







Ⅰ.字典(dict)
这节课我们依然得要学习python内置的数据结构

0x00 什么是字典
字典也是 Python 提供的一种常用的数据结构,它用于存放具有映射关系的数据。
比如有份小明成绩表数据,语文:79,数学:80,英语:92,这组数据看上去像两个列表,但这两个列表的元素之间有一定的关联关系。如果单纯使用两个列表来保存这组数据,则无法记录两组数据之间的关联关系。
为了保存具有映射关系的数据,Python 提供了字典,字典相当于保存了两组数据,其中一组数据是关键数据,被称为 key;另一组数据可通过 key 来访问,被称为 value。形象地看,字典中 key 和 value 的关联关系如下所示:
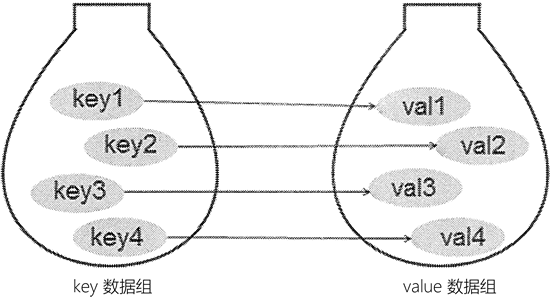
🔴由于字典中的 key 是非常关键的数据,而且程序需要通过 key 来访问 value,因此字典中的 key 不允许重复。

0x01 创建字典
程序既可使用花括号语法来创建字典,也可使用 dict() 函数来创建字典。实际上,dict 是一种类型,它就是 Python 中的字典类型。
在使用花括号语法创建字典时,花括号中应包含多个 key-value 对,key 与 value 之间用英文冒号隔开;多个 key-value 对之间用英文逗号隔开。
基本格式如下:
dict0 = {key1: value1, key2: value2}字典也被称作关联数组或哈希表。下面是几种常见的字典创建方式:
scores = {'语文': 89, '数学': 92, '英语': 93}
print(scores)
# 空的花括号代表空的dict
empty_dict = {}
print(empty_dict)
# 使用元组作为dict的key
dict2 = {(20, 30):'good', 30:'bad'}
print(dict2)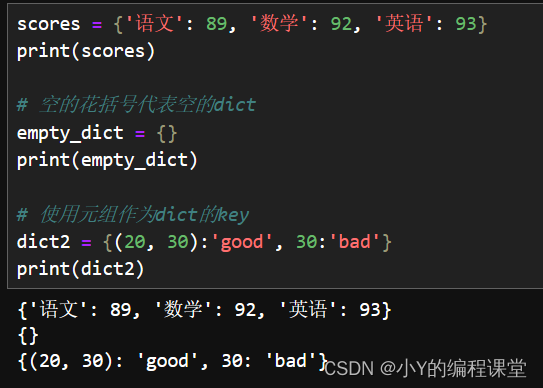
上面程序中第 1 行代码创建了一个简单的 dict,该 dict 的 key 是字符串,value 是整数;第 5行代码使用花括号创建了一个空的字典;第 9 行代码创建的字典中第一个 key 是元组,第二个 key 是整数值,这都是合法的。
需要指出的是,元组可以作为 dict 的 key,但列表不能作为元组的 key。这是由于 dict 要求 key 必须是不可变类型,但列表是可变类型,因此列表不能作为元组的 key。
在使用 dict() 函数创建字典时,可以传入多个列表或元组参数作为 key-value 对,每个列表或元组将被当成一个 key-value 对,因此这些列表或元组都只能包含两个元素。例如如下代码:
vegetables = [('celery', 1.58), ('brocoli', 1.29), ('lettuce', 2.19)]
# 创建包含3组key-value对的字典
dict3 = dict(vegetables)
print(dict3) # {'celery': 1.58, 'brocoli': 1.29, 'lettuce': 2.19}
cars = [['BMW', 8.5], ['BENS', 8.3], ['AUDI', 7.9]]
# 创建包含3组key-value对的字典
dict4 = dict(cars)
print(dict4) # {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}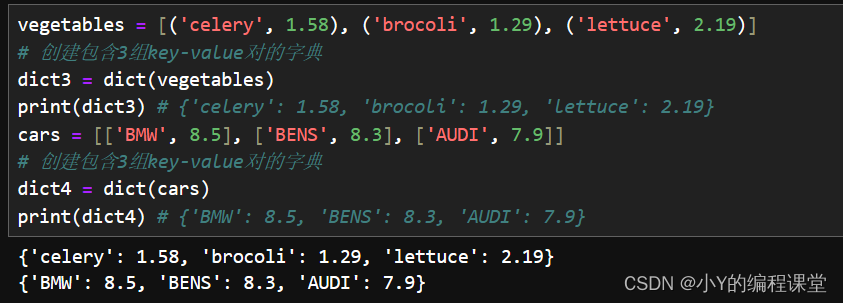
如果不为 dict() 函数传入任何参数,则代表创建一个空的字典。
还可通过为 dict 指定关键字参数创建字典,此时字典的 key 不允许使用表达式。例如如下代码:
# 使用关键字参数来创建字典
dict6 = dict(spinach = 1.39, cabbage = 2.59)
print(dict6) # {'spinach': 1.39, 'cabbage': 2.59}
字典的创建方法不止于此,在这里不再赘述。
0x02 访问字典元素
在字典中,访问元素与字典的方式不同,是通过key来访问对应的value的。
scores = {'语文': 89, '数学': 92, '英语': 93}
print("语文成绩是", scores["语文"])
print("科学成绩是", scores["科学"]) # 字典中不存在,因此会报错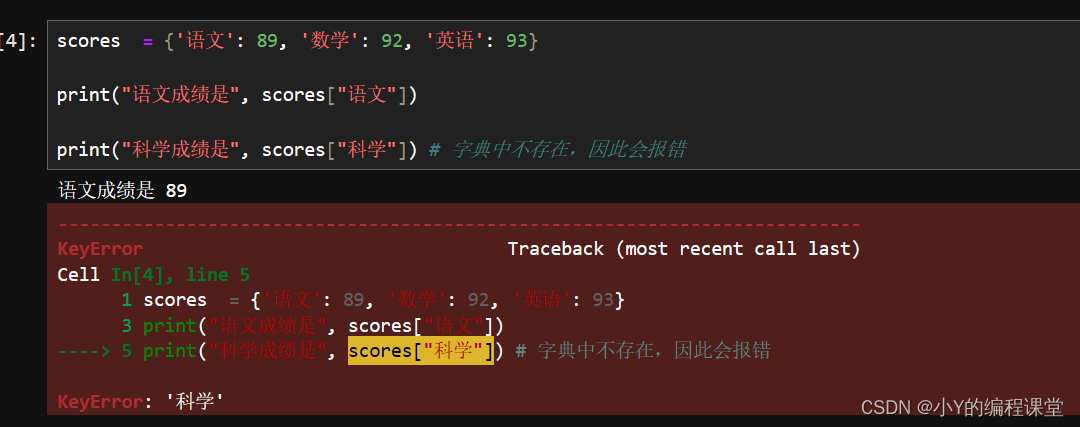
0x03 修改与添加字典元素
如果要为 dict 添加或修改 key-value 对,只需为 key 赋值即可:
scores = {'语文': 89, '数学': 92, '英语': 93}
scores["科学"] = 91 # 添加一个新的key-value 对
print(scores)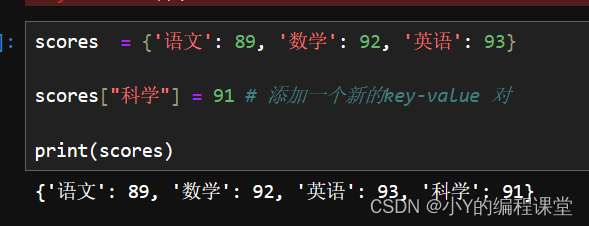
0x04 删除字典元素

如果要删除宇典中的 key-value 对,则可使用 del 语句。例如如下代码:
scores = {'语文': 89, '数学': 92, '英语': 93}
# 使用del语句删除key-value对
del scores['语文']
del scores['数学']
print(scores) 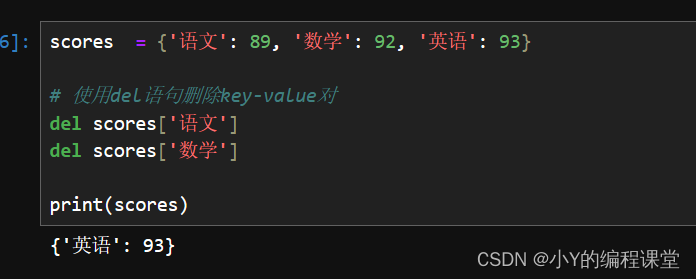
0x05 判断元素是否在字典中
如果要判断字典是否包含指定的 key,则可以使用 in 或 not in 运算符。需要指出的是,对于 dict 而言,in 或 not in 运算符都是基于 key 来判断的。例如如下代码:
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 判断cars是否包含名为'AUDI'的key
print('AUDI' in cars) # True
# 判断cars是否包含名为'PORSCHE'的key
print('PORSCHE' in cars) # False
print('LAMBORGHINI' not in cars) # True0x06 字典的常用方法
字典由 dict 类代表,因此我们同样可使用 dir(dict) 来查看该类包含哪些方法。在交互式解释器中输入 dir(dict) 命令,将看到如下输出结果:

我们可以使用help函数获取各个方法的帮助
 因此我在这里也就不在讲了。
因此我在这里也就不在讲了。
Ⅱ. 冒泡排序
就目前而言,我们已经学会了python里的基本数据结构,
是时候来学习一些算法了。

0x00 什么是冒泡排序
冒泡排序(Bubble Sort),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
emmm....听不懂....

无妨
0x01 冒泡排序的原理
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
0x02 动手实现
我们可以看完原理,大概知道冒泡排序一个是两层循环
内部有一个比较,如果违反顺序就交换两个元素
所以伪代码应该是这样的
l = [...]
length = len(l)
for i in 0...length
for j in 0...length
if l[j] > l[j+1]
l[j], l[j+1] = l[j+1], l[j]我们用代码来实现吧
l = [6,4, 3, 2,1]
length = len(l)
for i in range(length):
for j in range(length-1):
if l[j] > l[j+1]:
l[j], l[j+1] = l[j+1], l[j]0x03 算法分析
时间复杂度
略,为避免劝退新手
算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,是不会再交换的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
0x04 优化刚才的算法
我们给刚才的代码添加一个累加器,来计算一共交换了多少次
l = [6,4, 3, 2,1]
length = len(l)
ax = 0
for i in range(length):
for j in range(length-1):
if l[j] > l[j+1]:
l[j], l[j+1] = l[j+1], l[j]
ax += 1
print(ax)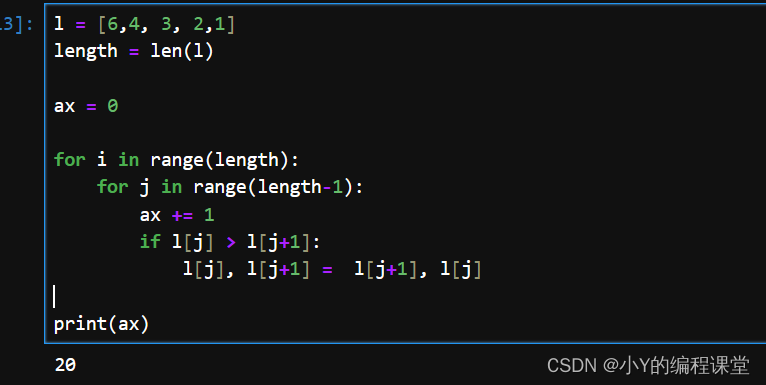
可以看到一共循环来20次
但是就算排序已经没有问题了,却还需要比较20次
因此我们可以添加一个变量,来看这次第一层循环里有没有发生比较,没有发生就返回
并且在里面还可以的range(length-1)中还可以减去i
下面是我们的最终版本:
l = [6,4, 3, 2,1]
length = len(l)
for i in range(length):
b = False
for j in range(length-i-1):
if l[j] > l[j+1]:
l[j], l[j+1] = l[j+1], l[j]
b = True
if not b: break
print(l)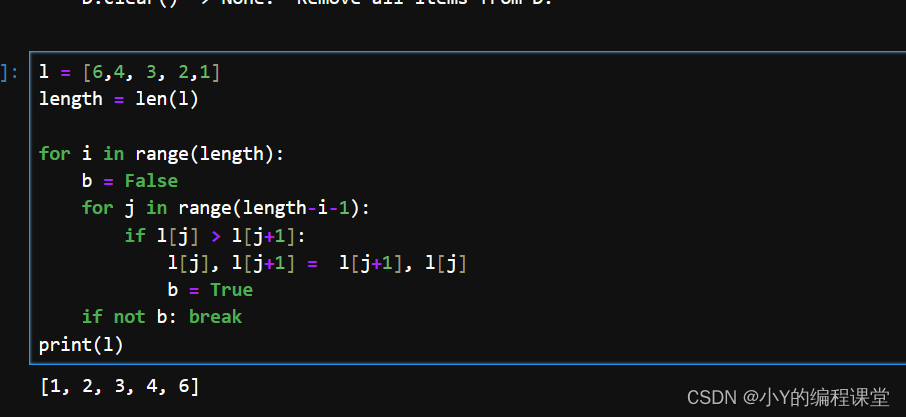

拜拜















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









