







实验要求及解析源代码
一
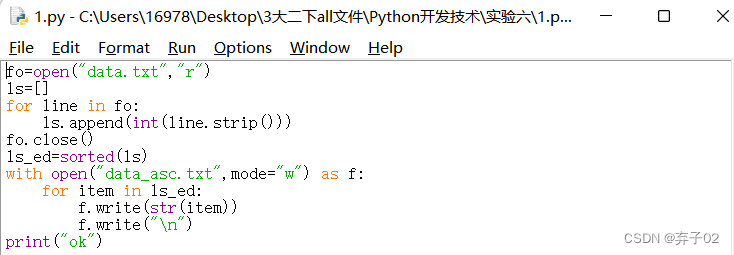
编写程序,从文件data.txt中取出一组乱序的序列,然后对其进行排序,然后在把排序后的结果写入data_asc.txt中。效果仅供参考:


fo=open("data.txt","r")
ls=[]
for line in fo:
ls.append(int(line.strip()))
fo.close()
ls_ed=sorted(ls)
with open("data_asc.txt",mode="w") as f:
for item in ls_ed:
f.write(str(item))
f.write("\n")
print("ok")
二
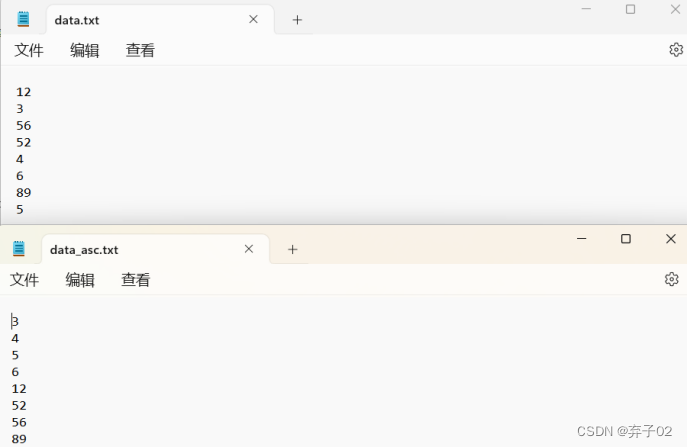
把之前实验的王者荣耀提取的英雄,写入heros.txt中,然后读取出来
import re
str1="""
<li>
<a href="/webplat/info/news_version3/15592/29030/29082/29084/m11740/202301/928155.shtml" class="tganime-fadein-trigger" target="_blank" οnclick="PTTSendClick('link','new-hero-item2','新英雄-列表-小图2');">
<img width="68" height="173" data-original="//game.gtimg.cn/images/yxzj/img201606/freehero/vertical/544.jpg" class="lazy" alt="赵怀真"/>
<span class="hero_name tganime-fadein-child">赵怀真</span>
</a>
</li>
<li>
<a href="/webplat/info/news_version3/15592/29030/29082/29084/m11740/202212/926468.shtml" class="tganime-fadein-trigger" target="_blank" οnclick="PTTSendClick('link','new-hero-item3','新英雄-列表-小图3');">
<img width="68" height="173" data-original="//game.gtimg.cn/images/yxzj/img201606/freehero/vertical/521.jpg" class="lazy" alt="海月"/>
<span class="hero_name tganime-fadein-child">海月</span>
</a>
</li>
<li>
<a href="/webplat/info/news_version3/15592/29030/29082/29084/m11740/202209/922524.shtml" class="tganime-fadein-trigger" target="_blank" οnclick="PTTSendClick('link','new-hero-item4','新英雄-列表-小图4');">
<img width="68" height="173" data-original="//game.gtimg.cn/images/yxzj/img201606/freehero/vertical/548.jpg" class="lazy" alt="戈娅"/>
<span class="hero_name tganime-fadein-child">戈娅</span>
</a>
</li>
"""
list2=re.findall("alt=.+?\"",str1)
with open("hero.txt",mode="w")as f:
for i in range(len(list2)):
list22=list2[i]
f.write(list22[5:len(list22)-1])
f.write("\n")
f.close()
fo=open("hero.txt","r")
print(fo.readlines())
三
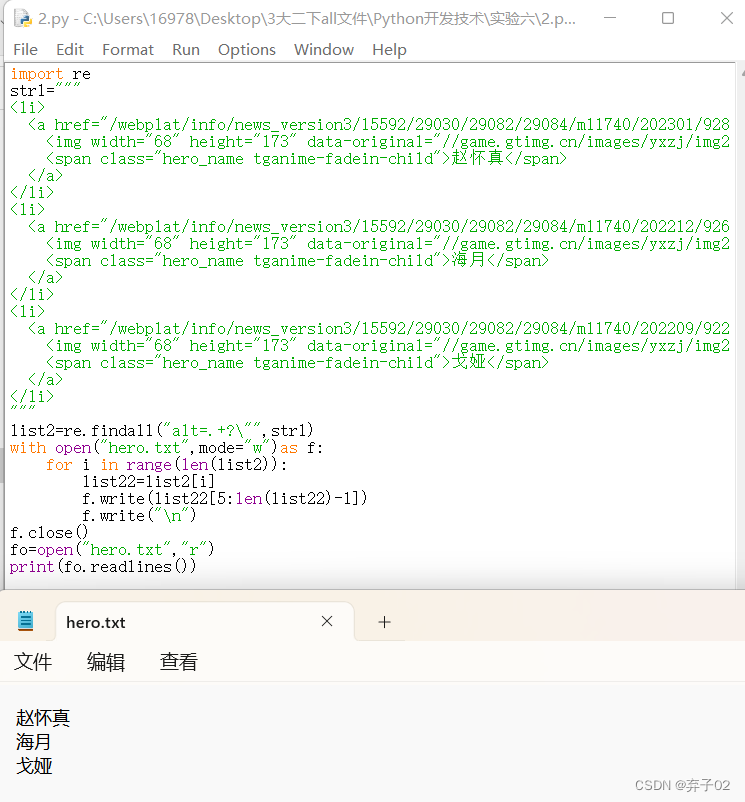
挑一部你喜欢的小说,根据老师课堂讲解完成一部小说的人物出现频率的提取(小说自选,也可以使用老师群里的天龙八部)
(1)需要使用的知识点在jieba库的课件里面,需要安装jieba库,wordcloud库
(2)注意列表、字典、集合、lambda表达式和sort方法的综合使用
(3)词云的使用,以课上讲解的提取古诗为例展示:
import jieba
from wordcloud import WordCloud
exclude=["说道","自己","一个","什么","武功","不是","甚么",
"一声","咱们","师父","心中","不知","知道","出来",
"如何","姑娘","便是","突然","他们","如此","之中",
"只见","大理","不能","丐帮","只是","不敢","见到",
"弟子","我们","众人","声音","心想","内力","倘若",
"南海","契丹","身子","这个","怎么"]
txt=open("天龙八部.txt","r",encoding="utf-8").read()
words=jieba.lcut(txt)
counts={}
#创建字典,并将人物信息写入字典
for word in words:
if len(word)==1:
continue
elif word=="萧峰":
rword=="乔峰"
else:
rword=word
counts[rword]=counts.get(rword,0)+1
for word in exclude:
del counts[word]
#转换成列表进行排序
listitem=list(counts.items())
listitem.sort(key=lambda x:x[1],reverse=True)
#将要产生的人物写入列表
list1=[]
for i in range(10):
word,count=listitem[i]
list1.append(word)
result=",".join(list1)#将人物名字变成字符串
#生成词云
w=WordCloud(background_color="white",font_path="ziti.ttf")
w.generate(result)
w.to_file("level.png")
四
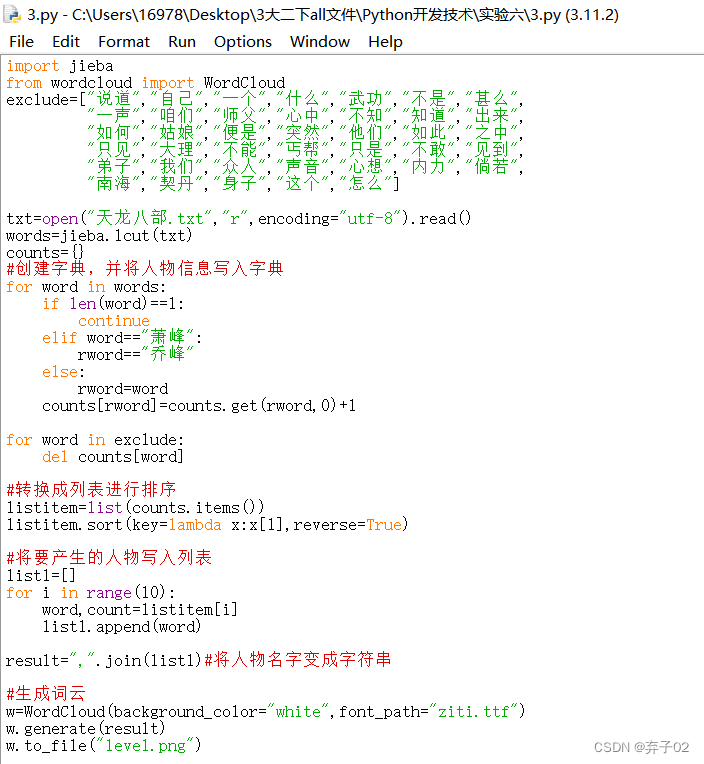
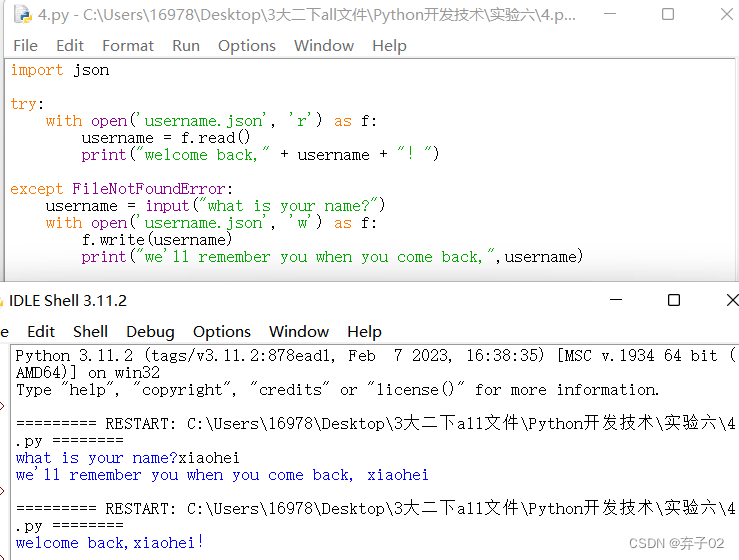
在remember.py程序中,try尝试打开username.json。如果这个文件存在,就将其中的用户名读取到内存中,执行打印一条欢迎用户回来的信息。如果用户首次运行这个程序的时候,文件username.json不存在,将引发FileNotFoundError异常,将执行exception代码块,提示用户输入其用户名,再使用json的方法存储该用户名,并打印一句问候语。
import json
try:
with open('username.json', 'r') as f:
username = f.read()
print("welcome back," + username + "!")
except FileNotFoundError:
username = input("what is your name?")
with open('username.json', 'w') as f:
f.write(username)
print("we'll remember you when you come back,",username)
实验截图
一
二
三

四















 5244
5244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









