







想看小说,不想看花里胡哨的网页,想着爬下来存个txt,顺便练习一下爬虫。
随便先找了个看起来格式比较好的小说网站《飞卢小说网》做练习样本,顺便记录一下练习成果。
ps:未登录,不能爬取VIP章节部分
目录
使用工具
python3 ,beaufulsoup库,request库
网页结构分析
随便在网站找了个小说,分析网页结构:
https://b.faloo.com/f/479986.html 以此页为例,可以发现,目录页全部整齐的在后面加上了章数https://b.faloo.com/p/479986/4.html
这里不用更换网址的方法,选用 找到存放目录的a标签,逐一获取链接的方式 练习。
首先,分析目录页结构,对元素右键进行检查
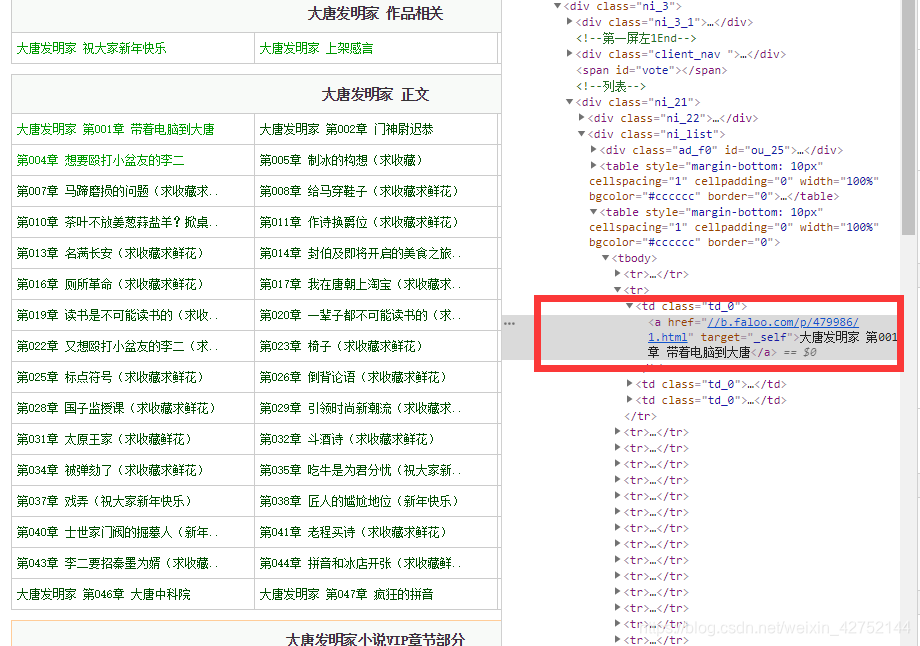
可以发现,目录链接全部存放在table里,很整齐的在类名为td_0的td中;
接着分析每节内容ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









