






 本文介绍了一种新型的序列分类模型——时间注意门控模型(TAGM),它结合了注意力机制和门控递归网络,有效处理有噪声或未分段的序列。通过时间注意力和循环注意力,模型能自动定位相关观察并忽略噪声,优于传统模型如LSTM和GRU。实验结果表明,TAGM在语音识别、情绪分析和事件识别任务中表现出色,且具有可解释性和更好的参数效率。
本文介绍了一种新型的序列分类模型——时间注意门控模型(TAGM),它结合了注意力机制和门控递归网络,有效处理有噪声或未分段的序列。通过时间注意力和循环注意力,模型能自动定位相关观察并忽略噪声,优于传统模型如LSTM和GRU。实验结果表明,TAGM在语音识别、情绪分析和事件识别任务中表现出色,且具有可解释性和更好的参数效率。
目录
循环注意力(Recurrent Attention-Gated Units)
时间注意力(Temporal Attention Module)
端到端的参数学习(End-to-End Parameter Learning)
A. Attention Module + Neural Network (AM-NN).
B. Discriminative Graphical Models
简介与作者
一句话简介:
鲁棒序列分类的TAGM模型(时间注意门控模型)
关键词
序列分类、注意力模型、递归网络
作者

背景(问题与解决):
以往的序列分类:手动去除或者忽视/规避噪声而进行序列分类。
我们提出了
时间注意力门控模型(TAGM),它集成了注意力模型和门控递归网络的思想,以更好地处理有噪声或未分段的序列。具体:
- 扩展了注意力模型的概念,以测量序列的每个观察(时间步长)的相关性
- 使用一种新的门控递归网络来学习最终预测的隐藏表示
以往:
一种流行的序列分类方法是门控递归网络,如门控递归单元(GRU)和长短期记忆(LSTM)
问题:
使用门(例如,LSTM模型中的输入门)来平衡当前和先前的时间步长。矢量门被单独应用于信息流的每个维度,因此很难解释输入时间观测值(即时间步长)的相对重要性。序列观测的哪一个子集对分类任务最显著?不得而知。。。
另一种方法是采用基于注意力的机制,将个人注意力得分应用于每个观察(时间步长),从而实现更好的可解释性。
我们的优点:
- TAGM的注意力模块自动定位与最终决策相关的显著观察结果,并忽略输入序列中不相关(有噪声)的部分。
- 创建了一个新的递归神经单元,可以根据注意力得分学习更好的序列隐藏表示
- 与传统的门控递归模型(如LSTM)相比,我们的模型减少了参数的数量,这导致更快的训练和推理
- 能够推广到计算机视觉、语音识别和自然语言处理
Tips(前置知识汇总):
这里插入序列分类、注意力模型和递归网络(会了可以跳过hh)
序列分类(传统的序列分类模型)
-
生成模型
- 侧重于学习基于生成模型的有效中间表示。这些方法通常基于隐马尔可夫模型(HMM)
-
判别模型
其对以输入数据为条件的所有类别标签上的分布进行建模。条件随机场(CRF)是序列标记的判别模型,旨在为每个序列观察分配一个标记。
缺点:观测值和标签之间的线性映射不能对复杂的决策边界进行建模,这会产生许多非线性CRF变体。
序列分类的缺点:
专门为分割良好的序列设计的,因此不能很好地处理有噪声或未分割的序列。
注意力模型
定义:测量输出对输入方差的敏感性,选择性地关注输入的某些相关部分
优势:我们的TAGM是第一个在序列时域中使用注意力机制的端到端递归神经网络,其额外优势是在每个时间步长(序列观察)其时间显著性指标(即时间注意力)的可解释性
递归网络
定义:通过考虑当前时间步长的观测和前一时间步长的表示来学习每个时间步长的表达。
为了解决普通RNN在处理长序列时的梯度消失问题,提出了LSTM[11]和GRU[4]。它们配备了门,以动态平衡来自前一时间步长和当前时间步长的信息流。
优势:还采用了一个门来过滤掉有噪声的时间步长,并保留显著的时间步长,门值来自注意力模块。
符号定义与公式
目标:
- 计算输入序列中每个时间步长观测的显著性得分
- 基于显著性得分构建最适合序列分类任务的隐藏表示
顶部为循环注意力门控单元,底部是时间注意力模块

循环注意力(Recurrent Attention-Gated Units)
-----和前面几篇的RNN过程类似
对于输入![]() 时间步长t的隐藏状态ht计算如下,
时间步长t的隐藏状态ht计算如下,
![]() 其中
其中![]() 为注意力得分,能够平衡当前状态和前一状态的信息流(对于最后的取舍很重要)
为注意力得分,能够平衡当前状态和前一状态的信息流(对于最后的取舍很重要)
例如:高关注值会促使模型更多地关注当前隐藏状态ht和输入特征xt。
![]() 是在当前时间步长中完全包含输入信息xt的候选隐藏状态值
是在当前时间步长中完全包含输入信息xt的候选隐藏状态值
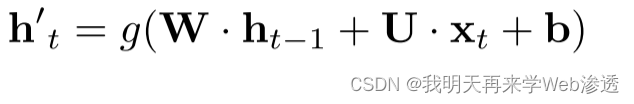
其中,W, U分别是先前和当前时间步长的线性变换参数,而b是偏置项。我们使用校正线性单元(ReLU)作为激活函数g。
最后一个时间步长ht, 送到最终分类器, softmax函数,以执行分类任务, 将K个类别中的预测标签yk的概率计算:
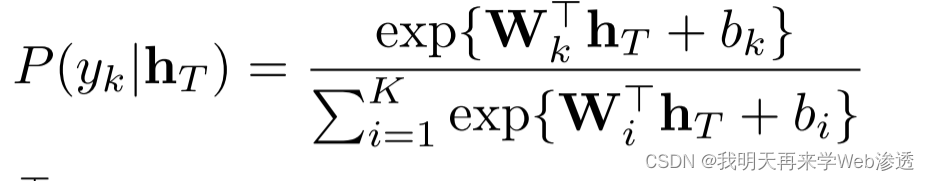
其中,wi和bi是指计算第i个类的线性映射得分的参数。
时间注意力(Temporal Attention Module)
目标:估计每个序列观测的显著性和相关性(其实是为前面的[1]循环注意力服务)
使用双向RNN,
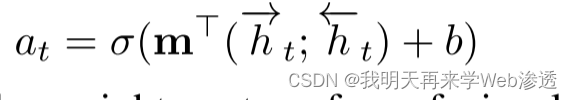
其中,m是我们的融合层的权重向量,它集成了我们的双向RNN的两个方向层,b是偏置项。激活函数σ,以将注意力权重约束在[0,1]之间。
![]() 是双向RNN模型的隐藏表示
是双向RNN模型的隐藏表示

ReLU函数用作激活函数g
端到端的参数学习(End-to-End Parameter Learning)
训练集![]()
![]()
![]() 为标签,
为标签,![]() 为第n个样本第t步长的观测值。
为第n个样本第t步长的观测值。
最小化训练数据相对于参数的条件负对数似然来联合学习两个TAGM模块(时间注意力模块和循环注意力门控单元),最终序列分类器。
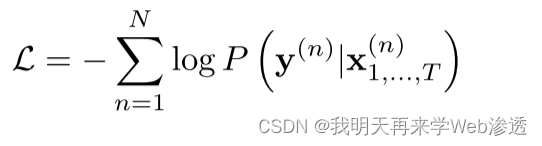
通过时间算法使用反向传播,损失依次通过顶部递归注意力门控单元和时间注意力模块反向传播。
模型比较(LSTM , GRU)
- 只关注一个标量注意力得分来测量当前时间步长的相关性。--可解释的显著性检测
- 将注意力建模和递归隐藏表示学习分离为两个独立的模块。---定制特定的递归结构
- 使用双向RNN考虑时间注意力模块中序列的前一个和后一个信息
- 只包含一个标量门,即注意力门(LSTM3个,GRU2个)
- 包含更少的参数
实验
共同处理部分:
所有递归网络(TAGM、GRU、LSTM和普通RNN),通过使用验证集从选项集{64,128,256}中选择最佳配置来调整隐藏单元的数量。
从选项集{0.0、0.25、0.5}验证丢弃值。
使用RMSprop作为梯度下降优化算法,梯度裁剪在-5和5之间。
音频数据集上的语音识别
我们首先在由阿拉伯语口语数字数据集[9]构建的修改数据集上进行初步实验

与3种基线模型比较:
A. Attention Module + Neural Network (AM-NN).

V是特征加权和,h传递到softmax层来执行序列分类。
B. Discriminative Graphical Models

C. Recurrent neural networks.
结果分析:
(准确率更优,还设置了无噪声 和手动噪声组排除干扰)

可推广性与不同大小的训练数据进行比较。
 改变数据集大小即可。
改变数据集大小即可。
序列显著性检测。
可视化了在有噪声的阿拉伯数据集上训练的模型的注意力权重

文本数据集的情绪分析

指标如上:
结果分析
(呃,一大段都是在讲优于其他模型的,事实上这也是实验的意义。)
分级性能评估
这个图(正确预测和错误预测情况下,注意力权重可视化,颜色越深分数越小)

序列显著性检测
视频数据集上事件识别
![]()

我们对训练集和测试集使用相同的分割:4659个视频作为训练集,4658个作为测试集。
我们选择使用具有相同设置的CNN特征,即预训练的AlexNet模型的第七个全连接层的输出(4096维)[19]。为了计算效率,我们以1/8的采样率提取CNN特征。
采用平均精度(mAP)作为评估指标
分类函数使用sigmoid函数
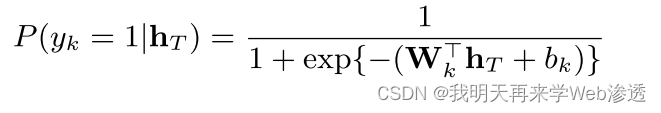
最小化了K个类别上的联合二进制交叉熵

结果分析:
基线比较:
与BOW-SVM(采用一对一策略为每个事件训练单独的分类器)比较
序列显著性:
使用示例的map评估

个人总结:
- 提出了时间注意门控模型(TAGM)
- 受到注意力模型和门控递归网络的启发,能够检测序列的显著部分,同时忽略不相关和有噪声的部分。
- 学习的注意力得分为最终决策提供了对每个时间步长观察的相关性的物理意义解释
备注
以上仅为本人对此文章的看法,文章中的“我们”指代论文作者,详细可以自行查看原文章哦~。本人认知、科研水平有限,欢迎交流。















 3313
3313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









