






目录
论文简介与作者
一句话简介
一种多尺度随机分布预测(MSDP)算法来学习鲁棒的用户行为序列表示
作者

背景介绍(当前研究的不足)
以往的方法(不足之处):
训练大量未被标注的用户行为序列,使用自监督的随机标记(随机预测/自回归预测一些标记的行为),但是这种并没有考虑到用户行为本身,文本序列遵循人类语言的语言准则,几乎没有噪声和随机信号,随机性低,但用户行为(反复点击,购买)相反。噪声和随机性的干扰,标记行为预测和下一次标记行为预测任务的难度显著增加,影响了学习用户表示的鲁棒性。
新方法
- 设置自监督学习任务,实现从用户行为序列的鲁棒表示
- 在训练阶段采用随机策略预测用户在多个不同时段(例如未来5天,10天或30天)的总体行为分布(MSDP)。
- 引入了对比正则化项(Contrastive Regularization—标记与未标记的相似性最大化)。
用户序列分类方法
常用的用户序列分类方法
-
标记行为预测MBP
- 预测序列中的标记,例如[5,13],标记u,预测r是否来自u
-
下一行为预测NBP
- 预测𝑘 未来的token[15,18],最大化了𝑢,预测下一行为 {𝑟1, . . . , 𝑟𝑘 }.
- 行为序列的整体表示𝑢 通过最大化MBP和NBP的可能性之和来学习。
-
对比学习建模,扩充原始数据构建自监督信号
-
权重共享网络,最大化嵌入的相似性
我们的方法
- 为了避免短期行为噪声,预测一定时间段内的长期用户行为𝑠𝑡 = {𝑥1, 𝑥2, . . . , 𝑥𝑡−1, 𝑥𝑡 }
- 为了降低复杂性,预测从下一个时间窗口采样的几个用户行为𝑘 天
- 基于分布一致性假设,最大化Kullback–Leibler散度(之前与未来)
- 多任务提示训练:我们采用了一种即时训练方法,随机采样不同尺度的预测时间窗口𝑊1, 𝑊2, 𝑊3,,作为模型训练的提示。
符号定义与公式
过程图:

用户行为嵌入—》不同序列模型的相似度提取(正则化)—》随机窗口采样---》分布预测
相似函数
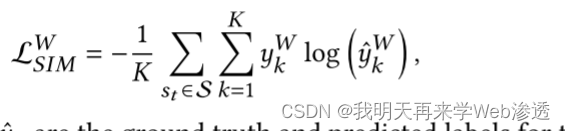
![]() 真实值,
真实值,![]() 表示由行为序列表示学习模型生成的输出
表示由行为序列表示学习模型生成的输出
随机窗口大小
我们随机采样𝑁 窗口大小𝑊 从连续时域中的均匀分布𝑊 [𝑊𝑚𝑖𝑛,𝑊𝑚𝑎𝑥]
Constrastive正则化
将标记的用户序列![]() 的
的![]() 与未标记序列
与未标记序列![]() 的
的![]() 的余弦相似度最大化
的余弦相似度最大化
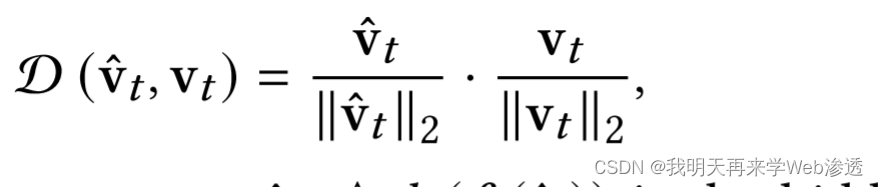
其中,‖·‖2是ℓ2-范数𝑡 ≜ ℎ (𝑓 ( ˆ𝑠𝑡 )) 是随机标记行为序列的隐藏层表示,v𝑡 ≜ ℎ (𝑓 (𝑠𝑡 )) 是未标记序列的行为序列表示𝑠𝑡 .
目标函数
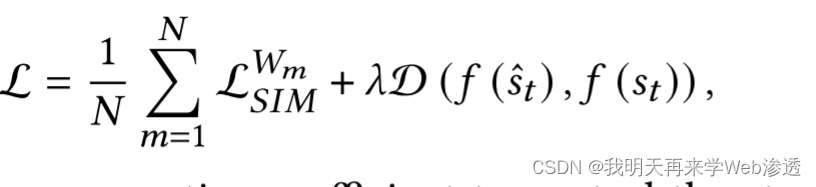
由前面的相似函数和Constrastive正则化函数结果相加,其中𝜆 是控制对比正则化强度的非负系数。
下游任务预测
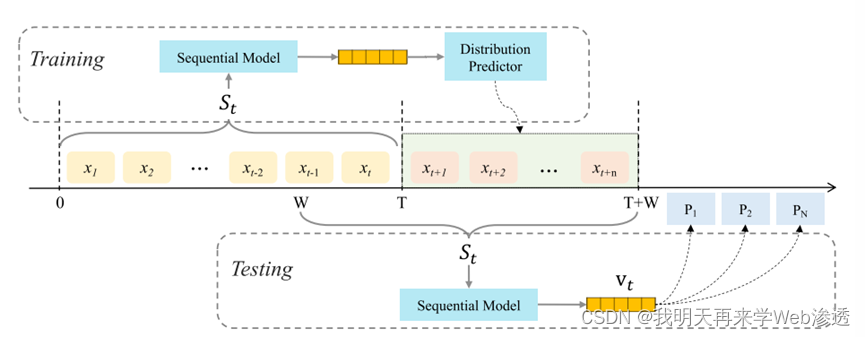
利用(0,T]时段数据预测![]() ,W为随机选取的窗口大小
,W为随机选取的窗口大小
下流任务![]() ,时间
,时间![]() ,
,
预测![]()
实验
实验配置
- 使用具有与特征提取器相同超参数的转换器编码器
- 使用预训练模型的用户表示向量输出作为输入
- 使用具有两个完全连接层(512-256)的DNN作为模型结构
数据集
2个数据集:
- 逾期风险(O-risk)管理数据集,其中下游任务是未来的用户𝑘 天预测Alipay12的逾期风险。该数据集包含用户在支付宝上的所有金融活动,包括消费、贷款和还款等。
- 电子商务行为数据集天猫,根据90天内用户的购买分布,下游任务:以预测未来用户感兴趣的商品类别。
对比方法(4条基线):
设置4条基线进行比较
将模型性能与3个经典基线和1个最新基线进行了比较。
- MBP和NBP基线(BERT4Rec和PTUM)
- 两种不同方法的SOTA方法(基于对比学习的无监督用户行为表示方法,与我们最相似的行为分布预测方法)---UserBERT,SUMN,static-DP
- Multi-task baselines(Multi-task SUMN,Multi-task Distribution Prediction (MTDP))
- 对比正则化消融(CR)
评估指标
ACC(准确性)和KS(Kolmogorov-Smirnov)
结果论述
1.分布预测的影响
2.多尺度随机提示训练的效果
3.收缩正则化的影响
4.工业应用结果
个人总结
- 训练任务不同:将未来一段时间的行为分布预测作为预训练任务
- 预训练方法:多尺度随机提示训练(不同尺度窗口提示)(MSDP)
- 基于对比学习的对比规则化
备注
以上仅为本人对此文章的看法,文章中的“我们”指代论文作者,详细可以自行查看原文章哦~。本人认知、科研水平有限,欢迎交流。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









