






1.介绍
给出一个金融数据分析常见的实例来讲解pandas中resample函数和pivot_table的应用:
拿红利指数的成分进出记录举例,假设现在有一个股票指数的Excel包含了该指数从编撰以来成分股的进出记录,读成datafram如下:
import pandas as pd #导入需要使用的模块
import numpy as np
from datetime import datetime
df=pd.read_excel('上证红利指数-成分进出记录.xlsx') #读取excel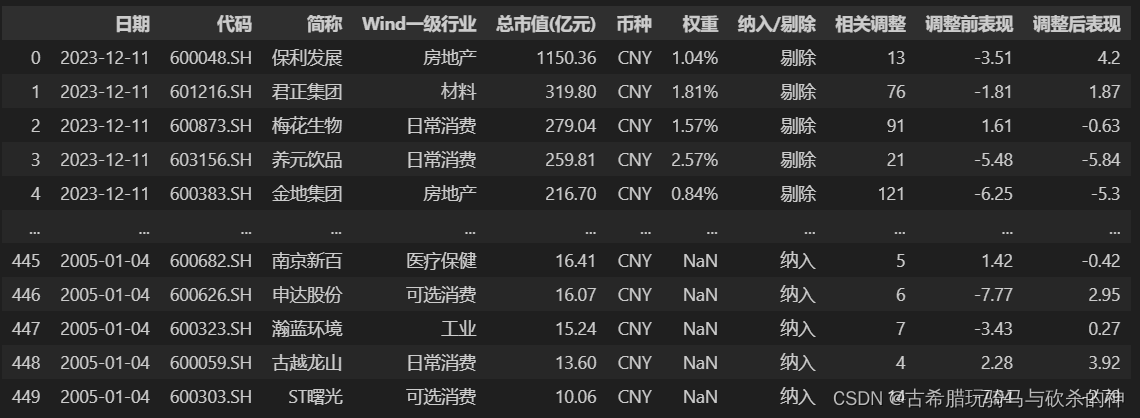
现在想要得到一个datafram,行(rows)为可能包含的成分股代码,列(columns)为自编撰该指数以来的月频日期,值(values)为0和1,分别代表对应日期下对应股票是否为该指数成分股,0代表不是,1代表是,结果like this~
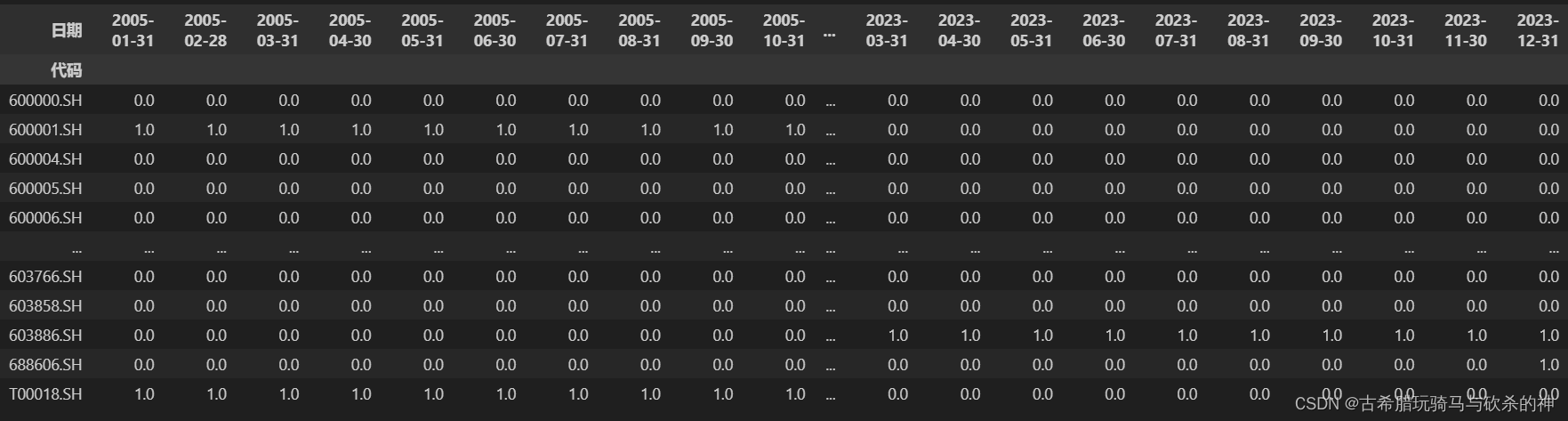
该怎么操作?这个问题用两个主要函数pivot_table和resample就可以解决,下面给出步骤
2.pivot_table()
先简单说明pivot_table()函数的用法和结果,pivot_table()函数和excel里的数据透视比较像,直白理解就是转换数据视角,比如就拿本文中的原始数据df举例
这个数据表中可以看到很多信息,假如现在我们想找到2005-01-04这个日期下,600626.SH这支股票的市值为多少,就可以直接找到2005-01-04日期下600626.SH这一行,然后去找总市值(亿元)那一列就好了,但是这样直观看起来不是很方便,我们能不能通过一定的数据操作得到一个表格,行直接就是日期,列直接就是股票代码,值就是市值,这样更加一目了然不是更好吗?
所以pivot_table()的作用就是这样的,假如执行以下代码:
df_pivot_table=df.pivot_table(index='日期',columns='代码',values='总市值(亿元)')
#pivot_table常见的语法有三个参数,index指定行索引,columns指定什么做列,values指定单元格的值是什么数据,它的返回值为一个新的datafram就会得到以下结果:
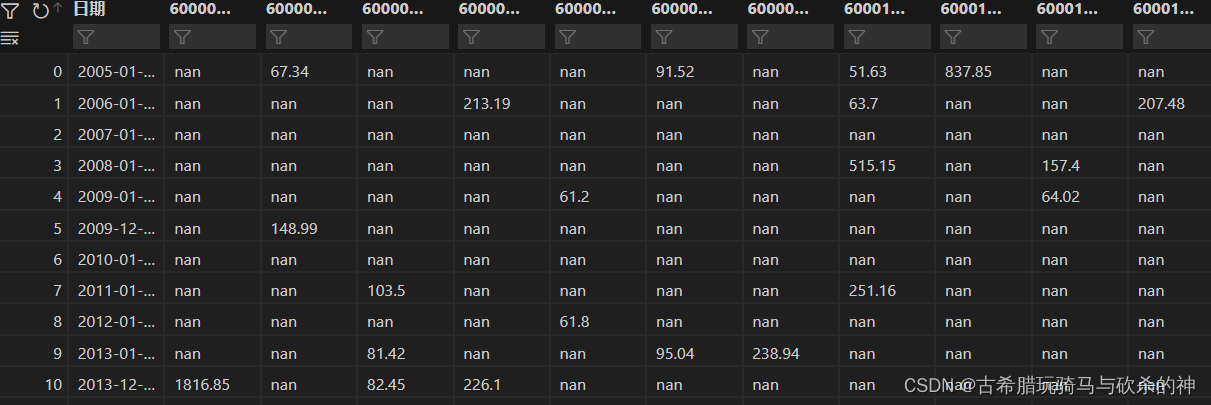
这也就是pivot_table()的作用,看到这里的读者可能会对这么多的nan空值产生疑问,但nan是正常的,举个例子,假如2023-12-21这个时间点600048.SH这支股票被新纳入到了股指当中,但是实际上2005-01-04这个日期编撰指数的时候还没有600048.SH这个指数,那2005-01-04对应600048.SH的值自然就是空值,对应于上图的结果就会看到nan
3.resample()
然后简单说明resample()的用法,还是拿本文的df举例:
可以发现实际上这个数据表中的日期是跳跃的,也就是2005-01-04下一个日期可能并不是2005-01-05,可能直接就是好几个月后的某一天,毕竟红利指数也并不是天天都要重新编一遍。但是我们有时在做数据分析的时候需要有一个月频的数据表,也就是我们需要手动填充2005-01-05的值,那2005-01-05的值哪里来呢?这个时候我们可以选择向前填充ffill(),比如这里的‘‘权重’’这一列,我们可以认为第二天指数未更新编撰,也就是各股权重和前一天相等,这个时候就可以用resample()来重采样
resample()重采样一般可以分为升采样和降采样,高频数据->低频数据为降采样,低频数据->高频数据为升采样,举例说明,我们假设现在有一个datafram是这样的:
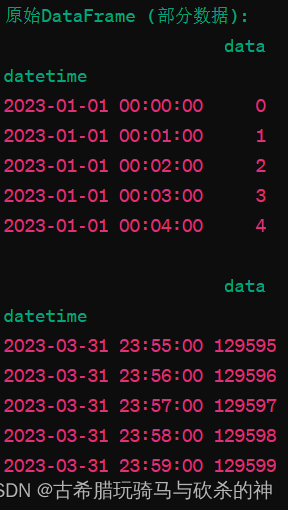
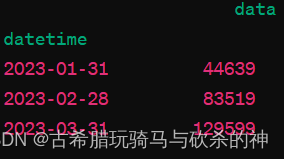
即从2023年初到三月底的高频到分钟的数据,现在我们想得到一个降采样,只需要得到每月最后一天23:59的数据作为该月的代表的月频数据,就可以使用resample()函数:
df.resample('M').last()
#这里的'M'表示按月频采样,如果是日频可以改为'D',last()表示/填充聚合方法,即最后一个数据作为填充,还可以依情况设定为sum(),ffill(),bfill()等结果如以下格式:
4.具体应用
接下来解决开头提出的那个问题
首先把原文中的纳入剔除的字符换成0和1,方便后续操作
df.replace('纳入',1,inplace=True) #df.replace(old,new,inplace=True or False) 其中inplace表示是否在原df的基础上修改
df.replace('剔除',0,inplace=True)然后进行数据透视
df=df.pivot_table(index='代码',columns='日期',values='纳入/剔除',fill_value=np.nan)
#补充说明,pivot_table要求value为数值,所以要提前换为数值得到的df如下:
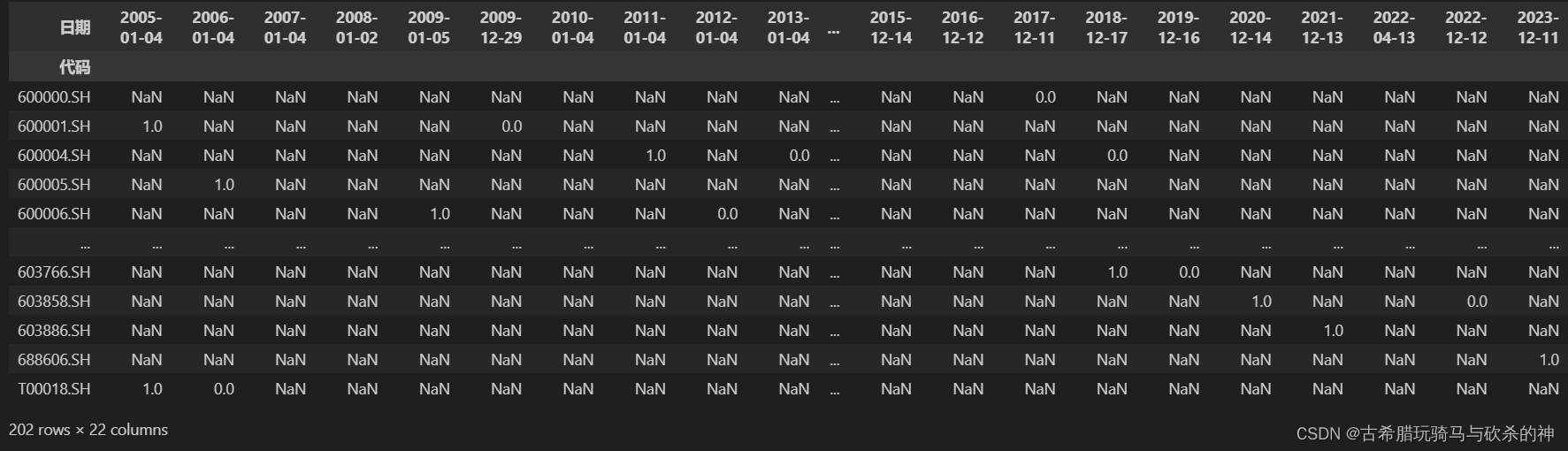
这里我们需要处理nan的值,在第二部分说明过这些nan出现的原因,容易发现,我们期望得到的结果实际上是如果这个股票在某一个日期下值为1,那说明它在这个时间点刚被纳入,那么直到它被剔除的下一个时间点值为0之前,间隔的这些空值都应该填充为1表示它一直是成分股,而那些后来一直没有剔除的初始成分股在第一个时间点已经纳入置为1,我们这样操作也刚好可以让这些初始纳入并且后来一直没有剔除的成分股变成1,避免了这些初始成分股后续必然出现的nan空值。同时需要说明,这样的操作可以用ffill()完成,但是ffill()无法对一开始为nan的值进行向前填充,所以我们需要在ffill()之后把这些值处理为0
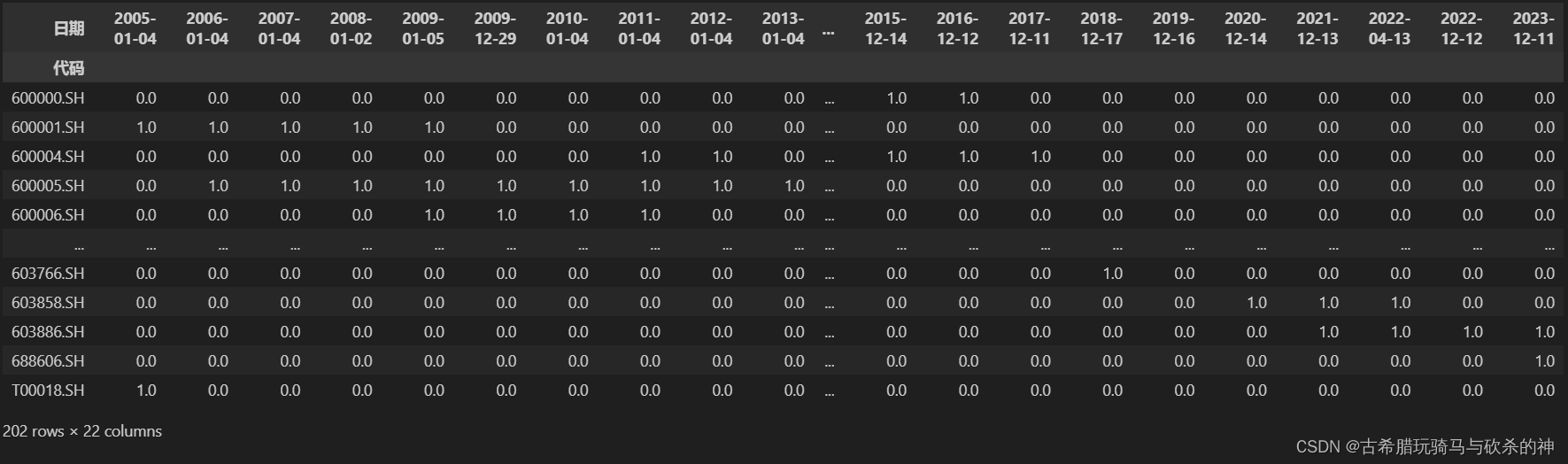
df_new=df.ffill(axis=1) #按行进行填充
df_new.replace(np.nan,0,inplace=True) #把ffill不能向前填充的开头的值用0替换这样就会得到一个df_new:
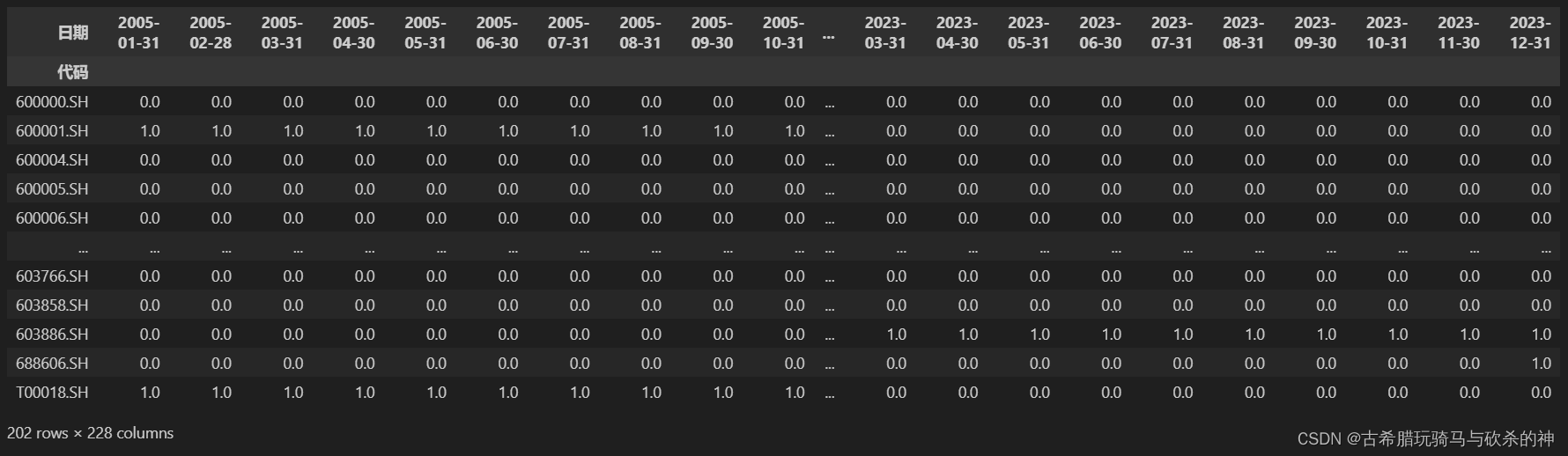
接下来就只需要对这些断断续续的日期进行数据升采样就可以了:
df_new.columns=pd.to_datetime(df_new.columns) #resample索引必须为日期类型,所以要进行转换
df_final=df_new.T.resample('M').ffill() #resample一般是对索引进行操作,所以这里可以转置操作使得日期作为行我们得到的df_final就是我们最终要的结果:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









