






unittest自动化测试框架
unittest 是python 的单元测试框架,它主要有以下作用:
- 提供用例组织与执行
- 提供丰富的比较方法
- 提供丰富的日志
unittest四个概念:est fixture,test case,test suite,test runner。
test fixture(测试固件)
对一个测试用例环境的搭建和销毁,就是一个fixture,通过覆盖setUp()和tearDown()方法来实现。
- setUp():测试环境和数据的准备工作
- tearDown():做测试用例执行完成之后的清理工作
test case(测试用例)
测试用例就是一个完整的测试流程,包括测试前准备环境的搭建(setUp)、实现测试过程的代码,以及测试后环境的还原(tearDown)。一个用例就是一个方法,名字以test_开头。
test suite(测试套件)
一个功能的验证往往需要多个测试用例,可以把多个测试用例集合在一起执行,这个就产生了测试套件TestSuite的概念。必须以继承(面向对象)的方式来使用。
est runner(测试执行)
测试的执行也是非常重要的一个概念,在unittest框架中,通过TextTestRunner类提供的run()方法来执行test suite/test case。
在unittest 框架中提供了makeSuite() 的方法,makeSuite可以实现把测试用例类内所有的测试case组成的测试套件TestSuite ,unittest 调用makeSuite的时候,只需要把测试类名称传入即可。

TestLoader 用于创建类和模块的测试套件,一般的情况下,用TestLoader().loadTestsFromTestCase(TestClass) 来加载测试类。
discover 是通过递归的方式到其子目录中从指定的目录开始, 找到所有测试模块并返回一个包含它们对象的TestSuite ,然后进行加载与模式匹配唯一的测试文件,也就是把一个文件夹下所有测试脚本的测试用例都执行一遍,discover 参数分别为
unittest.defaultTestLoder.discover("../src",pattern="test*.py",top_level_dir=None)
# 文件夹 测试用例所在文件
unittest 框架默认加载测试用例的顺序是根据ASCII 码的顺序,数字与字母的顺序为:0~9,A~Z,a~z 。addTest()是按照添加的顺序来执行。
对于不想运行的测试用例打标签:@unittest.skip("skiping")
unittest断言
断言:判断实际结果和预期结果是否相符合

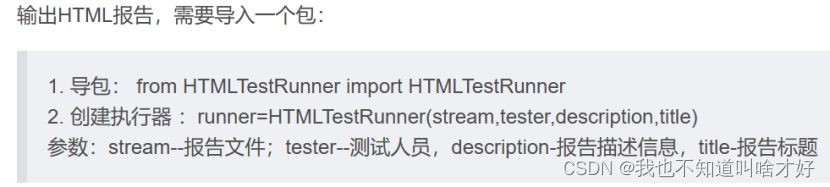
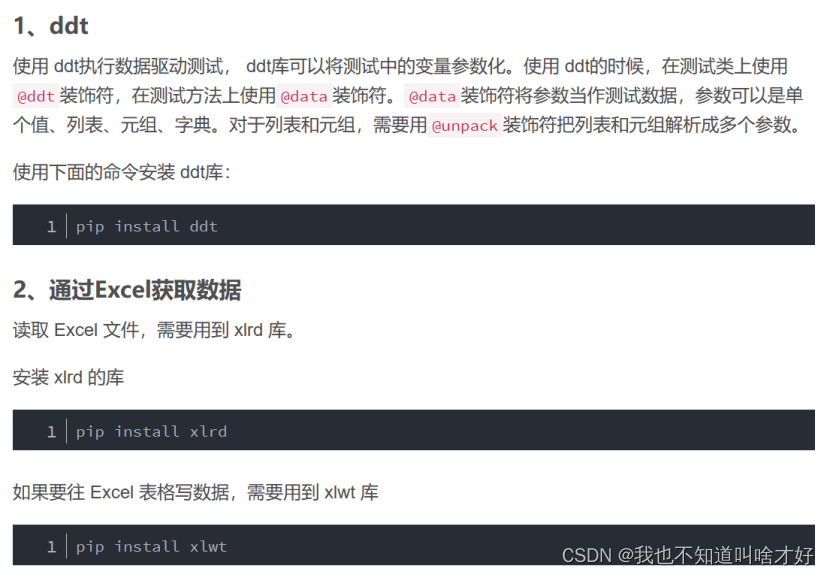
数据驱动
python 的unittest 没有自带数据驱动功能。所以如果使用unittest,同时又想使用数据驱动,那么就可以使用ddt来完成。ddt的安装

读取CSV文件
Import csv //导入CSV库
1)创建reader
csv.reader(文件对象) - 创建reader获取文件内容,文件内容每一行一个列表的形式返回
csv.DictReader(文件对象) - 创建reader获取文件内容,文件内容每一行一个字典,并且将第一行的数据作为键的形式返回
2)创建一个writer
csv.writer(文件对象) - 写入数据的时候每一行数据对应一个列表
writer1 = csv.writer(open('files/students1.csv', 'w', encoding='utf-8', newline=''))
3)写入数据

csv.DictWriter(文件对象, 键列表)
writer2 = csv.DictWriter(open('files/students2.csv', 'w', encoding='utf-8', newline=' '), ['姓名', '年龄', '性别', '电话'])
将字典的键作为第一行内容写入到文件中
















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









