







1、正负样本定义
rpn和rcnn的正负样本定义都是基于MaxIoUAssigner,只不过定义阈值不一样而已。
MaxIoUAssigner的操作包括4个步骤:
-
首先初始化时候假设每个anchor的mask都是-1,表示都是忽略anchor
-
将每个anchor和所有gt的iou的最大Iou小于neg_iou_thr的anchor的mask设置为0,表示是负样本(背景样本)
-
对于每个anchor,计算其和所有gt的iou,选取最大的iou对应的gt位置,如果其最大iou大于等于pos_iou_thr,则设置该anchor的mask设置为1,表示该anchor负责预测该gt bbox,是高质量anchor
-
3的设置可能会出现某些gt没有分配到对应的anchor(由于iou低于pos_iou_thr),故下一步对于每个gt还需要找出和最大iou的anchor位置,如果其iou大于min_pos_iou,将该anchor的mask设置为1,表示该anchor负责预测对应的gt。通过本步骤,可以最大程度保证每个gt都有anchor负责预测,如果还是小于min_pos_iou,那就没办法了,只能当做忽略样本了。从这一步可以看出,3和4有部分anchor重复分配了,即当某个gt和anchor的最大iou大于等于pos_iou_thr,那肯定大于min_pos_iou,此时3和4步骤分配的同一个anchor。
2、平衡回归loss
原始的faster rcnn的rcnn head,使用的回归loss是smooth l1,作者认为这个依然存在不平衡。作者分析是:loss解决Classification和Localization的问题,属于多任务loss,那么就存在一个平衡权重,一般来说回归权重会大一些,但一味的提高regression的loss其实会让outlier的影响变大(类似于OHEM中的noise label),outlier外点样本这里作者认为是样本损失大于等于1.0,这些样本会产生巨大的梯度不利于训练过程,小于的叫做inliers。平衡回归loss的目的是既不希望放大外点对梯度的影响,又要突出内点中难负样本的梯度,从而实现对外点容忍,对内点区分难负样本的作用。为此作者在smooth l1的基础上进行重新设计,得到Balanced L1 Loss。核心操作就是想要得到一个当样本在 附近产生稍微大点的梯度的函数。首先smooth l1的定义如下:
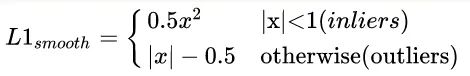
其梯度如下:
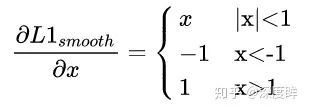
为了突出难样本梯度,需要重新设计梯度函数,作者想到了如下函数:

梯度公式 可以实现上述任务。然后反向计算就可以得到Loss函数了。为了保证连续,还需要增加(9)的限制。
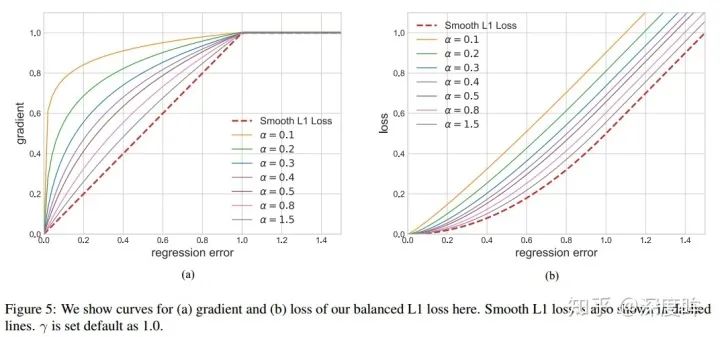
左边是梯度曲线,右边是loss曲线,可以看出非常巧妙。
3、loss设计
主要就是anchor的loc_preds和shape_preds的loss设计。
(1) loc_preds
anchor的定位模块非常简单,就是个二分类问题,希望学习出前景区域。这个分支的设定和大部分anchor-free的做法是一样的(例如fcos)。
-
首先对每个gt,利用FPN中提到的roi重映射规则,将gt映射到不同的特征图层上
-
定义中心区域和忽略区域比例,将gt落在中心区域的位置认为是正样本,忽略区域是忽略样本(模糊样本),其余区域是背景负样本,这种设定规则很常用,没啥细说的,如图所示:

-
采用focal loss进行训练
(2) loc_shape
loc_shape分支的目标是给定 anchor 中心点,预测最佳的长和宽,这是一个回归问题。先不用管作者咋做的,我们可以先思考下可以如何做,首先预测宽高,那肯定是回归问题,采用l1或者smooth l1就行了,关键是label是啥?还有哪些位置计算Loss?我们知道retinanet计算bbox 分支的target算法就是利用MaxIoUAssigner来确定特征图的哪些位置anchor是正样本,然后将这些anchor进行bbox回归。现在要预测anchor的宽高,当然也要确定这个问题。
第一个问题:如何确定特征图的哪些位置是正样本区域?,注意作者采用的anchor个数其实是1(作者觉得既然是动态anchor,那么个数其实影响不会很大,设置为1是可以的错),也就是说问题被简化了,只要确定每个特征图的每个位置是否是正样本即可。要解决这个问题其实非常容易,做法非常多,完全可以按照anchor-free的做法即可,例如FOCS,其实就是loc_preds分支如何确定正负样本的做法即可,确定中心区域和忽略区域。将中心区域的特征位置作为正样本,然后直接优化预测输出的anchor shape和对应gt的iou即可。但是论文没有这么做,我觉得直接按照fcos的做法来确定正样本区域,然后回归shape,是完全可行。本文做法是采用了ApproxMaxIoUAssigner来确定的,ApproxMaxIoUAssigner和MaxIoUAssigner非常相似,仅仅多了一个Approx,其核心思想是:利用原始retinanet的每个位置9个anchor设定,计算9个anchor和gt的iou,然后在9个anchor中采用max操作,选出每个位置9个iou中最高的iou值,然后利用该iou值计算后续的MaxIoUAssigner,此时就可以得到每个特征图位置上哪些位置是正样本了。简单来说,ApproxMaxIoUAssigner和MaxIoUAssigner的区别就仅仅是ApproxMaxIoUAssigner多了一个将9个anchor对应的iou中取最大iou的操作而已。
对于第二个问题:正样本位置对应的shape target是啥,其实得到了每个位置匹配的gt,那么对应的target肯定就是Gt值了。该分支的loss是bounded iou loss,公式如下:
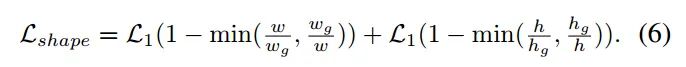
上面写的非常简陋,很多细节没有写。
结果
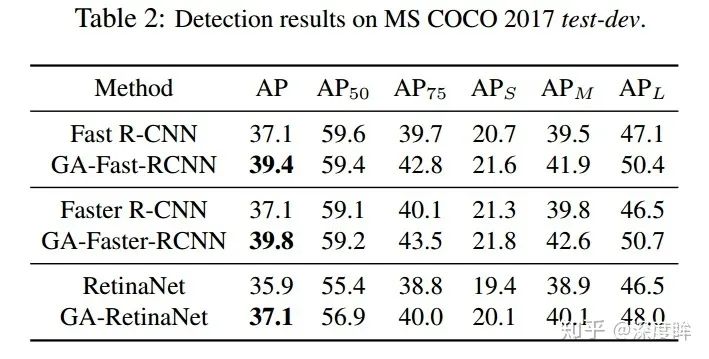

可以看出非常符合预期。















 7176
7176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









