







爬虫四个主要步骤:
- 明确目标(要知道你准备在哪个范围或者网站去搜索
- 爬(将所有的网站的内容全部爬下来)
- 取(去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
在此之前,我们实现的简单版以及并发版的爬虫都没有对我们所需的信息进行过滤,这样得到的信息大多是我们不需要的,接下来我们就以捧腹网的笑话信息进行爬虫,并筛选出来我们需要的笑话信息。
捧腹网
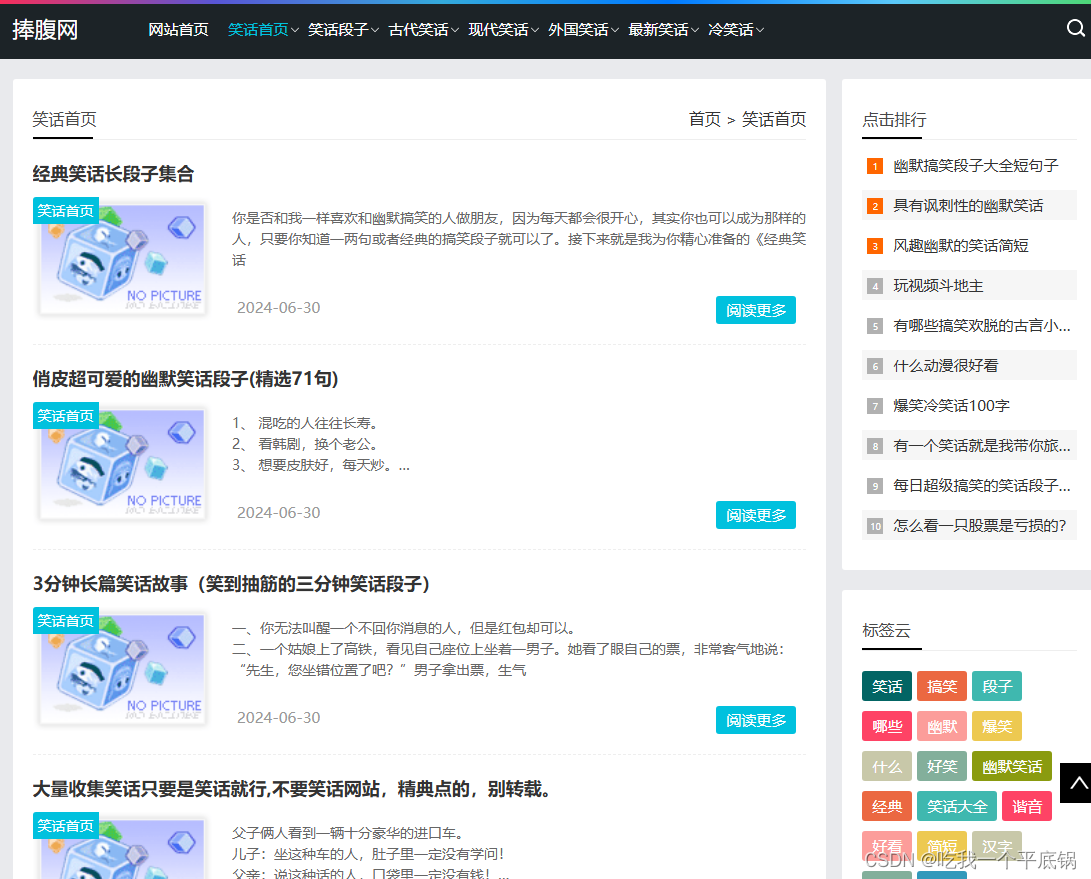
总结页面信息
经过查看页面的源码:
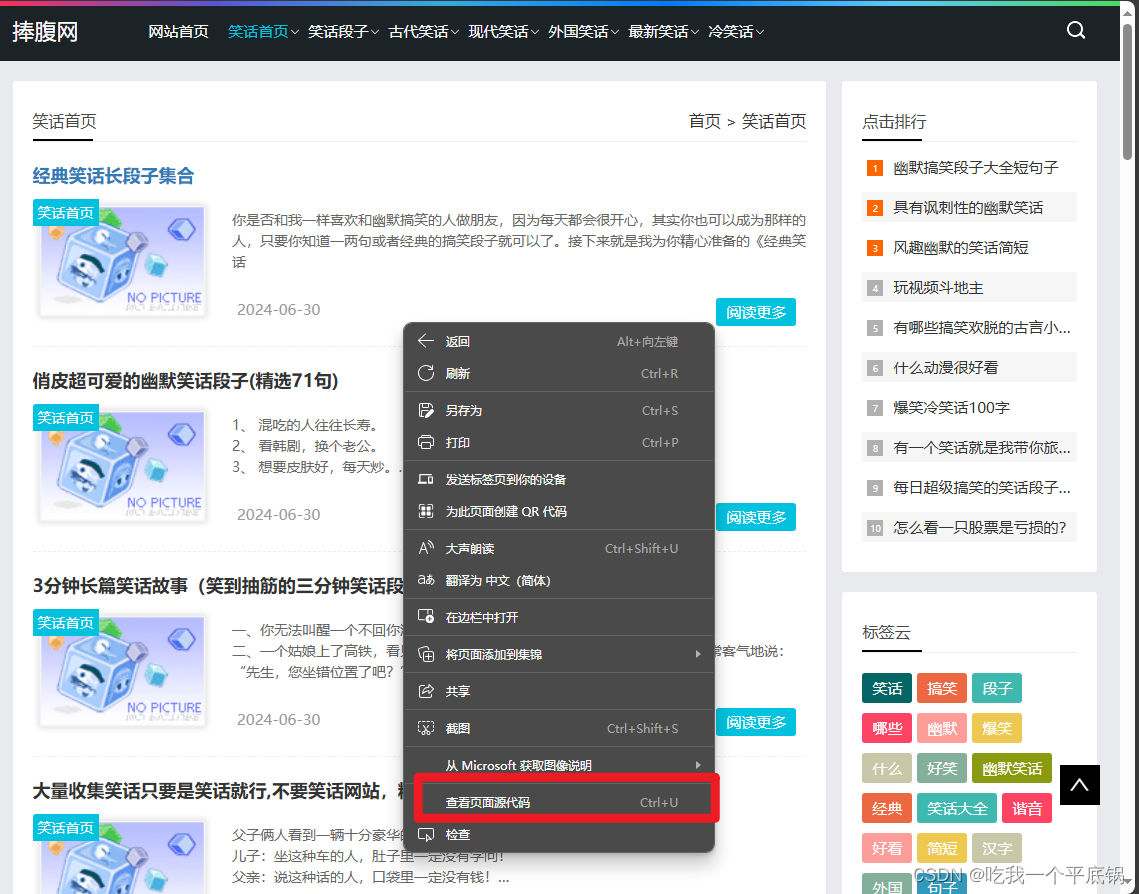
我们可以总结出来以下的信息:
-
网页规律:
https://www.pengfu.net/xiaohuashouye/
https://www.pengfu.net/xiaohuashouye/index_2.html
https://www.pengfu.net/xiaohuashouye/index_3.html -
主页面规律:
<h3 class="blogtitle"><a href=" 开头
" 结尾
<h3 class="blogtitle"><a href=" 一个段子的ur1连接" 结尾
- 一个系列段子的规律:
<h1 class="con_tilte">幽默笑话(100个幽默笑话简短)</h1> //标题
<div class="con_text"> 段子开头
<p class="share"> 段子结尾
代码实现
主线程
func main() {
var start, end int
fmt.Printf("请输入起始页(>=1):")
fmt.Scan(&start)
fmt.Printf("请输入终止页(>=起始页):")
fmt.Scan(&end)
DoWork(start, end)
}
- 提示输入需要爬取的起始页和终止页
- 开启爬虫函数
DoWork(start, end)
DoWork(start, end)
func DoWork(start, end int) {
fmt.Printf("准备爬取%d到%d的网址\n", start, end)
page := make(chan int)
//定义一个函数,爬主页面
for i := start; i <= end; i++ {
go SqiderPage(i, page)
}
for i := start; i <= end; i++ {
fmt.Printf("第%d个页面爬取完成\n", <-page)
}
}
- 开启子线程对每一页进行爬取
SqiderPage(i, page),这里使用了管道,用来阻塞等待爬取成功,否则会因为DoWork(start, end)的退出,导致子线程退出,爬取失败。
SqiderPage(i, page)
func SqiderPage(i int, page chan<- int) {
//明确爬取的url
var url string
if i == 1 {
url = "https://www.pengfu.net/xiaohuashouye/index.html"
} else {
url = "https://www.pengfu.net/xiaohuashouye/index_" + strconv.Itoa(i) + ".html"
}
fmt.Printf("准备爬取第%d个网址:%s\n", i, url)
//开始爬取页面内容
result, err := HttpGet(url)
if err != nil {
fmt.Println("HttpGet.err=", err)
return
}
//fmt.Println("r=", result)
//取内容 <h3 class="blogtitle"><a href="一个段子的ur1连接"结尾
//解析表达式
re := regexp.MustCompile(`<h3 class="blogtitle"><a href="(?s:(.*?))"`)
if re == nil {
fmt.Println("regexp.MustCompile.err=", err)
return
}
//取关键信息从result中过滤,-1代表取所有内容
joyUrls := re.FindAllStringSubmatch(result, -1)
fileTitle := make([]string, 0)
fileContent := make([]string, 0)
//取网址
for _, data := range joyUrls {
//fmt.Println("Urls=", data[1])
//开始爬取每一个系列笑话
title, content, err := SpiderOneJoy(data[1])
if err != nil {
fmt.Println("SpiderOneJoy.err=", err)
continue
}
//fmt.Printf("title=#%v#", title)
//fmt.Printf("content=#%v#", content)
fileTitle = append(fileTitle, title)
fileContent = append(fileContent, content)
}
//把内容写入到文件
StoreJoyToFile(i, fileTitle, fileContent)
page <- i //写
}
- 获取每一页的URL,根据规律可以写为以下URL:
if i == 1 {
url = "https://www.pengfu.net/xiaohuashouye/index.html"
} else {
url = "https://www.pengfu.net/xiaohuashouye/index_" + strconv.Itoa(i) + ".html"
}
- 利用函数
HttpGet(url),获取页面信息,开始爬取页面内容 - 利用正则表达式,获取每一系列笑话的URL
- 开始爬取每一个系列笑话
SpiderOneJoy(data[1]) - 得到内容和标题后利用
StoreJoyToFile(i, fileTitle, fileContent),写入到文件中
HttpGet(url)
func HttpGet(url string) (result string, err error) {
resp, err1 := http.Get(url)
if err1 != nil {
err = err1
return
}
defer resp.Body.Close()
//读取网页内容
buf := make([]byte, 4*1024)
for {
n, _ := resp.Body.Read(buf)
if n == 0 {
break
}
result += string(buf[:n])
}
return
}
- 利用
http.Get(url以及resp.Body.Read(buf)获取网页内容。
SpiderOneJoy(url string)
func SpiderOneJoy(url string) (title string, content string, err error) {
result, err1 := HttpGet(url)
if err1 != nil {
err = err1
return
}
//取关键信息<h1 class="con_tilte">幽默笑话(100个幽默笑话简短)</h1>
re1 := regexp.MustCompile(`<h1 class="con_tilte">(?s:(.*?))</h1>`)
if re1 == nil {
err = fmt.Errorf("%s", "regexp.MustCompile.err")
return
}
//取标题
tmpTitle := re1.FindAllStringSubmatch(result, -1)
for _, data := range tmpTitle {
title = data[1]
// title = strings.Replace(title, "\n", "", -1)
// title = strings.Replace(content, " ", "", -1)
break
}
//取内容 1表示只过滤第一个
//<div class="con_text"> 段子开头
//</a>(<b id="diggnum"><script src= 段子结尾
re2 := regexp.MustCompile(`<div class="con_text">(?s:(.*?))<p class="share">`)
if re2 == nil {
err = fmt.Errorf("%s", "regexp.MustCompile.err2")
return
}
tmpContent := re2.FindAllStringSubmatch(result, -1)
for _, data := range tmpContent {
content = data[1]
content = strings.Replace(content, "\n", "", -1)
content = strings.Replace(content, "<p>", "", -1)
content = strings.Replace(content, "</p>", "", -1)
content = strings.Replace(content, " ", "", -1)
break
}
return
}
- 根据页面源码的题目以及内容特征,利用正则表达式获取题目以及内容;
- 通过函数
strings.Replace可以过滤到我们不需要的一些空格等信息;
StoreJoyToFile(i int, fileTitle []string, fileContent []string)
func StoreJoyToFile(i int, fileTitle []string, fileContent []string) {
f, err := os.Create(strconv.Itoa(i) + ".txt")
if err != nil {
fmt.Println("os.Create.err=", err)
return
}
defer f.Close()
//写内容
n := len(fileTitle)
for i := 0; i < n; i++ {
f.WriteString(fileTitle[i] + "\n")
f.WriteString(fileContent[i] + "\n")
f.WriteString("\n=============================================================\n")
}
}
- 以第几页为标题,创建一个文件,将内容写入。
结果展示
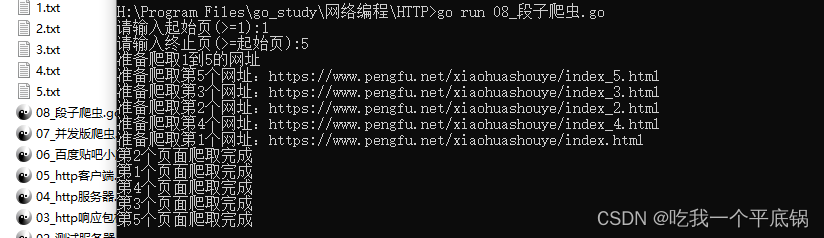

网页信息对比
















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









