







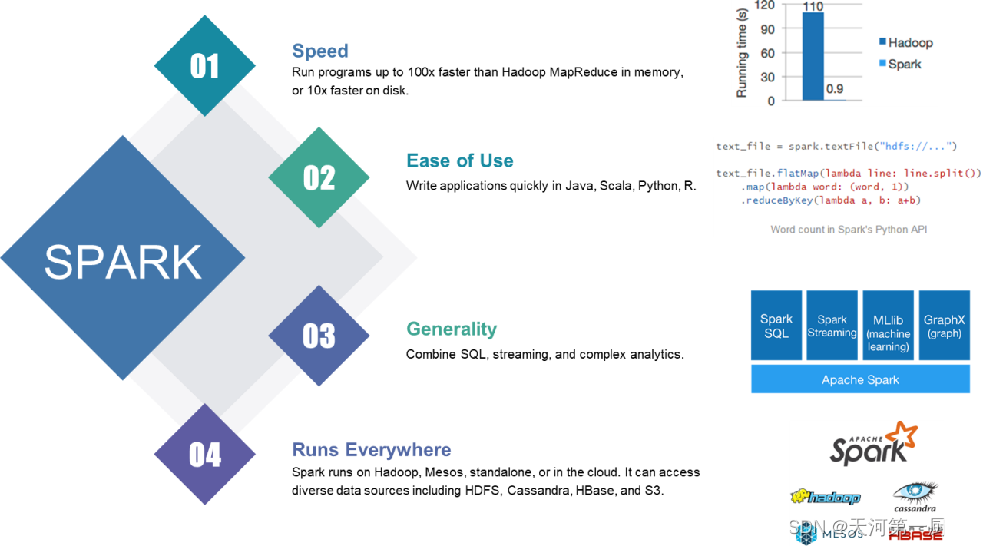
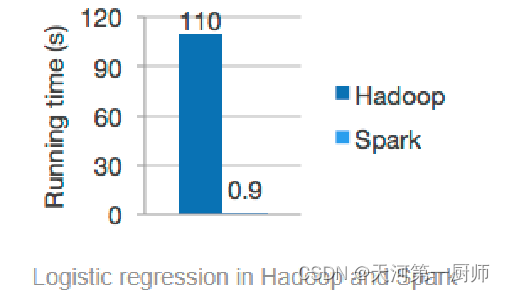
1.运行效率高:
为什么说运行效率高呢?
一是因为spark提供了一个全新的数据结构,这个是基于内存来做计算的,且当内存不足时还可以放入磁盘上去。整个流程是基于DAG(有向无环图)的执行引擎支持无环数据流;
二是因为整个spark是基于线程来运行的,线程的启动和销毁都由于进程;
2.易用性好:一是spark提供了多种操作语言的API:例如有Python、SQL、Scala、Java、R语言;
二是提供了非常多的高阶API,这些API在不同操作语言中都是类似的,大大降低了程序员的学习成本;
3.通用性强:spark提供了非常多的工具库,包括spark core、spark sql、spark streaming、MLib、GraphX,可以直接让我们在一个应用中使用多个工具库,其中,Spark SQL 提供了结构化的数据处理方式,Spark Streaming 主要针对流式处理任务(也是本书的重点),MLlib提供了很多有用的机器学习算法库,GraphX提供图形和图形并行化计算。

4.随处运行:一个是编写好的spark程序可以提交到多个资源平台上运行:local spark集群 yarn 支持其他的云平台;
二是spark框架可以和多种软件进行集成、方便我们对接不同的软件完成处理;
















 3287
3287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









