







 总结一下,解决主从复制延迟一共可以有如下7种思路:读写走主库方案延迟查询方案判断主备无延迟方案判断同步位点方案等待同步位点方案半同步复制方案+等待位点组复制MGR方案其实在实际生产中,这些方案是可以混合使用的,因为一致性越强就意味着性能越低。比如业务不在乎是否查询到过期数据就可以直接查询从库,如果需要的一致性强可以选择后几种方案。
总结一下,解决主从复制延迟一共可以有如下7种思路:读写走主库方案延迟查询方案判断主备无延迟方案判断同步位点方案等待同步位点方案半同步复制方案+等待位点组复制MGR方案其实在实际生产中,这些方案是可以混合使用的,因为一致性越强就意味着性能越低。比如业务不在乎是否查询到过期数据就可以直接查询从库,如果需要的一致性强可以选择后几种方案。
主从数据不一致问题
先介绍下问题产生的背景。
在MySQL 一主多从的架构中,主要有两种,一种是通过客户端直连,一种是通过代理 prxoy 间接连接。
客户端直连模式下一般会把数据库的连接信息放在客户端的连接层,客户端做负载均衡,由客户端来选择后端数据库进行查询。通过代理的模式下 MySQL 和客户端之间有一个中间代理层 proxy,客户端直连接 proxy, 由 proxy 根据请求类型和上下文决定请求的分发路由。
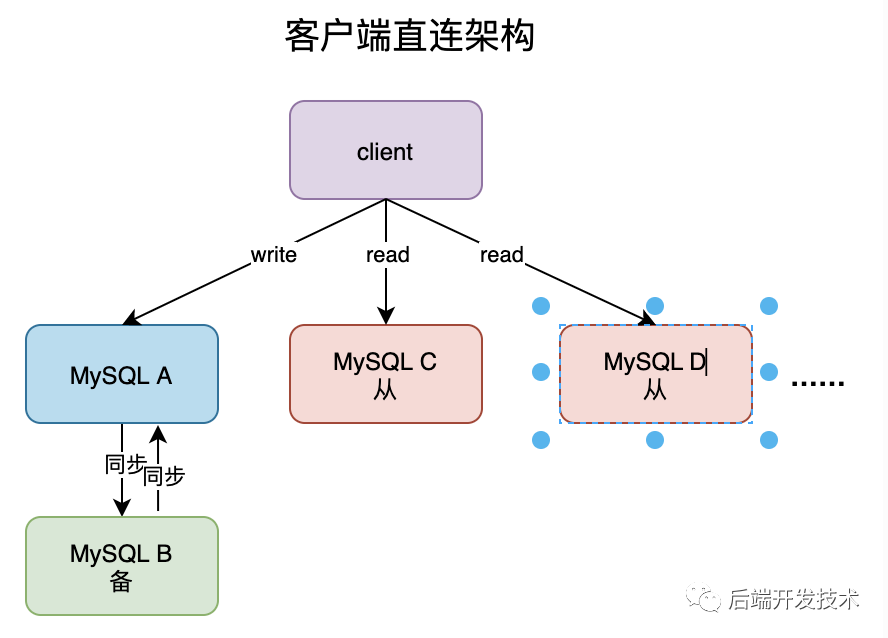
客户端直连和带 proxy 的读写分离架构,各有哪些特点。
-
客户端直连方案,整体架构简单,排查问题方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,处理起来比较麻烦,对开发人员要求高。
-
直连 proxy 的架构,对客户端比较友好。客户端不需要关注后端细节,但是 proxy 也需要有高可用架构,架构更复杂,对运维团队要求更高。
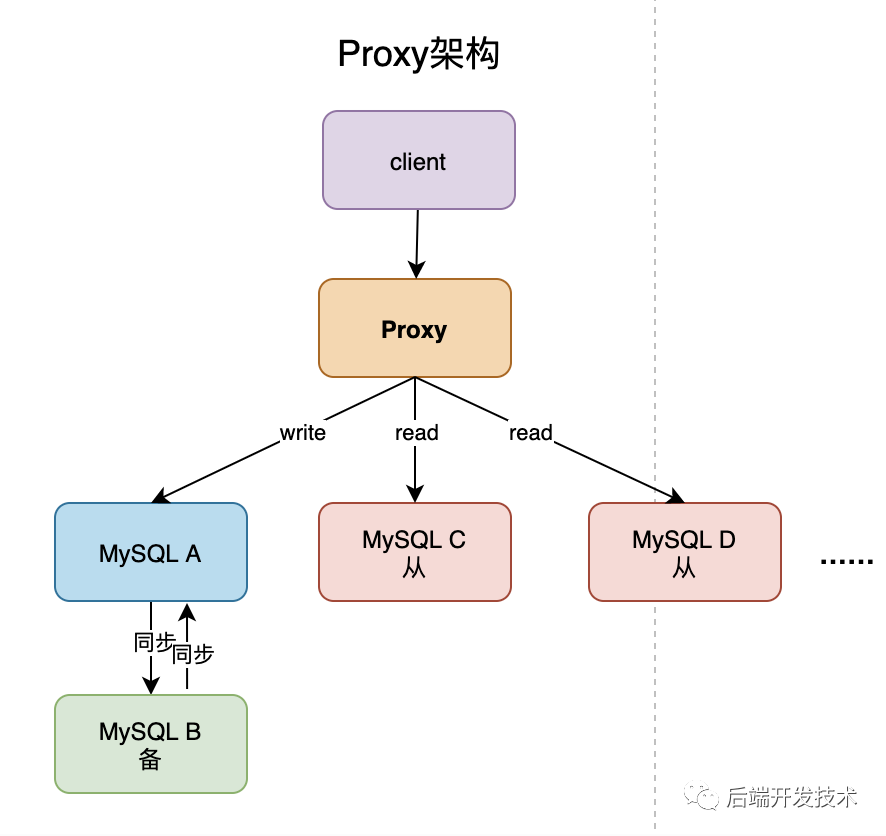
目前趋势是直连 proxy 的方向发展,具体取舍取决于自身情况。
带来的问题
无论哪种架构,都会遇到主从数据不一致的问题:由于主从同步可能存在延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就有可能读到刚刚的事务更新之前的状态。如何解决呢?
在进行读写分离的同时,解决主从同步中数据不一致的问题,主要有几种思路,一是从业务层面解决,二是从检测主从同步的差异上解决,三也是最根本的方式——从主从之间数据复制方式解决。按照这三种指导思想,我总结了一下有以下几种方案。
全部走主库方案
先说一种最为广泛使用的方案,也就是二狗的回答。
如果是在同一数据库中对数据进行更新的时候,可以对记录加写锁,这样在读取的时候就不会发生数据不一致的情况。所以我们可以根据业务场景来做区分。如果是需要写完之后必须读区到准确数据的场景,可以直接全部走主库,比如订单支付、金融业务等强一致性场景;如果业务允许读到旧数据,可以在读的时候查询从库。
这样的话你可能觉得并没有真正解决主从不一致的问题,但其实在实际生产中,大多数情况下都这么解决的。优点是简单成本低,不需要复杂架构。缺
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









