






block
这个网络的block长下面这样,主要是结合了resnet和densenet各自的优点,同时引进了注意力机制,平时用的maxpool和gate机制都可以看成基于显著性的注意力,这里是基于门控的,有一个更新门和遗忘门。||是通道拼接,就densenet那种,+是逐元素相加,resnet里面那种,densenet擅长特征图的利用和探索,但是容易产生冗余,而resnet可以避免冗余,但是但缺乏特征保留和探索的能力。这里使用嵌套结构将两者进行结合,避免densenet特征冗余最简单的方法是减少网络深度,但是这样做影响特征表示能力,会降低精度,因此在局部使用残差连接进行增强,cell1用于得到更紧凑的特征图,cell2使用多种卷积核用于提取多尺度的特征。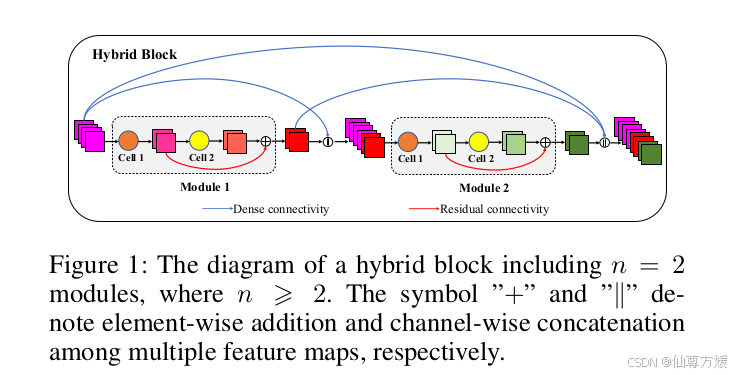
感受野
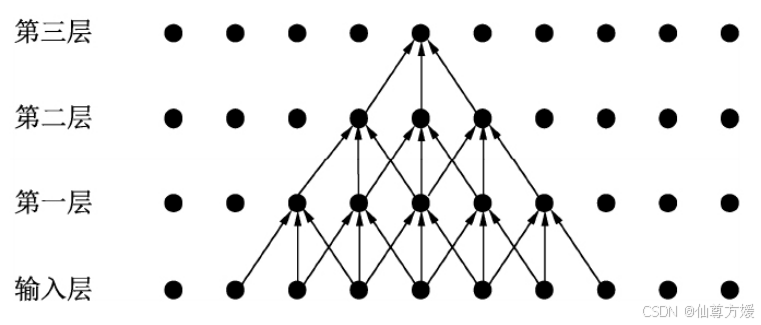 每一层的卷积核为3×3,步长为1,可以看到第一层对应的感受野是3×3,第二层是5×5,第三层则是7×7。平时用maxpool进行下采样也是在扩大感受野。不同卷积核对应感受野是不同的,但大的卷积可以分解为小的,如图,5×5可以分解成两个3×3
每一层的卷积核为3×3,步长为1,可以看到第一层对应的感受野是3×3,第二层是5×5,第三层则是7×7。平时用maxpool进行下采样也是在扩大感受野。不同卷积核对应感受野是不同的,但大的卷积可以分解为小的,如图,5×5可以分解成两个3×3
module
卷积结构
里面每个卷积都是下面这种结构
批量归一化(BN)-修正线性单元(ReLU)-卷积(Conv)。
Cell
Squeeze Cell.(压缩单元)
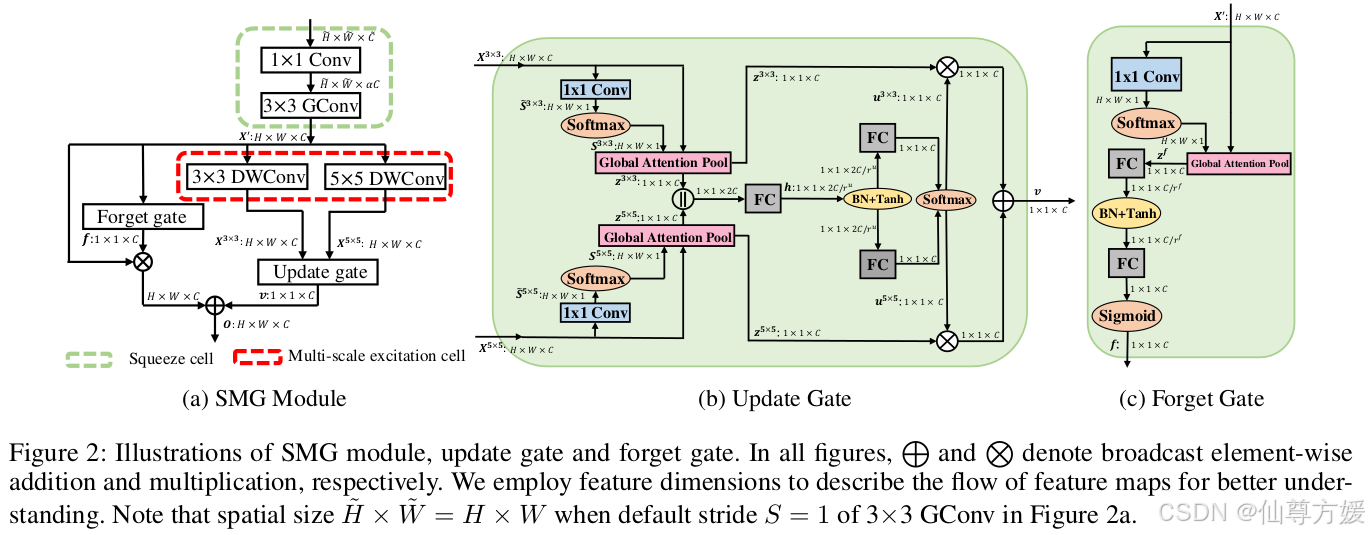
图中的cell1,主要是为了产生更为紧凑的特征图,具体就是上面的图中的绿色框,1×1卷积,非常常见的降维方法,接着使用组卷积,组卷积将通道进行了分组,具体长下面这样

Multi-scale Excitation Cell(多尺度提取单元)
利用多尺度也是很常见的方法,这主要是因为图中的物体有大有小,大尺度对小物体比较友好,小的尺度对大的物体比较友好,结合多种尺度能同时识别小的物体和大的物体,FPN也是这种策略,能提升模型效果,上面经过cell1进行降维得到更为紧凑的特征图,降低了计算量,这里都使用深度可分离卷积,计算量大概为一般卷积的1/9,同时3×3的分支还用了空洞卷积,可以在增大感受野的同时保持特征图大小不变,不同大小的卷积核就是这里的多尺度提取
门控机制
也就是使用了基于显著性注意力
注意力机制
注意力分布

加权平均

Update Gate.
为了捕捉长距离依赖,我们利用更新门来从多尺度信息中建模全局上下文特征。可以按顺序总结为3个阶段:空间注意力、池化和通道注意力。
spatial attention and pooling
首先进行1×1卷积压缩通道为1,然后用softmax获得注意力分布,公式如下:
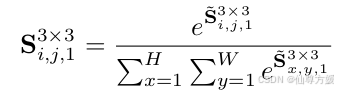
进行池化,公式如下:
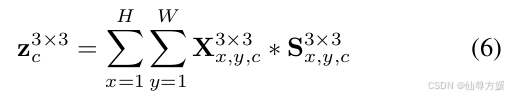
channel attention
为了保持信息的完整性,我们将 z3×3 和 z5×5 连接起来作为输入。然后它被转换为一个隐藏表示 h ∈ R1×1×2∗C/r,通过设置一个缩减比 ru 以获得更好的效率,这始终是一个紧凑的特征图。这是通过一个带有非线性的全连接(FC)层实现的
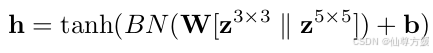
两个FC产生过渡的通道注意力分布,softmax产生最后的注意力分布

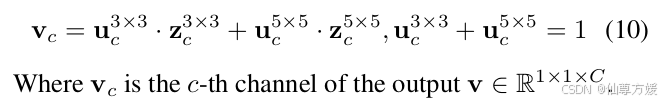
Forget Gate
3个阶段:空间注意力、池化和通道注意力。和上面差不多,这里不展开,最后使用sigmoid用于遗忘信息
HCGNET
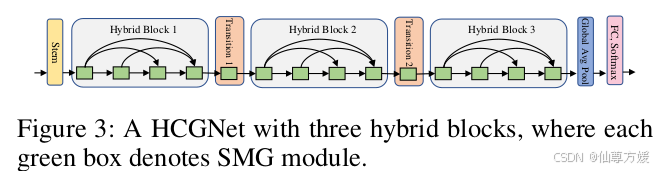
简单的网络如上,如图所示,HCGNet的开始是一个主干(stem),这是一个复合函数,用于处理初始输入图像。然后,多个混合块以不同的空间阶段堆叠。在两个相邻的混合块之间,我们采用了一个过渡层来执行下采样和连接截断。在最后的混合块之后,一个全局平均池化层附加一softmax分类器,用于计算各种类别的概率。混合块和过渡层都采用SMG模块,但具有不同的超参数设置。
模型性能
分类
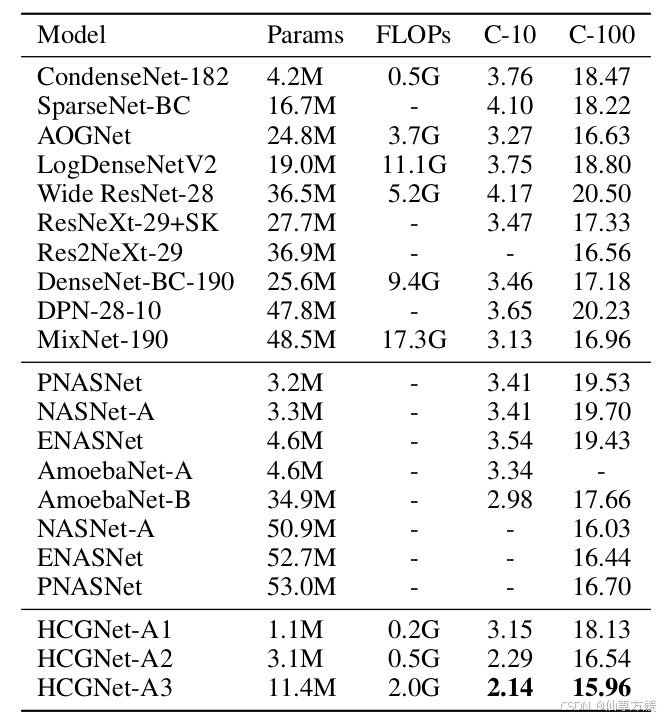
CIFAR-10 and CIFAR-100 datasets.
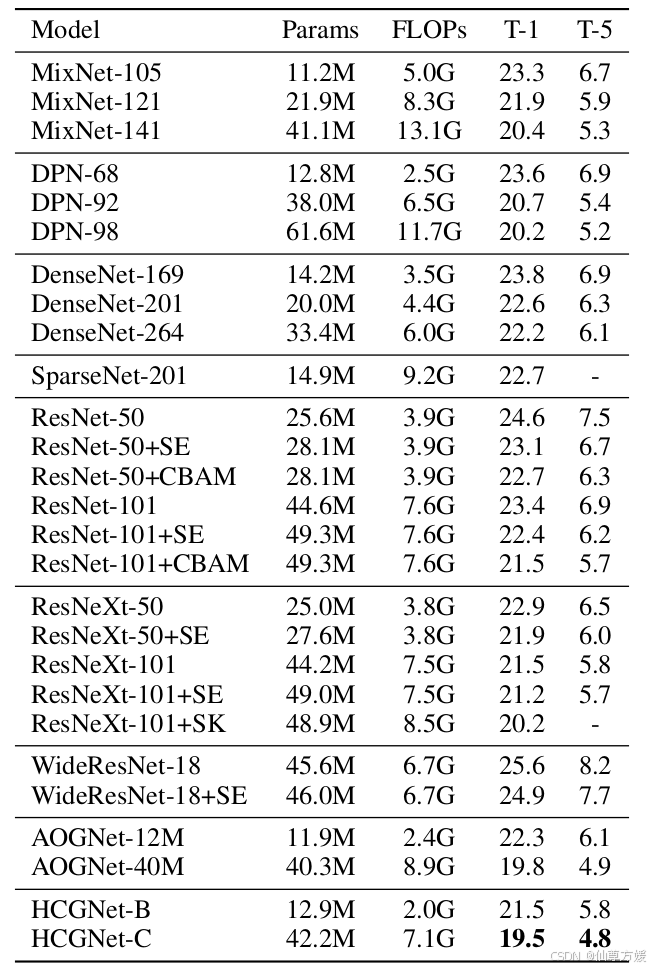
ImageNet.
目标检测
COCO



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









