






目录
Hadoop思维导图

(一)Hadoop部署模式
1、独立模式
- 在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
2、伪分布式模式
- 在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
3、完全分布式模式
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
(二)Hadoop集群规划
- 本课程将以前面安装的虚拟机为例,阐述完全分布模式Hadoop集群的安装与配置方法。当前规划的Hadoop集群包含一台主节点和两个从节点。
1、集群拓扑
- 一个主节点,两个从节点

2、角色分配
- 完全分布式Hadoop集群搭建需要在集群的每个节点都安装Hadoop,集群角色分配如下表所示。
| 节点 | 角色 |
|---|---|
| master | NameNode, DataNode |
| slave1 | DataNode |
| slave2 | DataNode |
(三)JDK安装与配置
- 由于Hadoop是由Java语言开发的,Hadoop集群的使用依赖于Java环境,因此安装Hadoop集群之前,需要先安装并配置好JDK。
1、下载JDK压缩包
- 下载链接:https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/otn/java/jdk/8u341-b10/424b9da4b48848379167015dcc250d8d/jdk-8u341-linux-i586.tar.gz(需要登录Oracle官网才能下载)
2、上传到master虚拟机
- 将JDK压缩包上传到master虚拟机/opt目录

- 查看上传的JDK压缩包


3、在master虚拟机上安装配置JDK
- 执行命令:tar -zxvf jdk-8u341-linux-x64.tar.gz -C /usr/local,将JDK压缩包解压到指定目录

- 执行命令:ll /usr/local/jdk1.8.0_341,查看解压之后的jdk1.8.0_341目录

- 执行命令:vim /etc/profile,配置环境变量

1.export JAVA_HOME=/usr/local/jdk1.8.0_341
2.export PATH=$JAVA_HOME/bin:$PATH
3.export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 存盘退出(:wq!),执行命令:source /etc/profile,让配置生效

- 查看JDK版本

- 为了解决问题,需要执行命令:yum -y install glibc.i686

- 执行命令:java -version
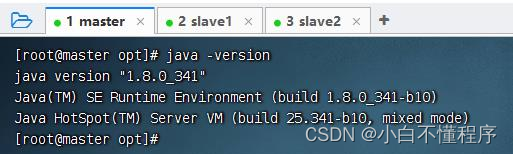
- 第一学期我们学习Java,当时我们是在Windows平台上运行Java程序的,我们知道Java是跨平台的,现在我们在Linux平台上编写和运行Java程序。(口号:编写一次,处处运行。Write Once, Run Everywhere.)
- 编写一个Java程序 - HelloWorld.java(这里需要自己写以下语句,而不是自动生成的。)
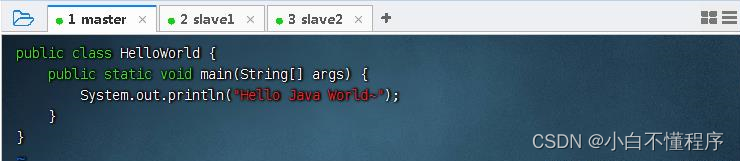
- 存盘退出后,执行命令:javac HelloWorld.java,编译成字节码文件

- 执行命令:java HelloWorld

4、将JDK分发到slave1和slave2虚拟机
- 执行命令:scp -r $JAVA_HOME root@slave1:$JAVA_HOME (-r:recursive - 递归)

- 在slave1虚拟机上查看JDK是否拷贝成功

- 执行命令:yum -y install glibc.i686

- 执行命令:scp -r $JAVA_HOME root@slave2:$JAVA_HOME (-r recursive - 递归)

- 在slave2虚拟机上查看JDK是否拷贝成功

- 执行命令:yum -y install glibc.i686

5、将环境配置文件分发到slave1和slave2虚拟机
- 执行命令:scp /etc/profile root@slave1:/etc
- 执行命令:scp /etc/profile root@slave2:/etc

- 在slave1与slave2虚拟机上执行命令:source /etc/profile,让环境配置生效


- 在slave1虚拟机上查看JDK版本(命令:java -version)

- 在slave2虚拟机上查看JDK版本(命令:java -version)

- 课堂练习:
- 将主节点上的Java程序HelloWorld.java分发到slave1节点,

- 然后编译执行(首先,cd /opt进入到opt,然后进行编译:javac HelloWorld.java 下一步:java HelloWorld)

(四)Hadoop安装
-
Hadoop是Apache基金会面向全球开源的产品之一,任何用户都可以从Apache Hadoop官网下载使用。本次学习Hadoop,我们使用目前的最新版 - hadoop-3.3.4。
1、下载Hadoop压缩包
-
下载链接:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz,推荐大家用迅雷下载,贼快!

2、上传Hadoop压缩包到虚拟机
- 将Hadoop压缩包上传到master虚拟机/opt目录


- 查看上传的Hadoop压缩包(命令:ll)

3、将Hadoop压缩包解压到指定目录
- 执行命令:tar -xzvf hadoop-3.3.4.tar.gz -C /usr/local

- 查看解压之后的hadoop目录( ll /usr/local/hadoop-3.3.4)
- 在配置Hadoop时,常用的就是
bin、etc与sbin三个目录
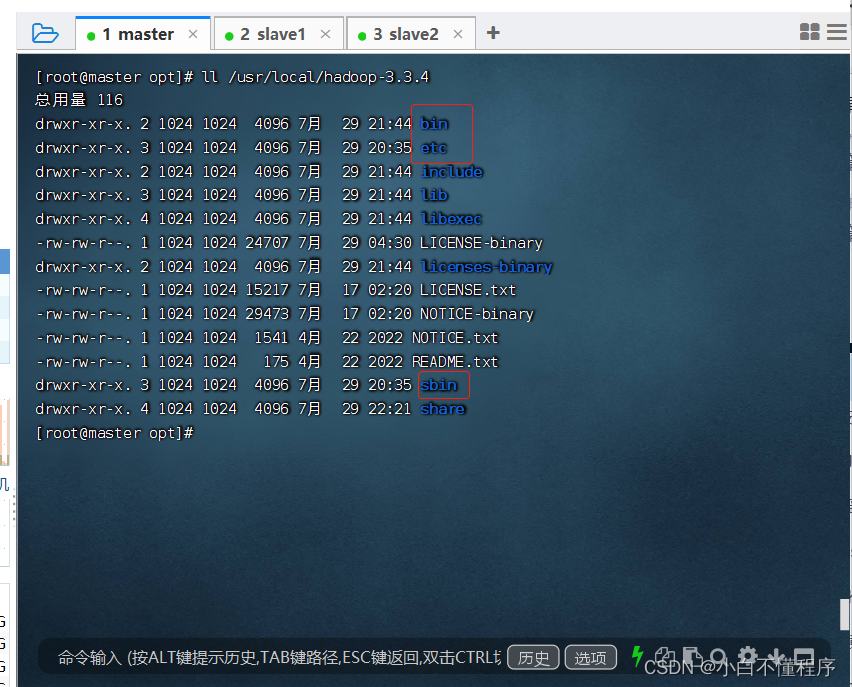
| 目录 | 作用 |
|---|---|
| bin目录 | 命令脚本 |
| etc/hadoop目录 | 存放hadoop的配置文件 |
| lib目录 | hadoop运行的依赖jar包 |
| sbin目录 | 存放启动和关闭hadoop等命令 |
| libexec目录 | 存放的也是hadoop命令,但一般不常用 |
- 查看bin目录( 命令: ll /usr/local/hadoop-3.3.4/bin)

- 查看etc/hadoop目录,主要是hadoop配置文件(命令: ll /usr/local/hadoop-3.3.4/etc/hadoop)

- 查看sbin目录(命令: ll /usr/local/hadoop-3.3.4/sbin)

4、配置Hadoop环境变量
- 执行命令:vim /etc/profile

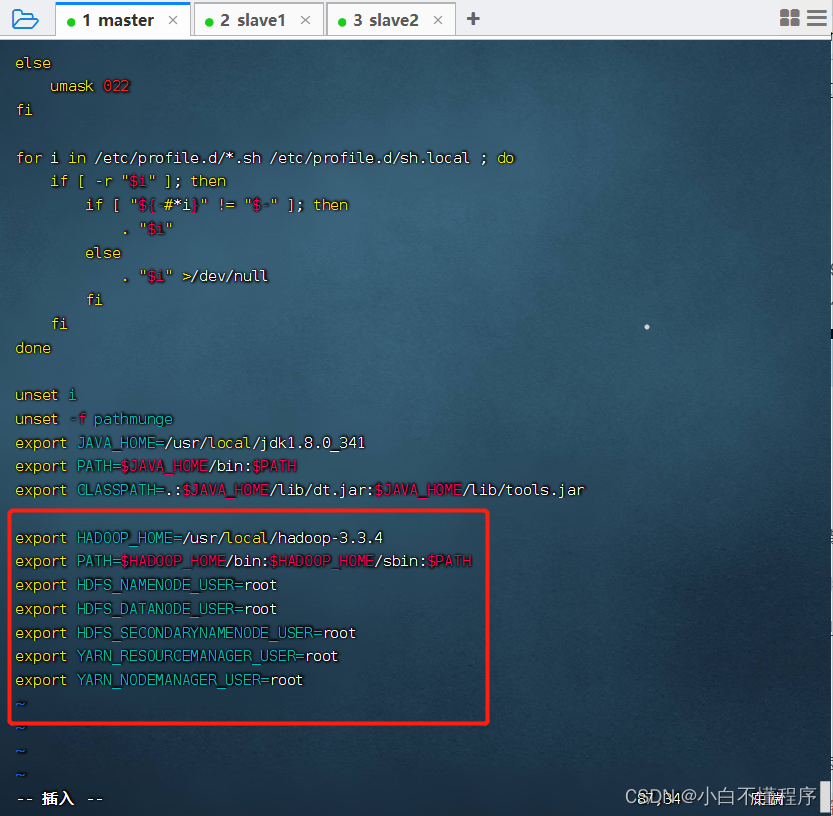
- 说明:hadoop 2.x用不着配置用户,只需要前两行即可
1.export HADOOP_HOME=/usr/local/hadoop-3.3.4
2.export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
3.export HDFS_NAMENODE_USER=root
4.export HDFS_DATANODE_USER=root
5.export HDFS_SECONDARYNAMENODE_USER=root
6.export YARN_RESOURCEMANAGER_USER=root
7.export YARN_NODEMANAGER_USER=root
- 存盘退出(esc退出编辑,:wq退出存盘),执行命令source /etc/profile,让配置生效

5、验证Hadoop环境
- 执行命令:hadoop version,检查Hadoop安装是否成功
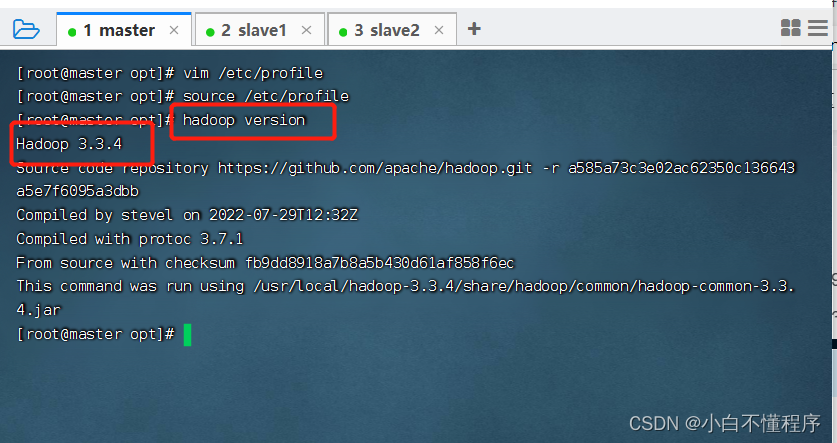
安装成功!
今天的分享结束!下一节,我们会学习如何配置Hadoop集群!














 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









