






评分系统是一种常见的推荐系统。可以使用PYTHON等语言基于协同过滤算法来构建一个电影评分预测模型。本次推荐系统基于用户的协同过滤算法进行构建。
一、数据准备
获取数据ml-100k:明尼苏达州大学的社会化计算研究中心官网上面下载这些免费数据集,网站链接为https://grouplens.org/datasets/movielens/
本次数据集文件有links.csv、movies.csv、ratings.csv和tags.csv。
ratings.csv :用户对电影的评分信息(userId 、movieId、rating、timestamp)。
movies.csv :电影的基本信息(movieId、title、genres)。
links.csv :电影在外部数据库中的链接信息(movieId、imdbId、tmdbId)。
tags.csv :用户对电影的标签信息(userId、movieId、tag 、timestamp)。
二、数据处理
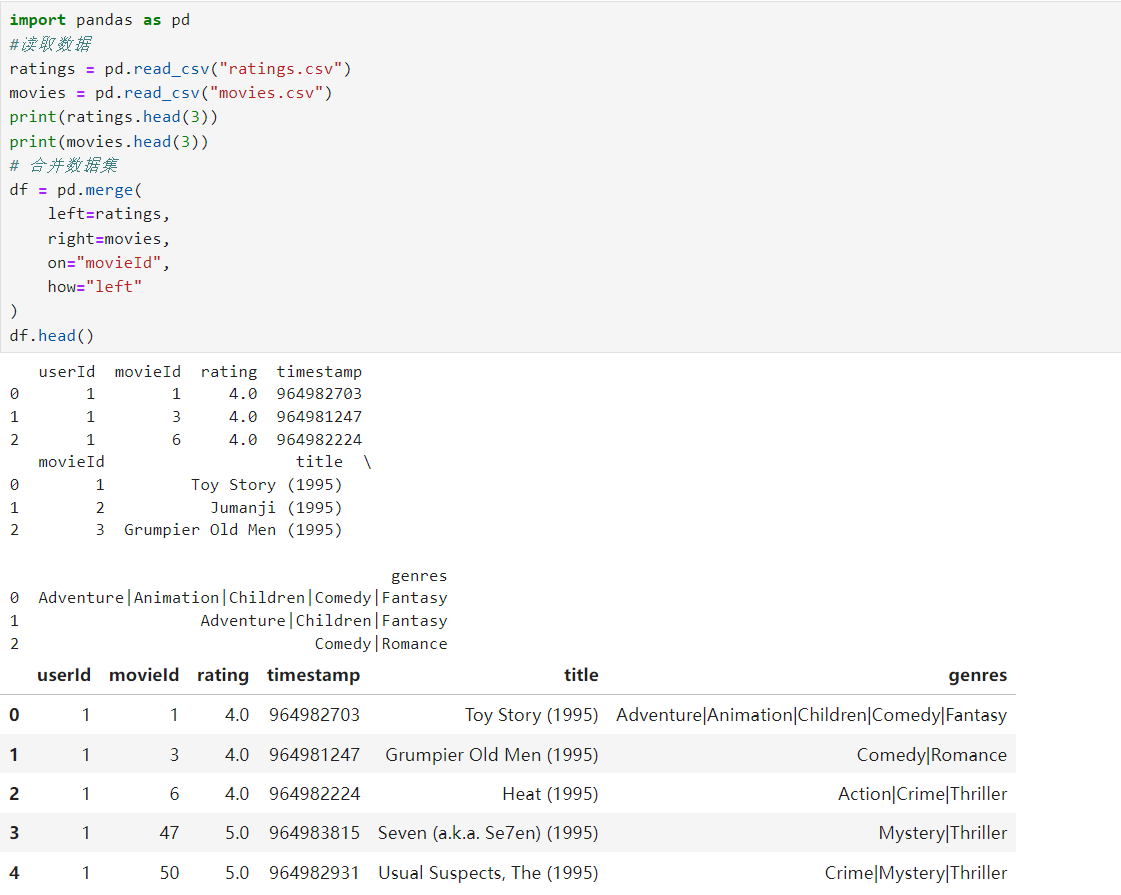
1.数据获取
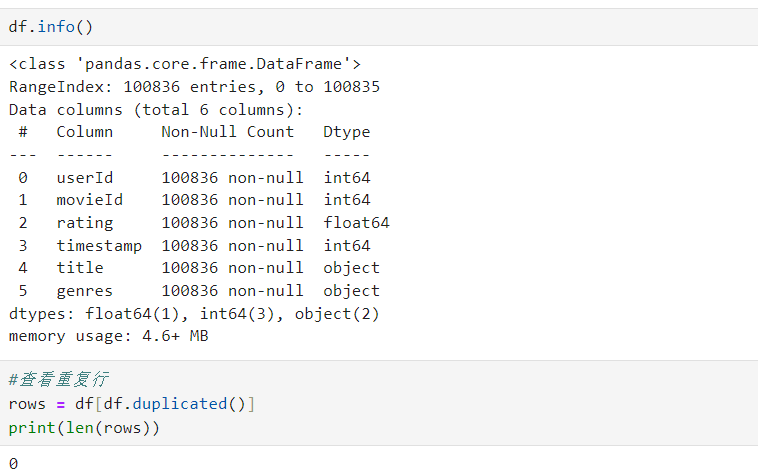
2.数据预处理
可以看到数据并不存在缺失值和重复值
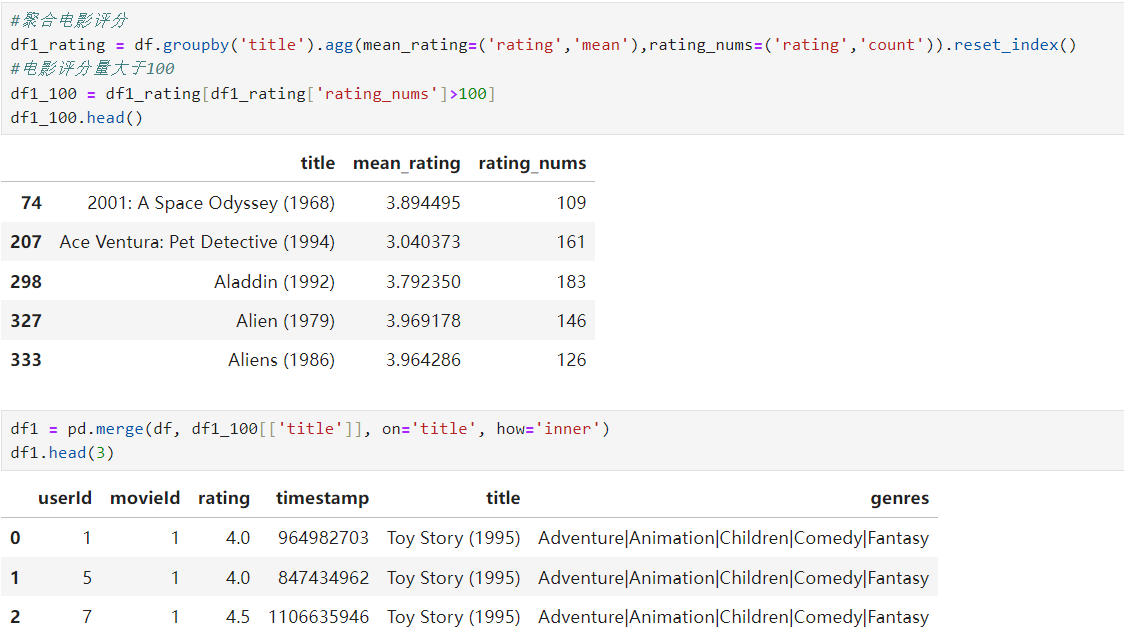
因为数据比较稀疏,所以对电影进行一下筛选,筛选出评论数量超过100的数据
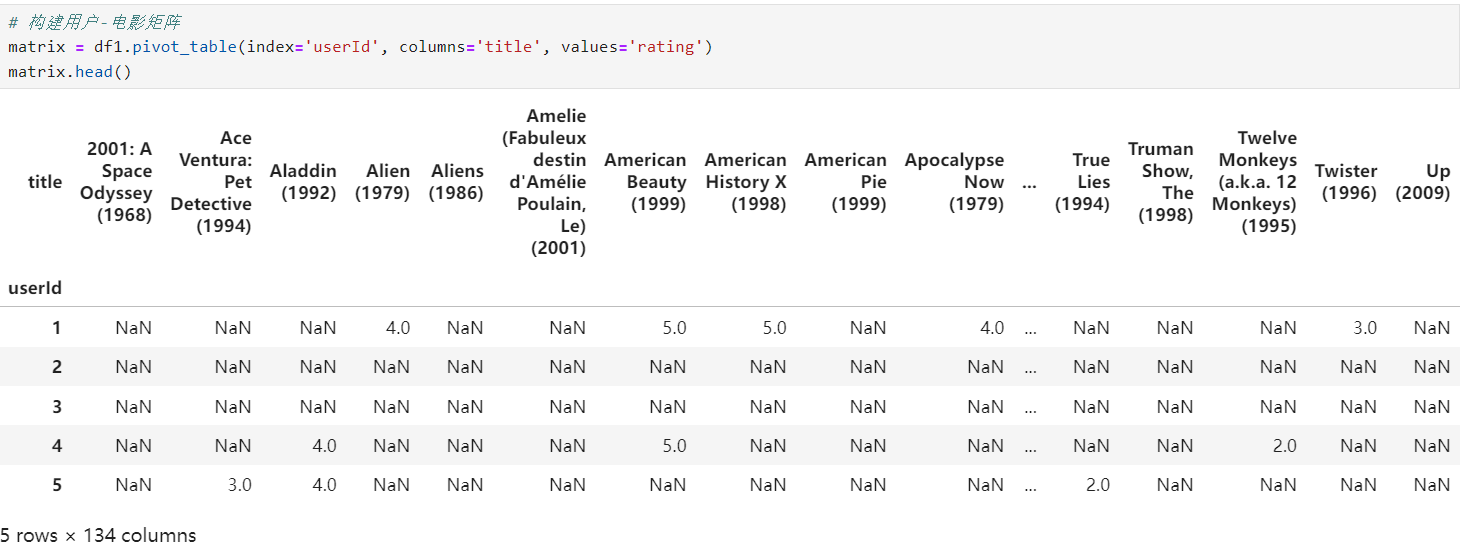
3.构建用户-电影评分矩阵
4.计算相似度(这里使用皮尔逊相似度)
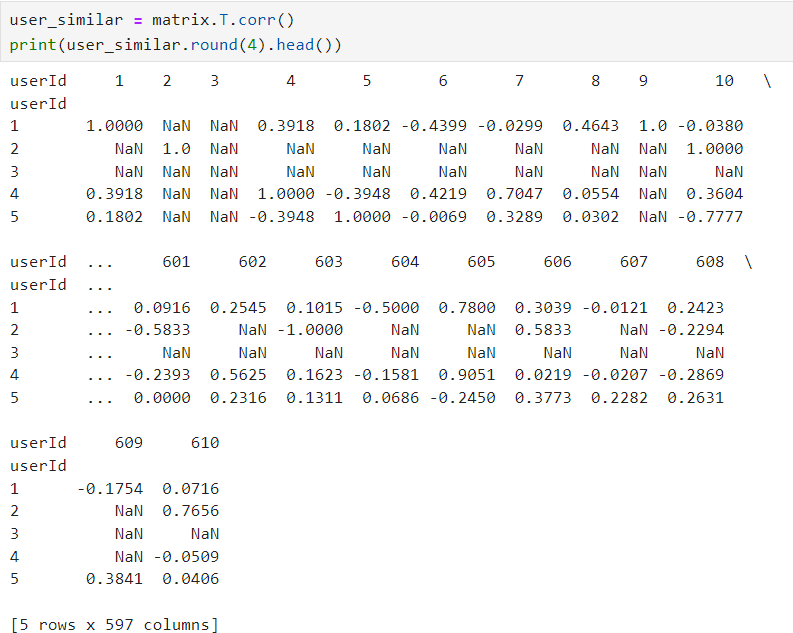
可以看到部分用户被筛选掉了。可能这类用户比较喜欢小众的电影或者比较新的电影。
5.构建推荐系统
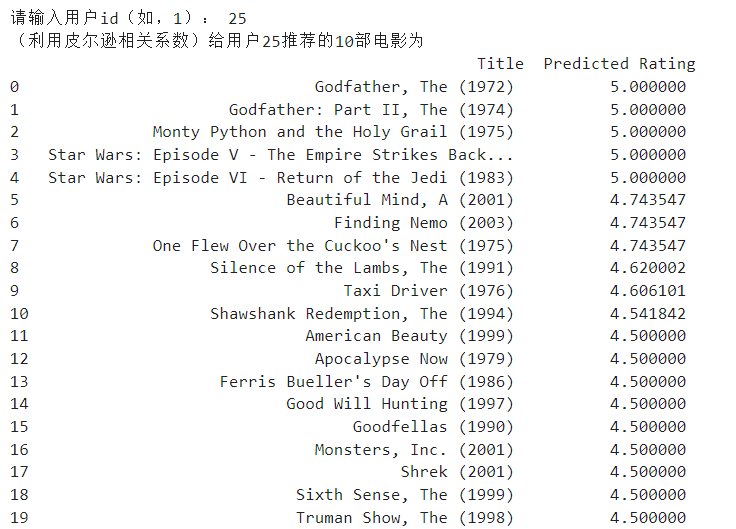
预测评分是在1-5的范围内,说明计算评分的方法没有问题。如果没有对电影进行筛选的步骤,会发现5分的电影评论会很多,无法明显看到推荐的电影基于预测评分排序(从高到低)情况。
三、总结
以上方法,仅利用用户协同过滤算法基于评论的电影推荐系统,由于数据是稀疏的,用户协同过滤算法其实存在一定的局限性的,所以这个方法的效果其实并不太好,有一定的改进空间。后续可以通过引入矩阵分解、基于内容的推荐、元数据等改进方法,可以显著提升推荐系统的性能。
以上是我的简单分享,希望对你有所帮助。同时,我也在学习过程,有问题可以指出,大家共同学习。

















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









