







文章目录
- 1.4 week 4
- 1.4.1 深层神经网络(Deep L-layer neural network)
- 1.4.2 前向和反向传播
- 1.4.3 深层网络中的前向传播(Forward Propagation in a Deep Network)
- 1.4.4 核对矩阵的维数(Getting your matrix demensions right)
- 1.4.5 为什么要使用深层表示(Why deep representations)
- 1.4.6 搭建深层神经网络模块(Building blocks of deep neural networks)
- 1.4.7 参数 vs 超参数(Parameters VS Hyperparameters)
- 1.4.8 这和大脑有什么关系(What does this have to do with the brain)
1.4 week 4
1.4.1 深层神经网络(Deep L-layer neural network)
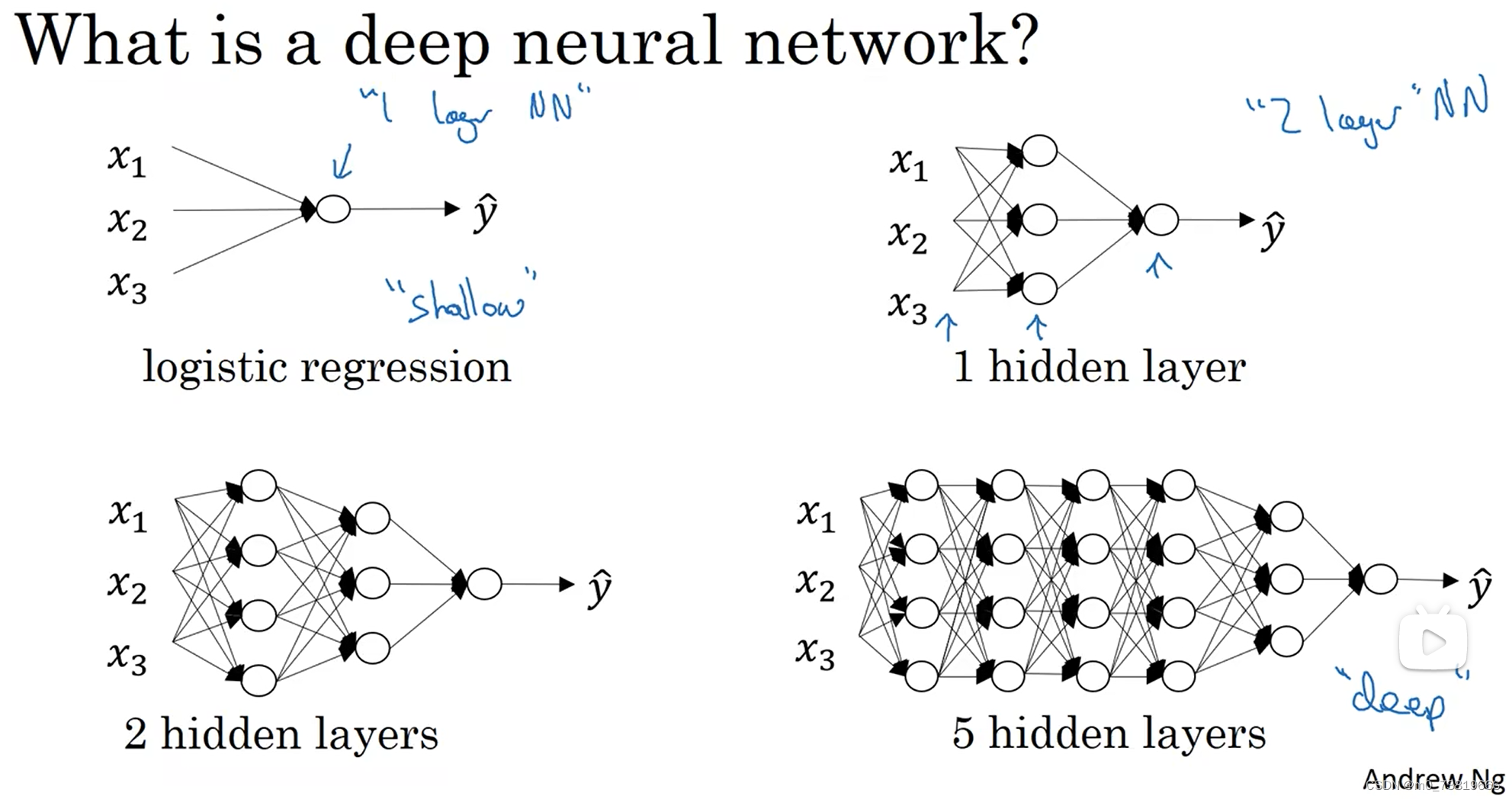
Logistic Regression – “shallow”
5 Hidden layers NN – “deep”
当人们需要处理一些复杂的工作时,深层神经网络就应运而生了。
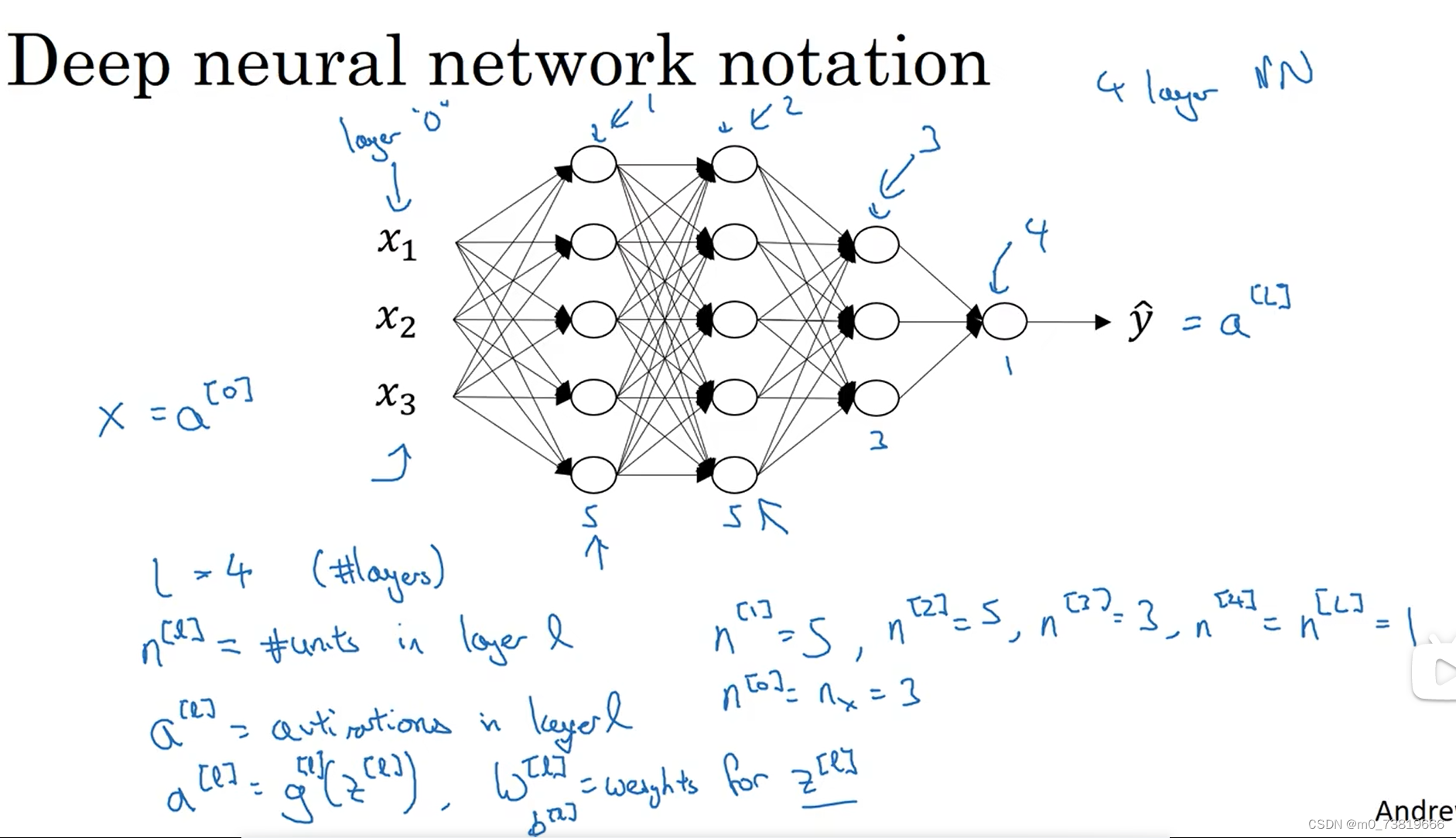
符号规定:
a
[
l
]
a^{[l]}
a[l] = activations in layer
l
l
l
则有:
x
x
x =
a
[
0
]
a^{[0]}
a[0]
y
^
\hat{y}
y^ =
a
[
l
]
a^{[l]}
a[l]
1.4.2 前向和反向传播
前向传播(Forward Propagation)
“正向传播求损失,反向传播求回传误差”

可以缓存出
w
[
l
]
w^{[l]}
w[l],
b
[
l
]
b^{[l]}
b[l]方便操作
反向传播(Backward Propagation)

1.4.3 深层网络中的前向传播(Forward Propagation in a Deep Network)
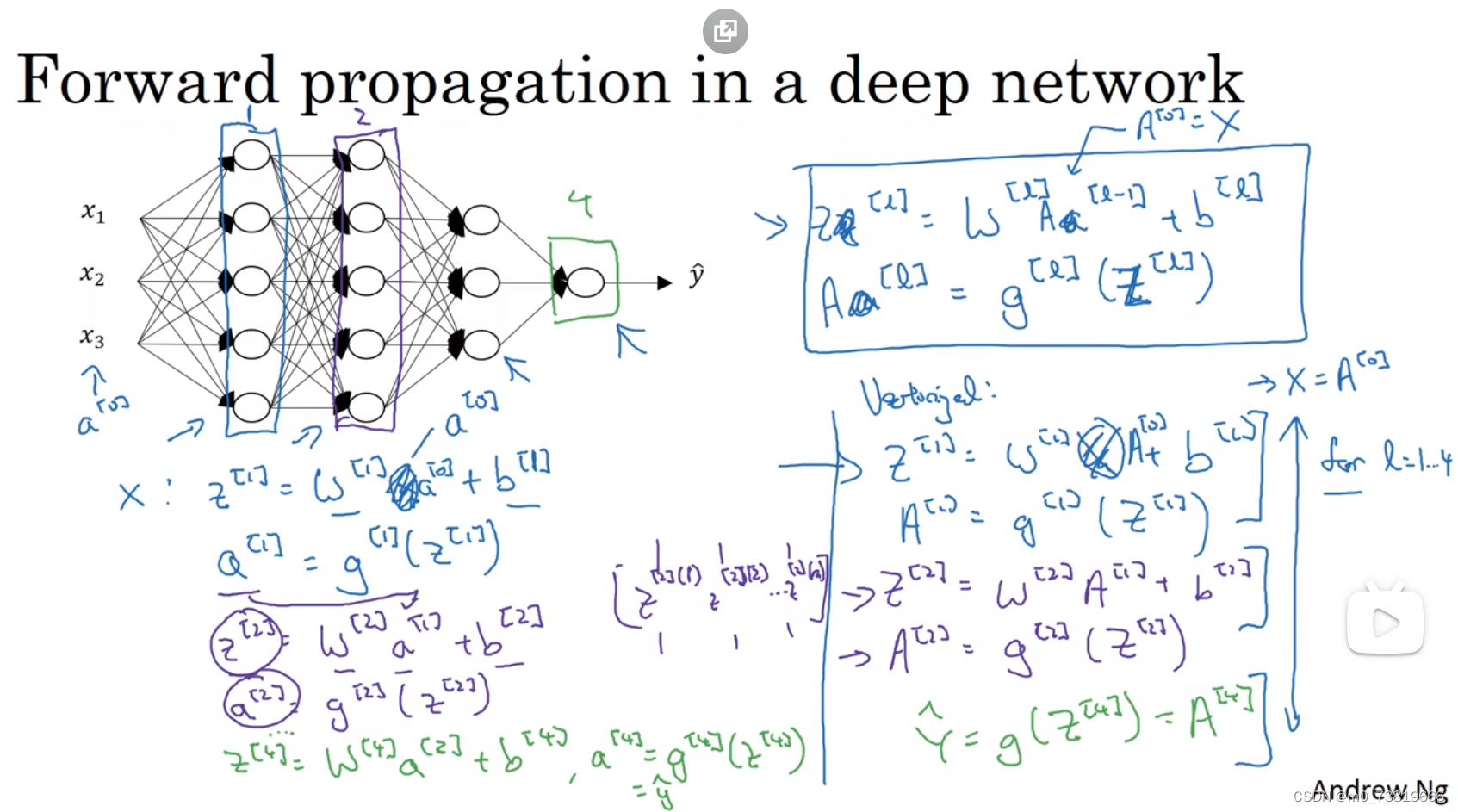
·向量化(Vectorized)的过程十分简单,仅需将每层的各数据水平放置进矩阵中即可。
·在前向传播中,不可避免的要使用显性的for循环,然而目前没有更好的替代方法,for循环能够很好的将每个层 (图中为4层)的输出表达出来。
·此时的程序容易产生bug,一个比较良好的debug办法是注意计算矩阵的维数,或许可以多用之前提到的assert方法。
1.4.4 核对矩阵的维数(Getting your matrix demensions right)
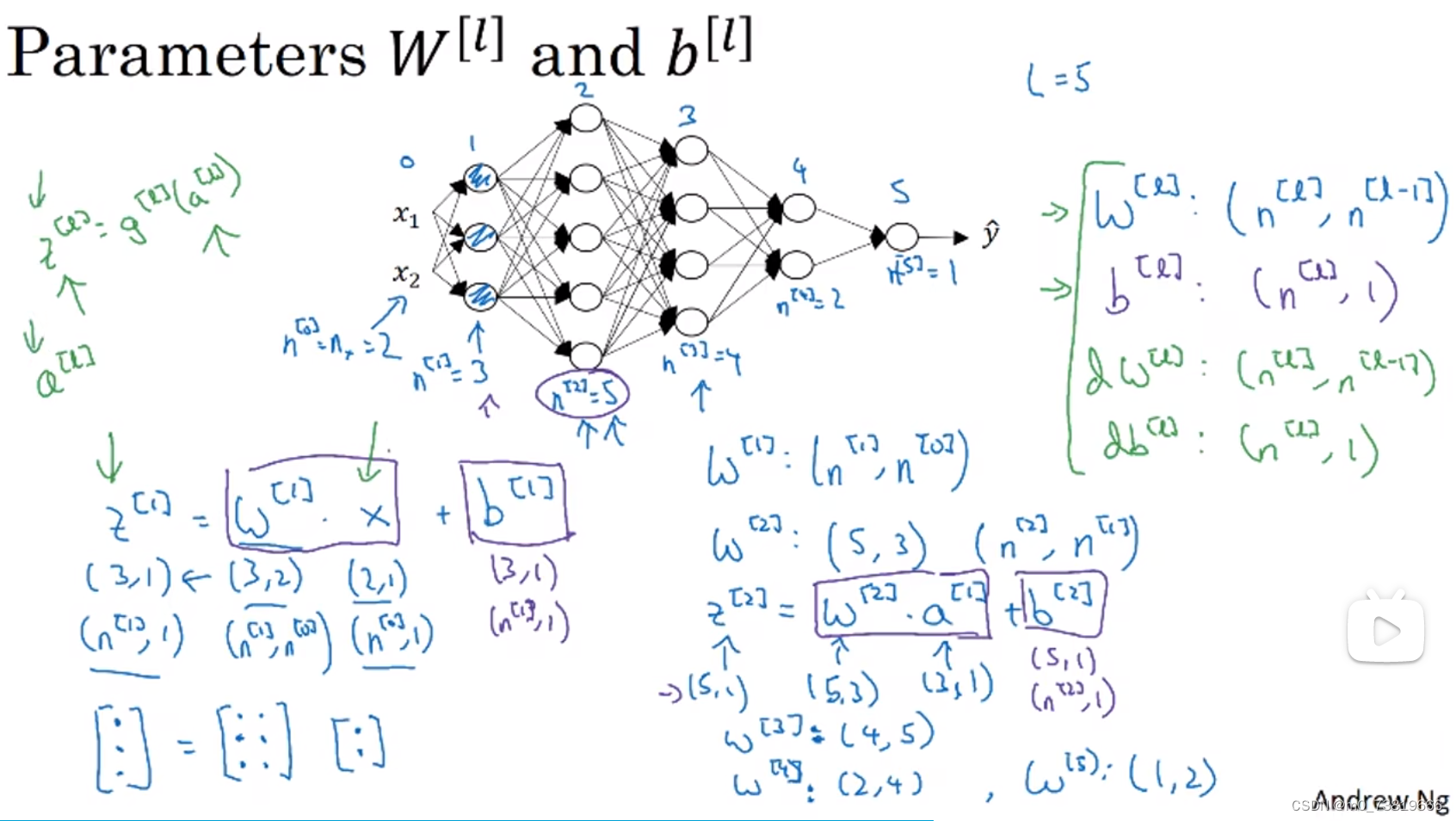
矩阵维度应该符合:
w
[
1
]
w^{[1]}
w[1]: (
n
[
1
]
n^{[1]}
n[1],
n
[
0
]
n^{[0]}
n[0]) ,
w
[
2
]
w^{[2]}
w[2]: (
n
[
2
]
n^{[2]}
n[2],
n
[
1
]
n^{[1]}
n[1]) , … ,
w
[
l
]
w^{[l]}
w[l]: (
n
[
l
]
n^{[l]}
n[l],
n
[
l
−
1
]
n^{[l-1]}
n[l−1])
b
[
l
]
b^{[l]}
b[l]: (
n
[
l
]
n^{[l]}
n[l],1)
此外,如果在做反向传播,应该有:
dim(d
w
[
l
]
w^{[l]}
w[l]) = dim(
w
[
l
]
w^{[l]}
w[l])
dim(d
b
[
l
]
b^{[l]}
b[l]) = dim(
b
[
l
]
b^{[l]}
b[l])
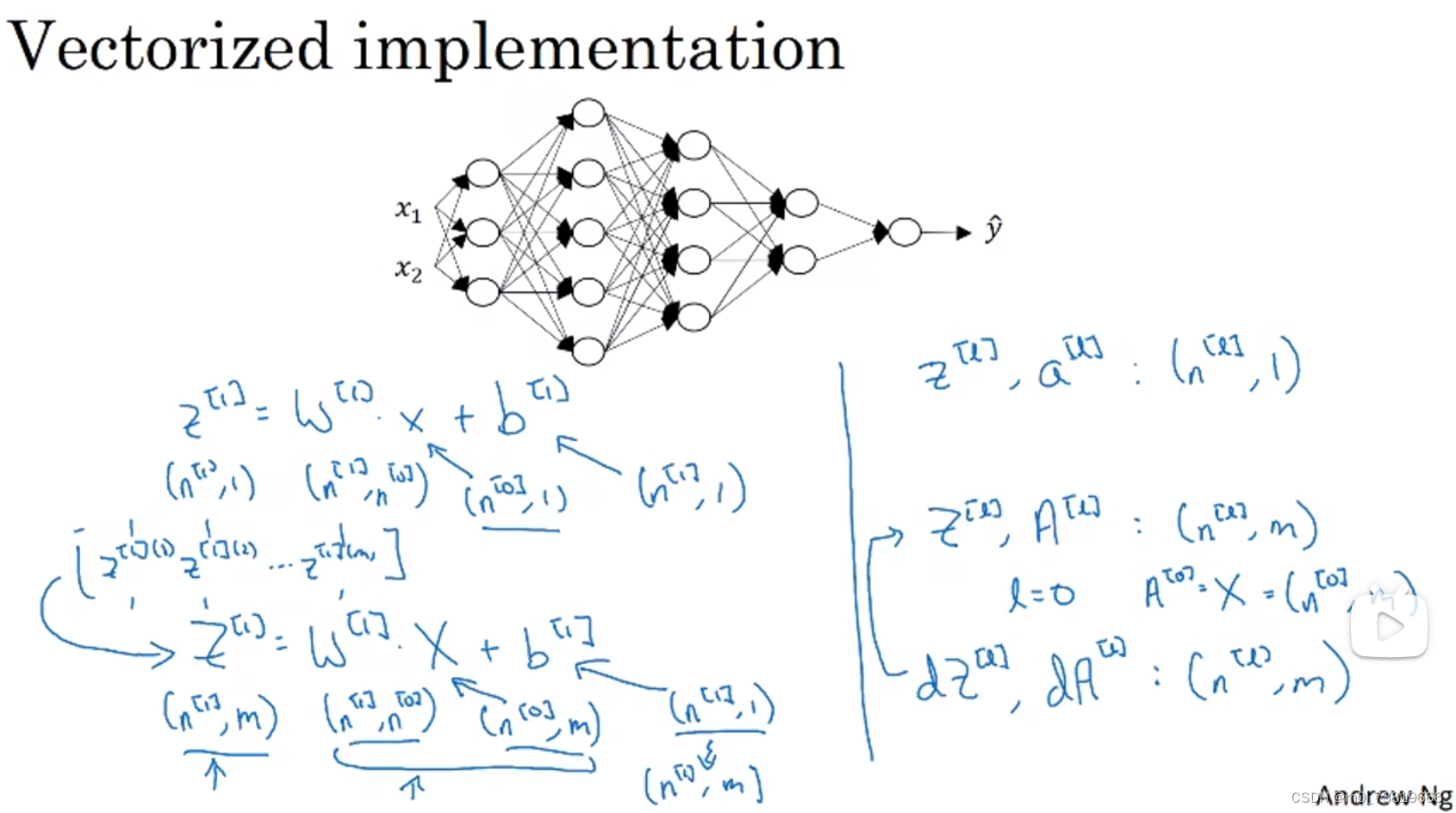
1.4.5 为什么要使用深层表示(Why deep representations)
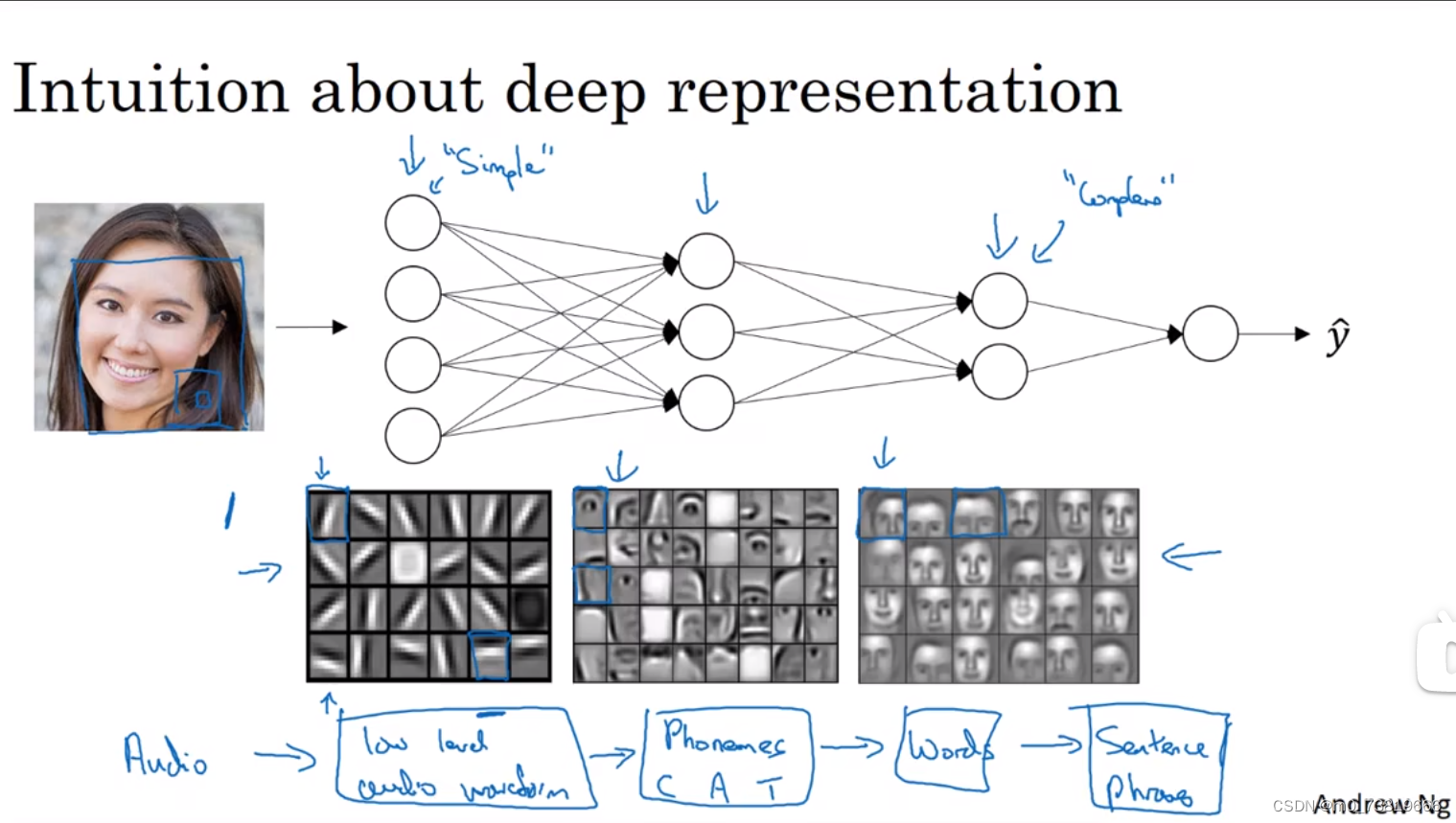
通过不同层的作用,分别对图片进行边界识别、识别局部特征、整体特征等工作。工作逐渐从简单到难。
语音识别也是一样,一段Audio作为input,最初识别音调高低,然后识别音位(Phonemes),接着是一个词语,最后是整段话。
当处理一个新的项目时,可以试着从logistic回归开始,逐渐增加隐层数量去调试,寻找比较合适的深度。
1.4.6 搭建深层神经网络模块(Building blocks of deep neural networks)

cache
z
[
l
]
z^{[l]}
z[l],能对以后的正反向传播很有用
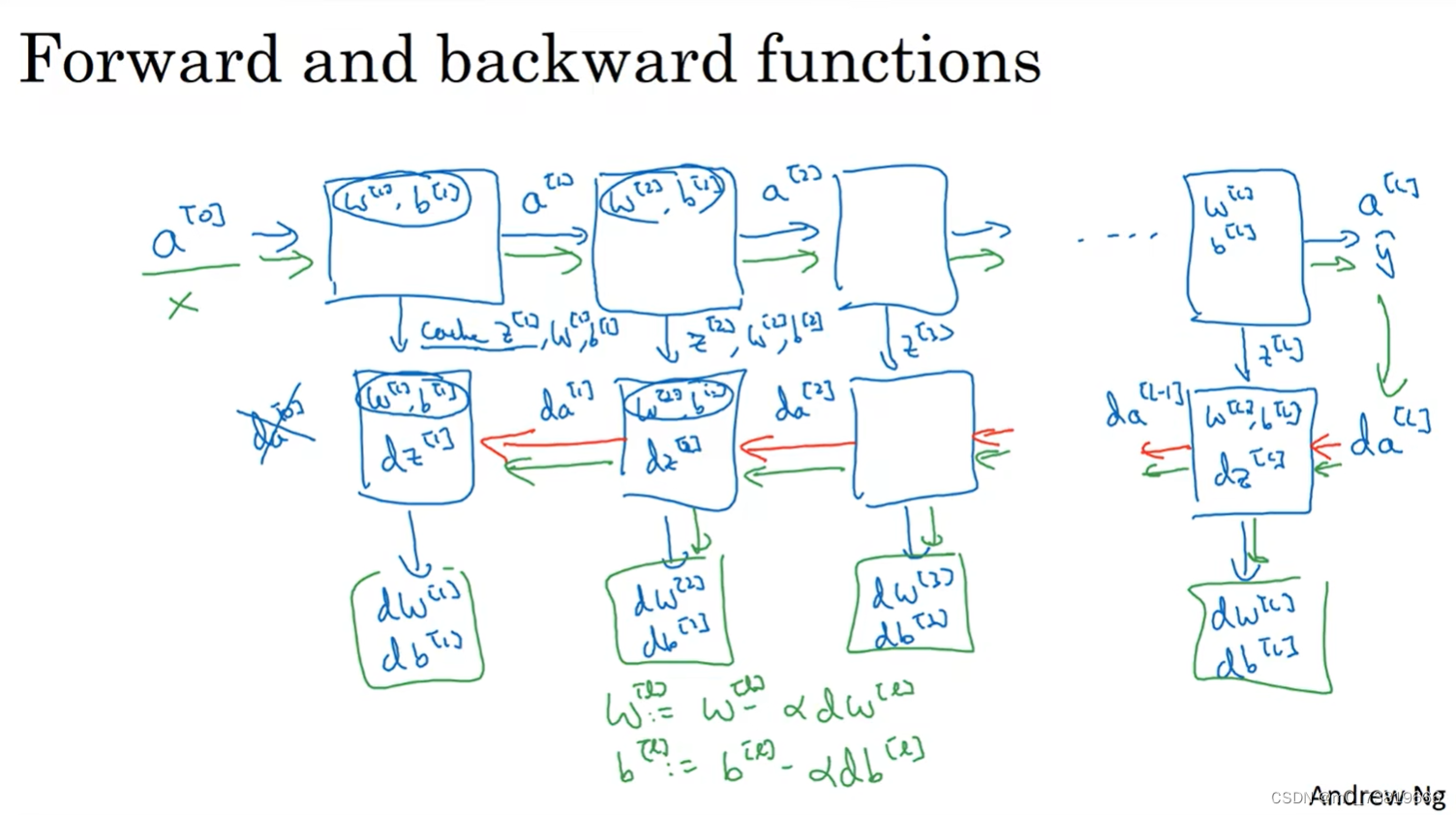
神经网络的一系列流程包括:
从
a
[
0
]
a^{[0]}
a[0]经过正向传播到达输出层,得出
y
^
\hat{y}
y^
从
y
^
\hat{y}
y^,经过反向传播,得到每个layer的导数值
最后更新参数:
w
[
l
]
w^{[l]}
w[l] =
w
[
l
]
w^{[l]}
w[l] - lr * d
w
[
l
]
w^{[l]}
w[l]
b
[
l
]
b^{[l]}
b[l] =
b
[
l
]
b^{[l]}
b[l] - lr * d
b
[
l
]
b^{[l]}
b[l]
1.4.7 参数 vs 超参数(Parameters VS Hyperparameters)
Parameters:
W
[
1
]
W^{[1]}
W[1],
b
[
1
]
b^{[1]}
b[1],
W
[
2
]
W^{[2]}
W[2],
b
[
2
]
b^{[2]}
b[2],
W
[
3
]
W^{[3]}
W[3],
b
[
3
]
b^{[3]}
b[3],…
Hyperparameters:
Learning Rate:α
Iterations
Hidden Layers:L
Hidden Units:
n
[
1
]
n^{[1]}
n[1],
w
[
2
]
w^{[2]}
w[2],…
Choice of Activation Function
…
所有的Hyperparameters控制了Parameters,所以称其为超参数
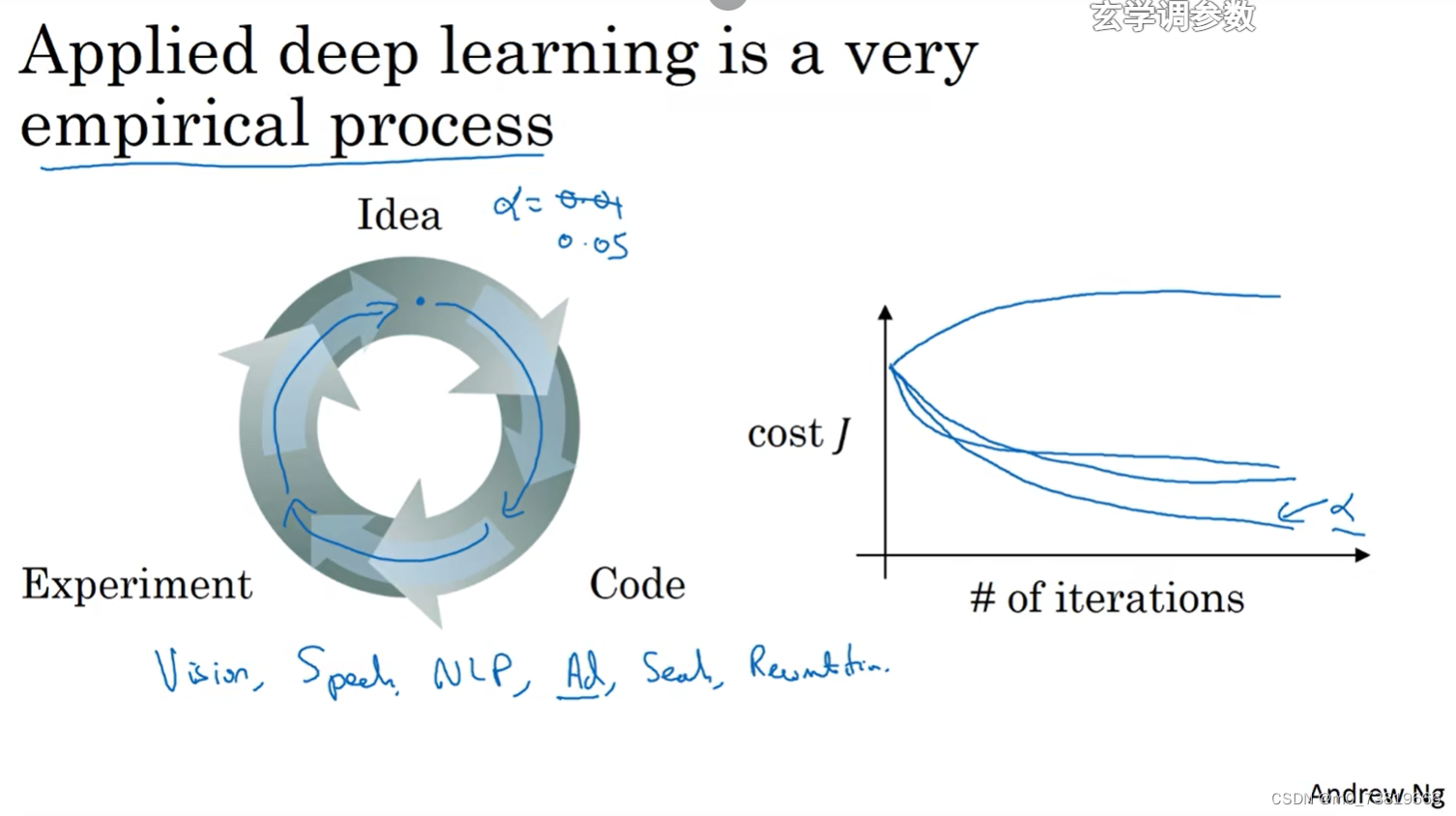
通过实验,可以将学习率从0.01提高到0.05,其他方面,也可以将学习率设置为更大的值,去观察损失函数,或许在此时,损失函数会发散。
通过不同的数值,去检验学习率在什么情况下有更好的效果。
本节所讲述的"Applied deep learning is a very ‘empirical process’"
"empirical process"就是不断地去试!试!试!从而找到最好的超参数值。
1.4.8 这和大脑有什么关系(What does this have to do with the brain)

大脑的学习过程或许非常类似于Logistic回归:输入
x
[
1
]
x_{[1]}
x[1],
x
[
2
]
x_{[2]}
x[2],
x
[
3
]
x_{[3]}
x[3]给神经元,然后加入激活函数,最后得出
y
^
\hat{y}
y^。
一个神经细胞的学习也是这样,输入
x
[
1
]
x_{[1]}
x[1],
x
[
2
]
x_{[2]}
x[2],
x
[
3
]
x_{[3]}
x[3]的电信号,最学习出其中的信息。然而,大脑的神经细胞是如何学习的,对人类来说仍然是个谜。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









