






一开始window用不了keras-nlp,用wsl想下载tensorflow2.16.1,失败了,现在换了ubuntu
中英文tensorflow显示页面不一样
这是中文界面
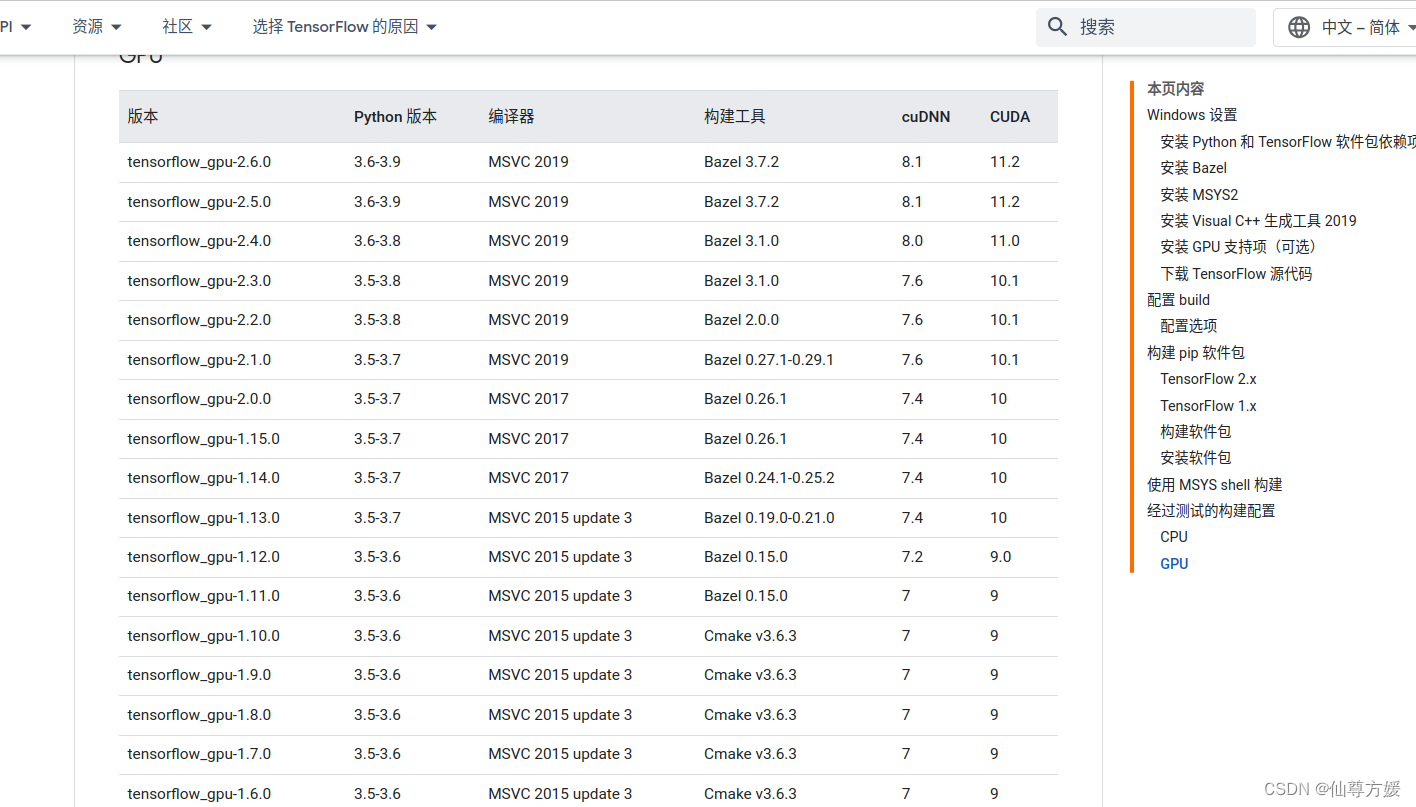
这是英文的
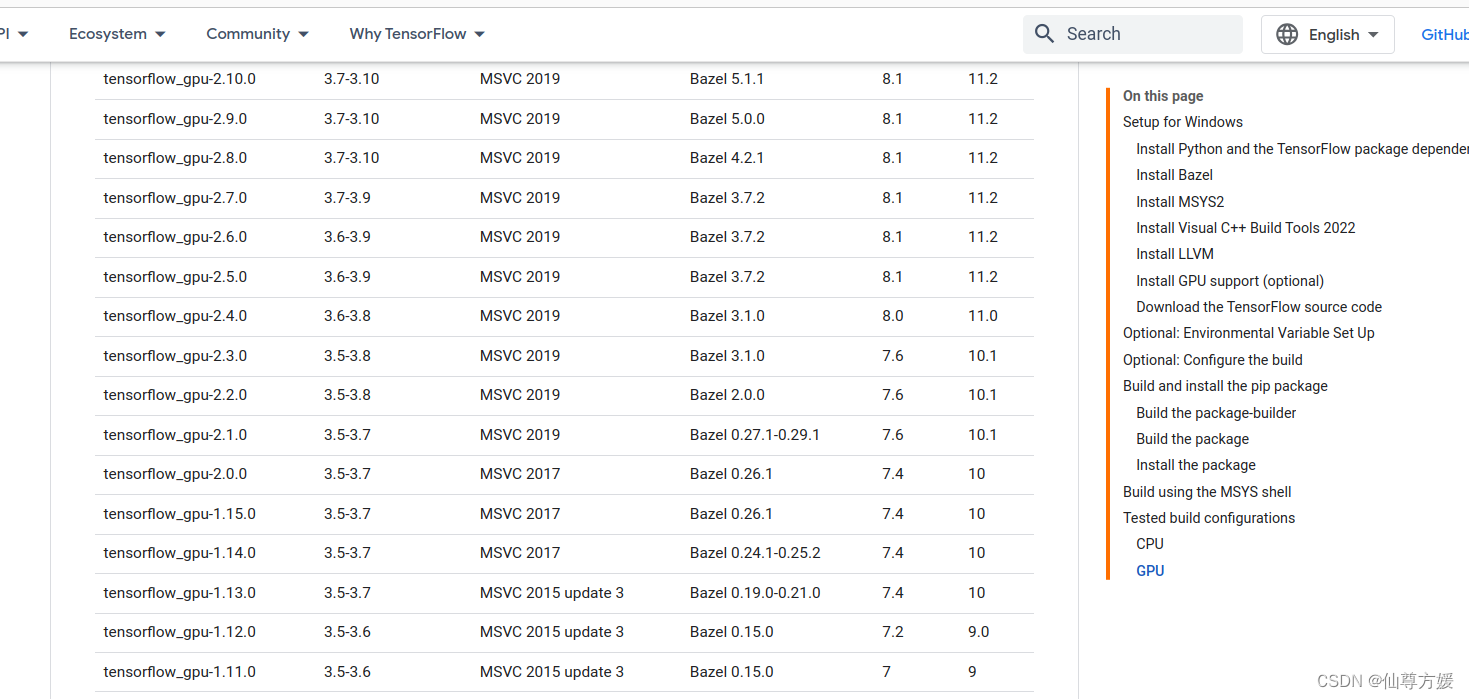
就是你用的window系统的话可以用2.10,但2.10之后就只能通过wsl安装了,试了很多次没成功,直接就换成ubuntu
keras-nlp在ubuntu可以用
直接pip就行
调用包和读取数据
调用包
!pip install keras-core --upgrade
!pip install -q keras-nlp --upgrade
import os
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
import keras_core as keras
import keras_nlp
from sklearn.model_selection import train_test_split
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix导入数据
这里选择后端为tensorflow,现在也能支持别的
os.environ['KERAS_BACKEND'] = 'tensorflow'
df_train = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
df_test = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")导入预训练模型
这里主要就是text变量用于训练模型,这个变量没有缺失值,其他变量有缺失,但是用不到,包括keyword,location这些,都用不到,当作分类变量来用,里面种类又太多,不具有分析价值,我查看了text变量,训练集最大长度是157,测试是151,所以使用长度为160,不足的会进行填充,因为没有长于160的,所有不会有text被截断
batchsize = 32
sam_num = df_train.shape[0]
AUTO = tf.data.experimental.AUTOTUNE
X = df_train["text"]
y = df_train["target"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2,stratify = y)
X_test = df_test["text"]模型
preset= "distil_bert_base_en_uncased"
preprocessor = keras_nlp.models.DistilBertPreprocessor.from_preset(preset,
sequence_length=160
)
classifier = keras_nlp.models.DistilBertClassifier.from_preset(preset,
preprocessor = preprocessor,
num_classes=2)这个模型distilbert是bert的变体,保留绝大数功能,但速度更快,我看kaggle下面的notebook大多数人都用了这个模型。
训练模型
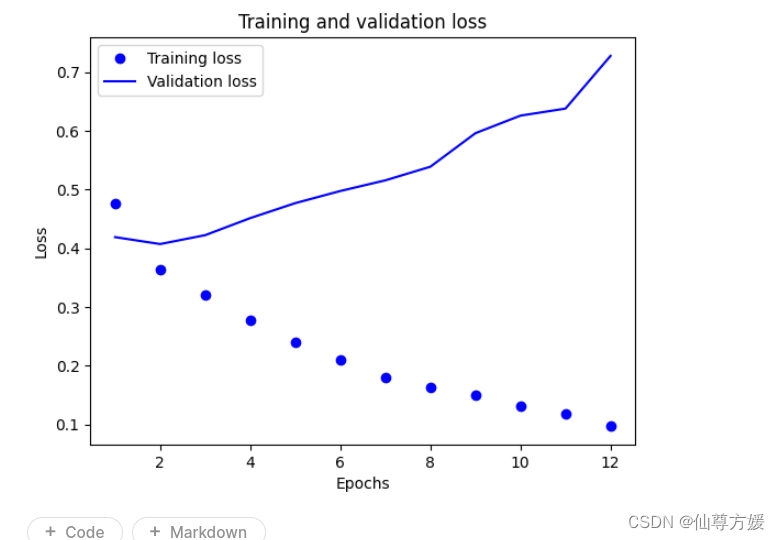
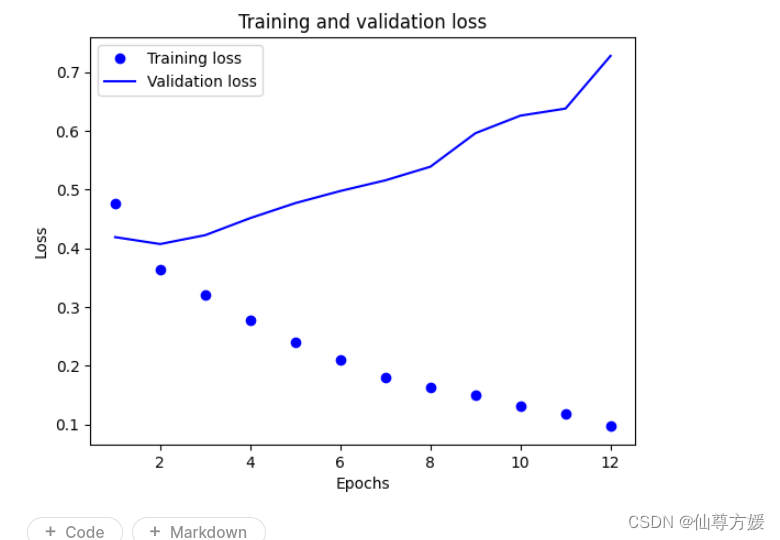
这里用来Adam这个优化器,也是刚开始用,之前一直用rmsprop,网上说这个优化结合rmsprop和adagrad的特性,能自动为为个参数调整learning_rate,之后有时间再看看,epoch只用了2轮,我尝试用更多,但很快就开始在验证集上过拟合,像下面这种,accuracy在验证集上不再上升,val_loss开始上涨,2个轮次是合适的
from keras.optimizers import Adam
classifier.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=Adam(learning_rate=1e-5),
metrics=["accuracy"]
)
history = classifier.fit(
x=X_train,
y=y_train,
batch_size=32,
epochs=2,
validation_data=(X_val, y_val)
)
 提交结果
提交结果
sample_submission = pd.read_csv("/kaggle/input/nlp-getting-started/sample_submission.csv")
sample_submission.head()
sample_submission["target"] = np.argmax(classifier.predict(X_test), axis=1)
sample_submission.head()
sample_submission.to_csv("submission.csv", index=False)用这个大概是80上下,自己从头训练用dense就行吧,毕竟这个分类关键词更重要一些
我看到有个人跑了96%的准确率,但我不理解,链接如下
Transformers-based NLP Model (3) | Kaggle
他的数据集多了一个文件,但那个文件我在kaggle上没看到,就下面这张图第一行

他的数据集是这样的,我不理解从哪里来的,挺奇怪,还有些别的得等我转修pytorch才能看得懂















 2415
2415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









