






目录
概要:
程序语言:python
第三方库:requests,BeautifulSoup
爬取网站:抗战:满级悟性,开局手搓AK_老战归来小说_全本小说下载_飞卢小说网
单章小说
1.发送请求,获取数据
# 数据请求模块
import requests
# 模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
# 请求链接
url = 'https://b.faloo.com/1328711_1.html'
# 发送请求
requests = requests.get(url=url, headers=headers)
print(requests.text)
结果如下图所示
2.解析数据
打开开发者工具( F12 / fn+f12 / ctrl + shift + i),点击小箭头,选中我们需要获取的元素,
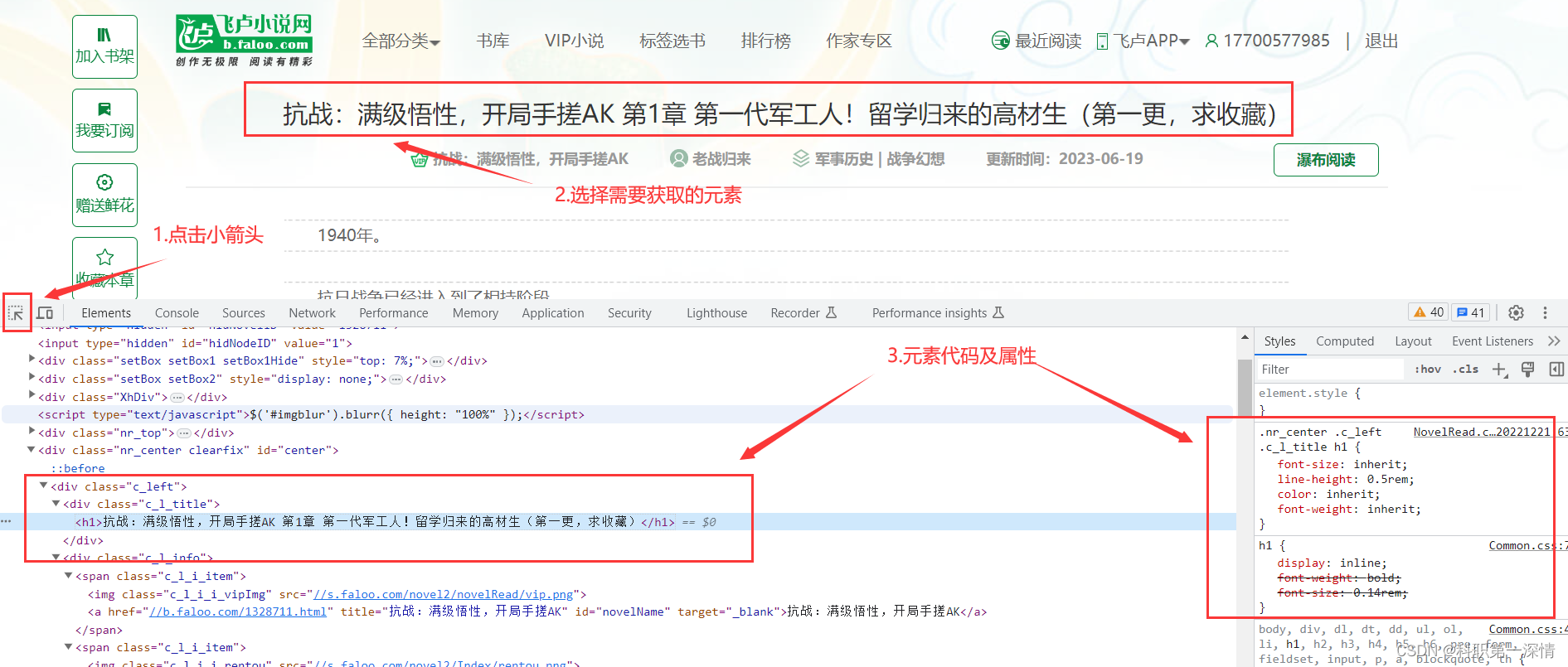
找到我们需要的数据
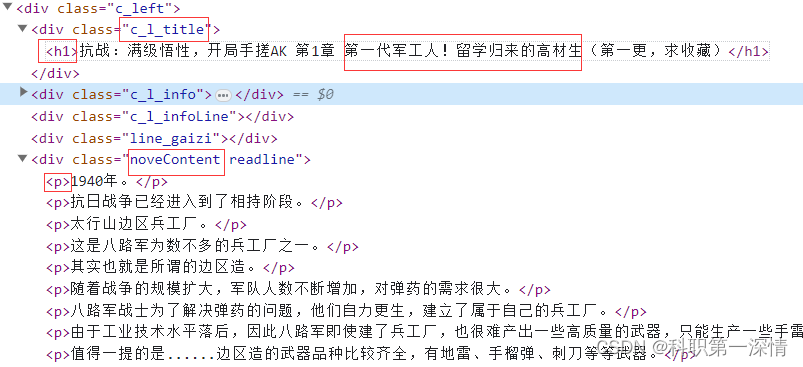
通过BeautifulSoup解析数据
# 数据解析模块
from bs4 import BeautifulSoup
# 使用BeautifulSoup解析数据
soup = BeautifulSoup(requests.text, 'html.parser')
# 提取标题
full_title = soup.select_one('.c_l_title h1').text.strip()
title = full_title.split('第', 1)[1] # 使用 split() 方法分割字符串,并选择第二个元素作为标题
# 提取小说内容
content = soup.select('.noveContent p')
chapter_content = '\n'.join([p.text.strip() for p in content])保存数据
# 数据持久化
with open('第'+title + '.txt', mode='a', encoding='UTF-8') as f:
f.write(f"章节名:第{title}\n") # 前面添加 "第" 字
f.write(f"内容:{chapter_content}\n")整本小说
既然知道怎么爬取单章小说了,那么只需要获取小说所有的url地址,就可以爬取全部小说内容了

我们可以看到所有的url地址都在DivTd 标签当中,但是这个url地址省略了‘https:’,是不完整的url,所以爬取下来的时候,要拼接url地址。
# 数据请求模块
import requests
from bs4 import BeautifulSoup
def get_chapter_urls(url):
# 发送请求
response = requests.get(url)
# 创建BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
# 获取章节url
chapters = soup.select('.DivTd a')
for chapter in chapters:
# 拼接章节URL
chapter_url = 'https:' + chapter['href']
print(chapter_url)
url = 'https://b.faloo.com/1328711.html'
get_chapter_urls(url)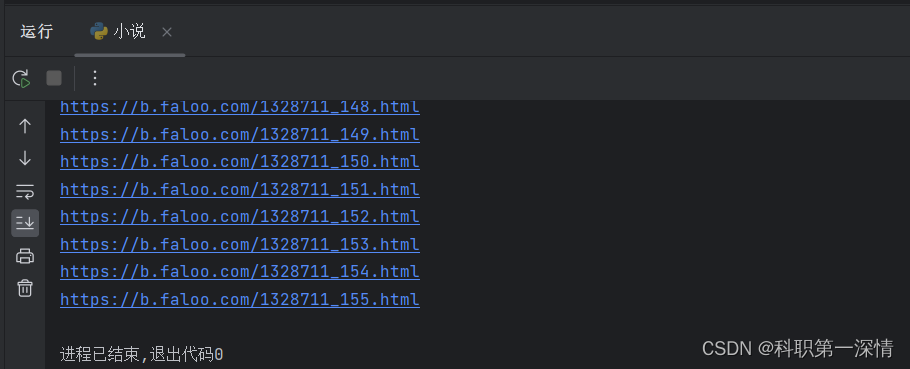
完整代码
import requests
from bs4 import BeautifulSoup
def get_chapter_urls(url):
# 发送请求
response = requests.get(url)
# 创建BeautifulSoup对象
soup = BeautifulSoup(response.text, 'html.parser')
# 获取小说名字
novel_name = soup.select_one('#novelName').text.strip()
print(f"小说名称:{novel_name}\n")
# 获取章节名字和url
chapters = soup.select('.DivTd a')
chapter_list = []
for chapter in chapters:
# 拼接章节URL
chapter_url = 'https:' + chapter['href']
# 获取完整的章节标题
chapter_title = chapter['title']
# 提取 "第" 字后面的部分作为新的章节标题
chapter_title = chapter_title.split('第', 1)[1]
# 将小说名称、章节标题和章节URL加入到章节列表中
chapter_list.append((novel_name, chapter_title, chapter_url))
return chapter_list
def save_chapter_content(novel_name, chapter_title, chapter_content):
with open(f"{novel_name}.txt", mode='a', encoding='UTF-8') as f:
f.write(f"章节:第{chapter_title}\n")
f.write(f"内容:\n{chapter_content}\n\n")
def get_novel(url):
# 调用get_chapter_urls函数以获取章节URL列表
chapter_list = get_chapter_urls(url)
for novel_name, chapter_title, chapter_url in chapter_list:
# 发送请求以获取章节内容
chapter_response = requests.get(chapter_url)
# 使用BeautifulSoup解析响应文本
chapter_soup = BeautifulSoup(chapter_response.text, 'html.parser')
# 从解析结果中提取章节内容
chapter_content = chapter_soup.select_one('.noveContent').text.strip()
# 调用save_chapter_content函数保存章节内容
save_chapter_content(novel_name, chapter_title, chapter_content)
print(f"已保存章节:{chapter_title}")
print("全部章节保存完成!")
url = 'https://b.faloo.com/1328711.html'
get_novel(url)















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









