值的影响(以rbf核为例)
gamma_values = [0.1, 1, 10]
accuracy_gamma = []
for gamma in gamma_values:
model = SVC(kernel='rbf', C=1.0, gamma=gamma)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracy_gamma.append(accuracy)
plt.plot(gamma_values, accuracy_gamma, marker='o')
plt.xlabel('Gamma Value')
plt.ylabel('Accuracy')
plt.title('Effect of Different Gamma Values on Accuracy (with RBF Kernel)')
plt.show()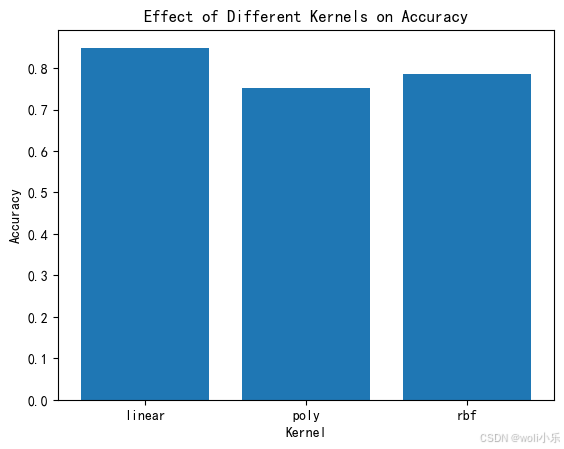
- 核影响 核函数用于将输入数据映射到更高维的空间,以便在该空间中找到最佳的线性分割平面。常用的核函数包括线性核(linear)、多项式核(poly)和径向基函数核(RBF)。
- 线性核(linear):适用于线性可分的数据。从图中可以看出,线性核的准确率最高,这表明数据可能在原始特征空间中接近线性可分。
- 多项式核(poly):适用于非线性可分的数据,但需要更多的参数调整。图中显示多项式核的准确率低于线性核,这可能是因为参数未经过优化。
- RBF核(rbf):适用于各种类型的数据,但需要调整 γ 参数。RBF核的准确率与线性核相近,表明RBF核能够有效处理数据的非线性特性。
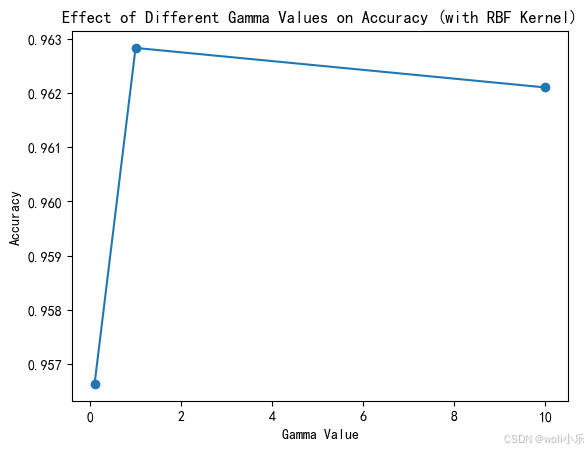
- 惩罚系数 C C 的影响惩罚系数 C 控制模型对误分类的容忍度。较大的 C 值意味着模型对误分类的惩罚更重,可能导致过拟合;较小的 C值则可能导致欠拟合。从图中可以看出,随着C 值的增加,准确率逐渐提高。这表明在当前数据集上,模型可能存在一定的欠拟合,通过增加C值可以提高模型的拟合能力。
- γ 参数定义了RBF核的宽度,即单个训练样本的影响范围。较小的 γ值意味着“更远”的样本也会被考虑在内,可能导致过拟合;较大的 γ值则可能导致欠拟合。图中显示,当γ值从0增加到1时,准确率迅速提高,然后随着 γ 值的进一步增加而逐渐下降。这表明存在一个最优的 γ 值,使得模型在训练数据上的表现最佳。
(3)逻辑回归训练时,通过k折交叉验证的方式调整不同的k值,分析不同k 值下逻辑回归训练结果的影响,并形成分析报告;
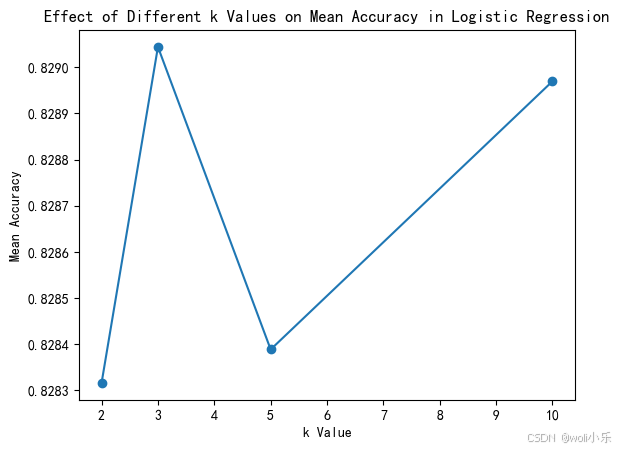
从提供的图表中,我们可以观察到不同k值对逻辑回归模型平均准确率的影响:
k=2:平均准确率最低,约为0.8283。这可能是因为数据集被分成的子集太少,导致模型在训练时没有足够的数据,从而影响了模型的泛化能力。
k=3:平均准确率最高,约为0.8291。这表明当数据集被分成3个子集时,模型在测试集上的表现最好。这可能是因为3折交叉验证在训练和测试之间提供了一个较好的平衡。
k=5:平均准确率下降到约0.8284,这可能是因为更多的数据被用于测试,而训练数据减少,导致模型的拟合能力下降。
k=10:平均准确率再次上升,约为0.8290。这可能是因为更多的训练数据有助于提高模型的泛化能力。
- k值选择的考虑 较小的k值(如k=2或k=3):可能会导致模型在训练时过拟合,因为大部分数据用于训练,只有一小部分用于测试。
较大的k值(如k=10):可能会使模型更接近于在所有数据上训练的结果,但计算成本更高,因为需要进行更多的训练和测试循环。
- 结论 最佳k值:从图表中可以看出,k=3和k=10时,模型的平均准确率最高。这表明在这两个k值下,模型的泛化能力较好。
推荐做法:在实际应用中,k=5或k=10是常用的选择,因为它们在泛化能力和计算成本之间提供了一个较好的平衡。然而,最终的选择应基于具体的数据集和计算资源。
随着K值的增加,模型的准确率呈现出一定的波动。当K值较小时,模型的准确率可能受到训练数据划分的影响较大,导致结果不稳定。随着K值的增加,模型的准确率逐渐趋于稳定,但过高的K值也会增加计算复杂度。
在对逻辑回归、SVM和随机森林算法模型进行参数调整的研究中,我们发现了一些关键的洞察和建议。以下是对这些算法训练参数影响的总结:
逻辑回归
逻辑回归模型的性能可以通过调整正则化强度等参数来优化。正则化可以帮助防止模型过拟合,提高其在未见数据上的泛化能力。在实际应用中,建议使用交叉验证来确定最佳的正则化参数,以平衡偏差和方差。
SVM
SVM算法的参数调优主要集中在选择合适的核函数、惩罚系数 ( C ) 和 ( \gamma ) 系数(对于RBF核)。核函数的选择影响模型的决策边界,而 ( C ) 和 ( \gamma ) 则控制模型的复杂度和拟合程度。通过网格搜索或随机搜索可以找到最优的参数组合,从而提高模型的分类性能。
随机森林
随机森林的性能可以通过调整树的数量、最大深度、最小样本分割比例等超参数来提升。增加树的数量可以降低模型的方差,而调整最大深度和最小样本分割比例则可以控制模型的复杂度,防止过拟合。贝叶斯优化是一种有效的参数调优方法,可以在随机森林中应用,以找到最优的超参数组合。
总结
- 逻辑回归:关注正则化参数的调整,使用交叉验证来确定最佳参数。
- SVM:选择合适的核函数和调整 ( C )、( \gamma ) 参数,利用网格搜索或随机搜索进行参数优化。
- 随机森林:调整树的数量和结构相关的超参数,考虑使用贝叶斯优化来提升性能。
通过这些参数的调整,可以显著提高模型的性能,但需要注意的是,参数的选择应基于具体的数据集和问题特性。此外,参数调优过程可能会增加计算成本,因此在实际应用中需要权衡性能提升与计算资源之间的关系。

















 140
140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









