






目录
4.4 从字典的ndarrays /列表创建DataFrame
一、Python Pandas 环境搭建
windows
如果您安装了Python
pip install pandasLinux
各个Linux发行版的软件包管理器用于安装一个或多个SciPy栈的软件包。
对于Ubuntu用户
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipythonnotebook
python-pandas python-sympy python-nosePython
Copy
对于 Fedora 用户
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy
python-nose atlas-devel二、Python Pandas 数据结构简介
Pandas处理以下三种数据结构:
- Series
- DataFrame
- Panel
这些数据结构建立在Numpy数组之上,意味着它们的运行速度很快。
2.1 维度与描述
最好的理解这些数据结构的方式是将高维数据结构看作是低维数据结构的容器。例如,DataFrame是Series的容器,Panel是DataFrame的容器。
| 数据结构 | 维度 | 描述 |
|---|---|---|
| Series | 1 | 一维带标签的同质数组,大小不可变。 |
| Data Frames | 2 | 通用的二维带标签,大小可变的表格结构,其中列的类型可能不同。 |
| Panel | 3 | 通用的三维带标签,大小可变的数组。 |
构建和处理二维或多维数组是一项繁琐的任务,用户在编写函数时需要考虑数据集的方向,但使用Pandas数据结构可以减少用户的心力。
例如,对于表格数据(DataFrame),更有语义意义的是考虑行(索引)和列,而不是轴0和轴1。
可变性
所有Pandas数据结构都是可变的(可以更改),除了Series之外,所有其他结构的大小都是可变的。Series的大小是不可变的。
注意 - DataFrame被广泛使用,是最重要的数据结构之一。Panel的使用较少。
2.2 Series
Series是一个一维数组-like的结构,具有同质数据。例如,以下系列是一组整数10、23、56,…
关键要点
- 同质数据
- 尺寸不可变
- 数据值可变
2.3 DataFrame
DataFrame是一个二维数组,包含异质数据。例如,
| Name | Age | Gender | Rating |
|---|---|---|---|
| Steve | 32 | Male | 3.45 |
| Lia | 28 | Female | 4.6 |
| Vin | 45 | Male | 3.9 |
| Katie | 38 | Female | 2.78 |
该表格代表了一个组织中销售团队的数据以及他们的整体绩效评级。数据以行和列的方式呈现,每列代表一个属性,每行代表一个人。
列的数据类型
四列的数据类型如下:
| Column(列) | Type |
|---|---|
| Name | String |
| Age | Integer |
| Gender | String |
| Rating | Float |
关键点
- 异构数据
- 大小可变
- 数据可变
2.4 Panel
Panel是一个具有异构数据的三维数据结构。用图形表示面板是困难的。但可以将面板看作是DataFrame的容器。
关键点
- 异构数据
- 大小可变
- 数据可变
三、Python Pandas Series
Series是一个一维的带标签的数组,可以容纳任何类型的数据(整数、字符串、浮点数、Python对象等)。轴标签统称为索引。
3.1 pandas.Series
可以使用以下构造函数创建pandas Series-
pandas.Series( data, index, dtype, copy)
Python
Copy
构造函数的参数如下:
| 序号 | 参数和描述 |
|---|---|
| 1 | data 数据可以是ndarray、列表、常量等形式 |
| 2 | index 索引值必须唯一且可哈希,长度与数据相同。如果没有传递索引,则默认为 np.arrange(n) |
| 3 | dtype 数据类型。如果为None,则会推断数据类型 |
| 4 | copy 复制数据。默认为False |
np.arrange() :生成一维数组
一系列可以使用各种输入来创建,如−
- 数组
- 字典
- 标量值或常数
3.2 创建一个空系列
可以创建一个基本系列,即一个空系列。
import pandas as pd
s = pd.Series()
print(s)它的输出如下所示:
Series([], dtype: float64)3.3 从np.array创建Series
如果数据是np.array,则传入的索引必须具有相同的长度。如果没有传入索引,则默认索引会是 range(n) ,其中 n 是数组的长度,即[0,1,2,3… range(len(array))-1]
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data)
print(s)运行结果:
0 a
1 b
2 c
3 d
dtype: objectnp.array 用于创建一个新的NumPy数组对象。其语法如下:
np.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)object:任何可用于初始化新数组的对象,例如列表、元组、数组等。dtype:新数组的数据类
实例:
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([[1, 2],[3,4]])
print(a)
print("-"*50) #分割
print(b)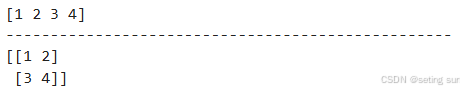
另外,我们可以设置索引值
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d'])
s = pd.Series(data,index=[100,101,102,103])
print s运行结果:
100 a
101 b
102 c
103 d
dtype: object3.4 从字典创建一个系列
字典 可以作为输入传递,如果没有指定索引,则按字典键的排序顺序构建索引。如果传递了 索引 ,则会提取与索引标签对应的数据值。
实例1:
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data)
print s运行结果:
a 0.0
b 1.0
c 2.0
dtype: float64实例2(添加索引):
import pandas as pd
import numpy as np
data = {'a' : 0., 'b' : 1., 'c' : 2.}
s = pd.Series(data,index=['b','c','d','a'])
print s运行结果:
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64如上所示:当输入没有的索引将会用NaN表示
3.5 从标量创建 Series
如果数据是一个标量值,必须提供一个索引。该值将被重复以匹配 索引 的长度
实例:
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[0]) #索引第一个元素
print("-"*50) #分割线
print(s[:3])#索引三之前的元素
print("-"*50)
print(s[-3:])#索引最后三个元素运行结果:

3.6 使用标签(索引)检索数据
Series 类似于一个固定大小的 字典 ,您可以通过索引标签来获取和设置值。
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s['a'])#索引单个元素
print("-"*50) #分割线
print(s[['a','c','d']])#索引多个元素
print("-"*50) #当索引不存在会发生异常
print(s['f'])运行结果:

![]()
四、Python Pandas DataFrame
DataFrame是一个二维数据结构,即数据以行和列的方式以表格形式对齐。
4.1 DataFrame的特点
- 可能存在不同类型的列
- 大小可变
- 带有标签的轴(行和列)
- 可以对行和列进行算术运算
结构:
让我们假设我们正在创建一个学生数据的DataFrame。
你可以把它看作是一个SQL表或者一个电子表格的数据表示。
4.2 pandas.DataFrame
可以使用以下构造器创建pandas DataFrame:
pandas.DataFrame( data, index, columns, dtype, copy)构造函数的参数如下所示:
| 序号 | 参数和描述 |
|---|---|
| 1 | 数据(data) 数据可以是各种形式,如ndarray、series、map、lists、dict、constants和另一个DataFrame。 |
| 2 | 索引(index) 用于行标签的索引,如果没有传递索引,则默认为np.arange(n)。 |
| 3 | 列标签(columns) 用于列标签的可选默认语法是np.arange(n),仅当没有传递索引时才成立。 |
| 4 | 数据类型(dtype) 每列的数据类型。 |
| 5 | 复制(copy) 如果默认值为False,则用于复制数据的命令(或其他命令)。 |
4.3 创建DataFrame
可以使用不同的输入来创建pandas DataFrame,如−
- 列表
- 字典
- 系列
- Numpy ndarrays
- 另一个DataFrame
创建一个空的DataFrame
import pandas as pd
df = pd.DataFrame()
print(df)运行结果:
Empty DataFrame
Columns: []
Index: []从列表创建DataFrame(例1):
import pandas as pd
data = [1,2,3,4,5]
df = pd.DataFrame(data)
print(df)运行结果: (提示:0~4为行标,0为列标)

例2(设置columns(列标签)):
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'])
print(df)运行结果:
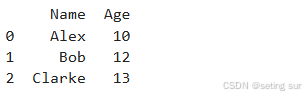
4.4 从字典的ndarrays /列表创建DataFrame
所有的 ndarray 必须具有相同的长度。如果传递了索引,则索引的长度应与数组的长度相等。
如果不传递索引,则默认情况下,索引将是range(n),其中 n 是数组的长度。
例1(通过字典不用列标签也可以达到同样效果):
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data)
print(df)运行结果:

例2(设置index(索引)提高可读性):
import pandas as pd
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4'])
print(df)运行结果:
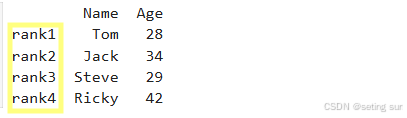
例3(列表里多个字典):
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data, index=['first', 'second'])
print(df)运行结果:
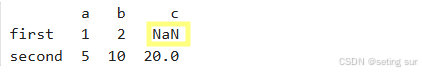
如果元素缺失将会NaN填充
4.5 从Series字典创建DataFrame
可以将Series字典传递给构建DataFrame。结果索引是传递的所有Series索引的并集。
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df)运行结果:
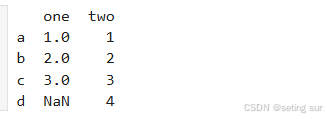
4.6 行选择、添加和删除
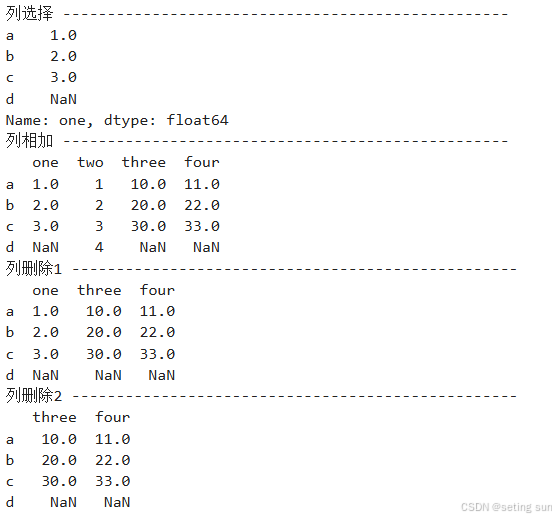
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
#添加列
df['three']=pd.Series([10,20,30],index=['a','b','c'])
print('列选择','-'*50) #分割线
#选择列
print(df['one'])
print('列相加','-'*50) #分割线
#列相加
df['four']=df['one']+df['three']
print(df)
print('列删除1','-'*50) #分割线
#列删除,删除two
del df['two']
print(df)
print('列删除2','-'*50) #分割线
#删除one是否会报错?
del df['one']
print(df)运行结果:
五、Python Pandas 面板(Panel)
面板(Panel) 是一个3D的数据容器。术语 面板数据(Panel data) 来自计量经济学,部分地构成了Pandas这个名称 – pan(el)-da(ta) -s。
这3个轴的名称旨在为描述涉及面板数据的操作提供一些语义意义。它们是:
- items(项) - 轴0,每个项都对应一个包含其中的DataFrame。
-
major_axis(主轴) - 轴1,它是每个DataFrame的索引(行)。
-
minor_axis(次轴) - 轴2,它是每个DataFrame的列。
5.1pandas.Panel()
可以使用以下构造函数创建一个Panel –
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
Python
Copy
构造函数的参数如下-
| 参数 | 描述 |
|---|---|
| data | 数据可以是ndarray,series,map,lists,dict,constants以及另一个DataFrame形式 |
| items | 按axis=0排列 |
| major_axis | 按axis=1排列 |
| minor_axis | 按axis=2排列 |
| dtype | 每列数据的数据类型 |
| copy | 复制数据。默认值为 false |
在较新的版本的Pandas中,类已被弃用并从Pandas库中移除,所以这里只做简单了解,先跳过这一部分,可在Matplotlib中进行系统性学习;

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









