







致读者:
本篇文章是笔者的学习笔记,仅做记录用,而不作任何指导作用,大家阅读时请带着批判的眼光看待,如有错误欢迎指出。
0 基础知识
0.1 卷积核与输入
此章节作为一个基础知识章节,回顾卷积核与输入数据之间的size对应关系。
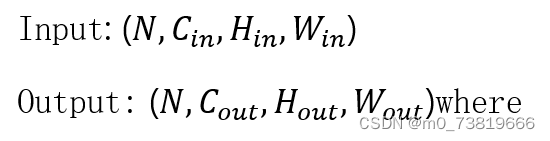
假设:
Input: [b,3,28,28]
One-kernel: [3,5,5]
Multi-kernel: [16,3,5,5]
Bias: [16]
Out: [b,16,28,28]
此处,input代表输入有b张图片,3个通道(RGB),图片像素为(32828)
对于单卷积核(One-kernel)的卷积层来说,这个卷积核的尺寸为(3 * 5 * 5),实际上是利用了三个小卷积核同时对Input的三个通道进行卷积。由于输入为3通道,所以必须用3个小卷积核同时操作,此处的3必须和input的3相等。
大部分情况下,一个卷积层(convolution)不会只有一个卷积核,大都是使用多卷积核(Multi-kernel),此处使用了16个卷积核,又由于输入为3通道,所以此处应当有16*3个小卷积核。习惯上,这里的16称为通道(channel).最终得到16个特征图(feature maps).
在Multi-kernel的情况下,加入偏置(bias),即是16个偏置。
最终output为(b * 16 * 28 * 28),此处有填充(padding),所以原图和原图大小一致。
最后,贴上卷积层图片大小计算公式:

0.2 Batch Norm
举个例子,对于sigmoid函数:
S
(
x
)
=
1
1
+
e
−
x
\mathrm{S}(\mathrm{x})=\frac{1}{1+\mathrm{e}^{-\mathrm{x}}}
S(x)=1+e−x1
在x∈(-∞,-4),(4,+∞)时,梯度非常小,这影响了神经网络的收敛速率,所以要对input进行Normalization.
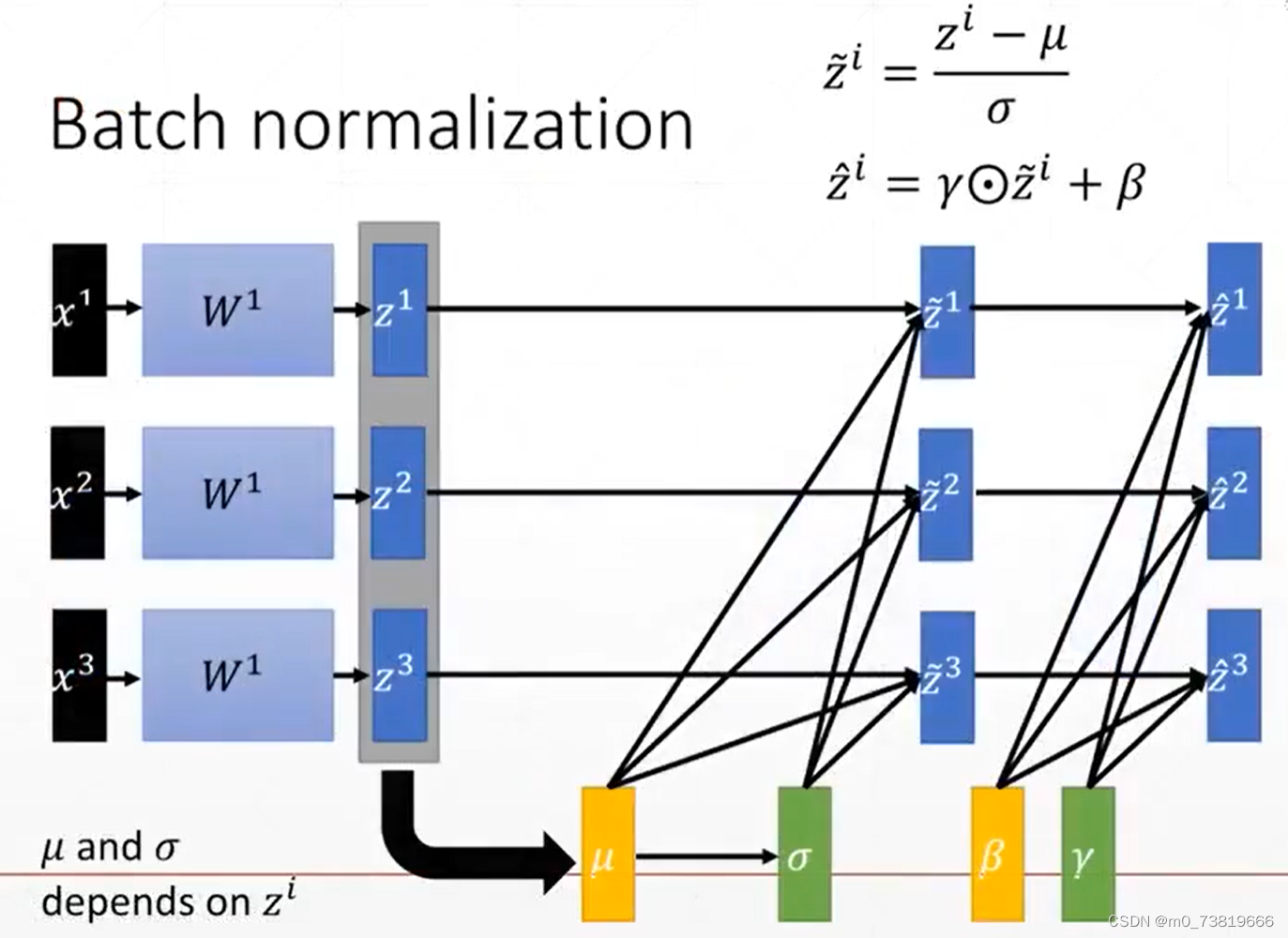
Batch Normalization的规范化写法:

Batch Norm的优点:
Converge faster
Better performance
Robust(stable,larger learning rate)
0.3 感受野(Receptive Field)
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上的映射区域的大小。
如图所示,2个3 * 3卷积核,stride = 1,padding = 0的感受野为相当于5 * 5的卷积核。
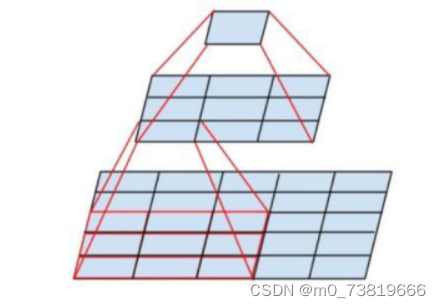
感受野的计算
第n层的感受野为:
r
n
=
r
n
−
1
+
(
k
n
−
1
)
∏
i
=
1
n
−
1
s
i
r_{n}=r_{n-1}+\left(k_{n}-1\right) \prod_{i=1}^{n-1} s_{i}
rn=rn−1+(kn−1)∏i=1n−1si
其中,
r
n
r_{n}
rn:第n层感受野大小,
k
n
k_{n}
kn第n层卷积/池化核大小。
简而言之:第n层感受野大小=上一层感受野大小+(第n层卷积核大小-1)乘以本层以前所有stride的乘积。
0.4 梯度爆炸(Gradient Exploding)和梯度弥散(Gradient Vanishing)
假设我们在训练一个深层的神经网络,共有l层,当我们忽略bias,使用线性激活函数,输出可以表示为:
y
^
=
w
[
l
]
w
[
l
−
1
]
.
.
.
w
[
2
]
w
[
1
]
x
\hat y=w^{[l]}w^{[l-1]}...w^{[2]}w^{[1]}x
y^=w[l]w[l−1]...w[2]w[1]x
这里,
z
[
1
]
=
w
[
1
]
x
,
a
[
1
]
=
g
(
z
[
1
]
)
=
z
[
1
]
z^{[1]}=w^{[1]}x,a^{[1]}=g(z^{[1]})=z^{[1]}
z[1]=w[1]x,a[1]=g(z[1])=z[1]
假如这里我们的w矩阵,均是对角线矩阵,主对角线元素为1.5,那么我们最后得到的
y
^
\hat y
y^就会非常大,呈1.5的指数倍增加。相反,如果对角线元素特别小,为0.5,
y
^
\hat y
y^就会特别小。
所以,当我们的权重矩阵w,哪怕只是比单位阵大一点点,在深层神经网络中它也会使得输出特别大,当然,w特别小也会造成不好的结果。
举个例子,在ResNet网络中,ResNet网络为152层,如果不采取任何相关措施,最后的梯度会是
∂
y
^
∂
x
=
0.
5
151
\frac{\partial {\hat y}}{\partial x}=0.5^{151}
∂x∂y^=0.5151,这会让训练变得十分困难,让我们的梯度以非常小的stride变化。
1 LeNet-5
1.1 相关背景
LeNet由Yann Lecun于1998年提出,是一种经典CNN,是现代CNN起源之一。是一种用于邮政编码识别(手写体字符识别)的非常高效的CNN。出自论文《Gradient-Based Learning Applied to Document Recognition》.
1.2 网络结构
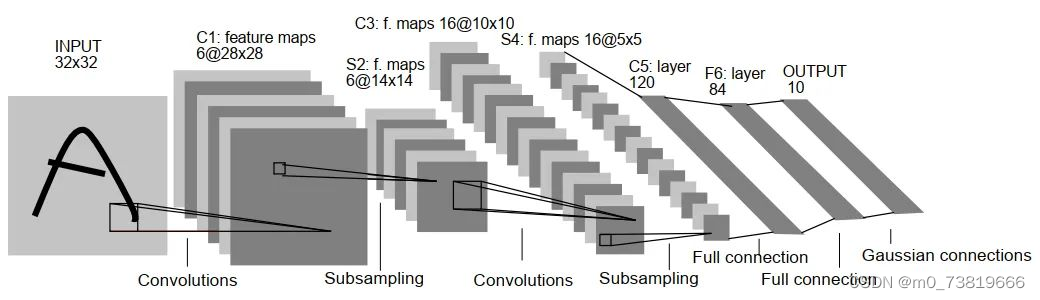
LeNet总共有六层网络,由于本网络年代久远,同时也没有在GPU上运行,包括最后的Gaussian connections现在已经鲜有人使用,本网络只进行简单介绍。
C1层: Input作为一个13232的图片(单通道,像素为32 * 32)。之后经过一个卷积层,卷积层的大小为6卷积核,每个卷积核大小为(5 * 5),这样就得到了6个feature map.
特征图大小为(32 - 5 + 1) * (32 - 5 + 1) = 28 *28
参数共享使得同个小卷积核每个神经元均使用相同的参数,因此,参数个数为(5 * 5 + 1) * 6 = 156,1为bias.
卷积后的图像大小为28 * 28,所以每个特征图有 28 * 28个神经元,所以连接数为(5 * 5 + 1) * 6 * 28 * 28 = 122304
S2层: 使用了一个下采样层(Subsampling).
不同于我们现在讲的Max-pooling,Average-pooling,此处采用了下采样层,采样原理为隔行采样,在AlexNet之后,我们比较熟制的Pooling操作就开始广泛使用了。
C3层: 16个卷积核,卷积模板大小为5 * 5
特征图大小为: (14 - 5 + 1) * (14 - 5 + 1) = 10 * 10
S4层: 下采样层,原理同S2.
C5层: [120,16,5,5] 的卷积核,padding = 0,stride = 1,本层虽然是个卷积层,但是S4层正好是5 * 5,和小卷积核的尺寸相同,所以可以看作一个120个神经元的全连接层(Full connection).
F6层: 全连接层,共有84个神经元,与C5层进行全连接,即每个神经元都与C5层的120个特征图进行连接。
Output层: 全连接层,Gaussian connections,采用了RBF函数径向欧氏距离函数),目前已被Softmax取代。
RBF:
y
i
=
∑
j
=
0
83
(
x
j
−
w
i
j
)
2
y_{i}=\sum_{j=0}^{83}\left(x_{j}-w_{i j}\right)^{2}
yi=∑j=083(xj−wij)2
1.3 总结
LeNet-5与现在大部分卷积神经网络还是有差别的,LeNet采用sigmoid作为激活函数,目前大多使用tanh,ReLU,Leakly ReLU.
LeNet-5下采样与现在的方式不同,目前大多使用池化层。
目前的分类问题大多在最后的输出层采用SoftMax,而LeNet使用Gaussian connections.
LeNet-5在当时计算机算力较低的情况下,已经是非常高效的CNN,但是还是缺乏大规模训练数据,在复杂问题的处理并不理想。
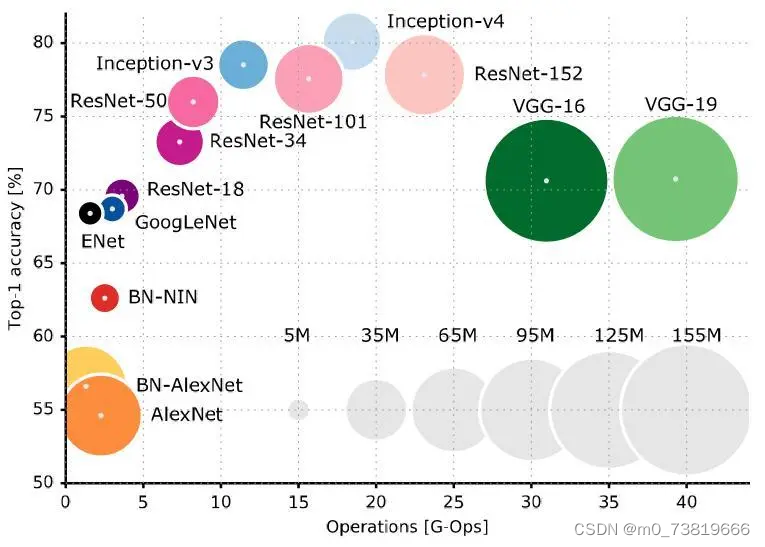
2 AlexNet
2.1 相关背景
在LeNet之后,深度学习的发展较为平缓,一直到了深度学习界里程碑的作品出现——AlexNet.
AlexNet是2012年ISLVRC 2012(ImageNet Scale Visual Recogniton Challenge)的冠军网络,分类准确率提高了惊人的十多个点,AlexNet的提出,使得深度学习开始蓬勃发展。
AlexNet是由G.Hinton(第三作者)和他的学生Alex Krizhevsky设计的,G.Hinton被人称为“神经网络教父”。
AlexNet使用了两块GTX 580(3GB * 2),将kernel均分在两张显卡上,在当时是非常新颖的做法,所以着重学习Alexnet在当时的影响力。
该网络的亮点在于:
- 使用了ReLU作为激活函数,而非传统的Sigmoid和Tanh
- 首次利用GPU进行网络加速训练
- 使用LRN对局部特征进行归一化(目前以Batch Norm为主)
- 使用重叠最大池化(Max pooling)
- 使用Dropout机制
数据集: ImageNet,训练集120万张图片,验证集5万张图片,测试集15万张图片,1000个类别,并且有多种不同的分辨率。
论文原文:
http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
2.2 网络结构
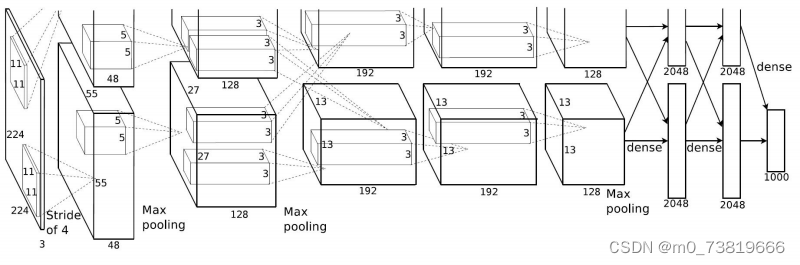
AlexNet总共有输入层和8个layers,其中包含5个卷积层和3个全连接层,其中最后一个全连接层也是softmax输出层。
1.卷积层,输入图像尺寸为3 * 224 * 224,第一次卷积是会padding 3个像素变为 3 * 227 * 227,卷积核大小为96 * 3 * 11 * 11,stride为4.
所以,C1层的输出图像为[(227 - 11) / 4 + 1] * [(227 - 11) / 4 + 1] = 55 * 55,最终输出数据为 96 * 55 * 55,其中,96个卷积核分别在两个GPU上进行运算,即48 * 2.
2.池化层(Max Pooling),池化尺寸为3 * 3,stride = 2. pooling后尺寸为96 * [(55 - 3) / 2 + 1] * [(55 - 3) / 2 + 1] = 96* 27 * 27,然后进行归一化,运算尺寸为5 * 5.
注意 此处的归一化并非目前经常使用的BN(BN于15年发表),而是局部响应归一化LRN(Local Response Normalized),在2015年发表的"Very Deep Convolutional Networks for Large-Scale Image Recognition"中说明了,LRN在IILSVRC数据集上不能对性能进行改善。当前主流模型也基本不使用LRN.这里不对其进行深入学习。
此外,可以看到,本文采用的池化(Pooling)操作,尺寸为3,步长为2,Size>Stride,这正是我们之前提到的重叠池化(Overlapping Pooling).
3.卷积层,输入为上一层的feature map:96 * 27 * 27,将数据分别在两个不同的的GPU中进行运算,每组数据的大小为48 * 27 * 27,卷积核大小为128 * 48 * 5 * 5,padding = 2,stride = 1,每组得出的output为128 * [(27 - 5 + 2 * 2) / 1 + 1] * [(27 - 5 + 2 * 2) / 1 + 1] = 128 * 27 * 27,得出结果后经过ReLU层,尺寸仍然为128 * 27 * 27,这是每个GPU上的数据,如果计算总数据,应该再乘以2.
4.池化层(Max pooling),池化运算的尺寸为3 * 3,步长为2,池化后的尺寸为(27 - 3) / 2 + 1 = 13,即,总数据尺寸为2组128 * 13 * 13的像素层,经过5 * 5的归一化处理。
5.卷积层,padding = 1,同样数据还是在两个GPU下计算,每个GPU内卷积核尺寸为192 * 128 * 3 * 3,得到的数据为2组192 * 13 * 13的像素层,同样也要经过ReLU.
6.卷积层,padding = 1,每个GPU内卷积核尺寸为192 * 192 * 3 * 3,最终得到的数据仍为2组192 * 13 *13,最后经过ReLU.
7.卷积层,padding = 1,每个GPU内卷积核尺寸为128 * 192 * 3 * 3,最终得到的数据为2组128 * 13 * 13,最后经过ReLU.
8.池化层(Max pooling),池化尺寸为3 * 3,stride = 2,同理,这里依然是overlapping pooling,最后得到的output尺寸为: 2组 128 * 6 * 6的像素层数据.
9.全连接层1: 这里的输入数据为256 * 6 * 6,采用4096 * 256 * 6 * 6尺寸的滤波器对上层数据进行运算,得到的结果通过ReLU生成4096个值,再通过dropout输出本层结果值。
10.全连接层2: 这里的结构和上一层相同,经过ReLU后再经过dropout处理数据,得出4096个结果。
11.全连接层3: 本层有1000个神经元与上层进行全连接,最终得出被训练的数值。
2.3 总结
AlexNet作为2012年的冠军网络,虽然现在已经很少有用这种结构,但是这个方法产生了巨大的影响。相比于网络结构,我们更应该去学习作者的思路,作者解决问题的能力,作者是怎样受到启发能够解决问题的。
笔者通过学习LeNet,AlexNet了解到了机器学习发展历史,同时也由于这些网络年代久远,结构较为简单,对内部的参数运算有了更深层次的理解。
3 VGG
3.1 相关背景
VGG是2014年牛津大学的Visual Geometry Group提出的,在ILSVRC-2014获得亚军(第一名是GoogNet)。相比于AlexNet,VGG使用了更深的网络结构,同时也使用了更小的卷积核,证明了增加网络深度能够在一定程度上影响网络性能。
该网络的亮点在于:
- 小卷积核组。作者通过堆叠多个3 * 3卷积核(甚至1 * 1)来替代大卷积核,例如AlexNet中的11 * 11,这样可以减少所需参数,这是笔者认为最佳的创新点。
- 小池化核。VGG使用2 * 2卷积核。
- 网络更深,特征图更宽.VGG是一组网络,其后的数字代表网络隐藏层数,最高达到了VGG-19.网络中,卷积层专注于扩大通道数,池化层专注于缩小高和宽,计算量逐渐放缓。
- 将卷积核替代全连接层。作者在测试阶段将三个全连接层替换为三个卷积,使得测试得到的模型结构可以接收任意高度或宽度的输入。
- 多尺度。作者从多尺度训练可以提升性能受到启发,训练和测试时使用整张图片的不同尺度的图像,以提高模型的性能。
- 不使用LRN.作者发现深度网络中LRN作用并不明显。
3.2 网络结构
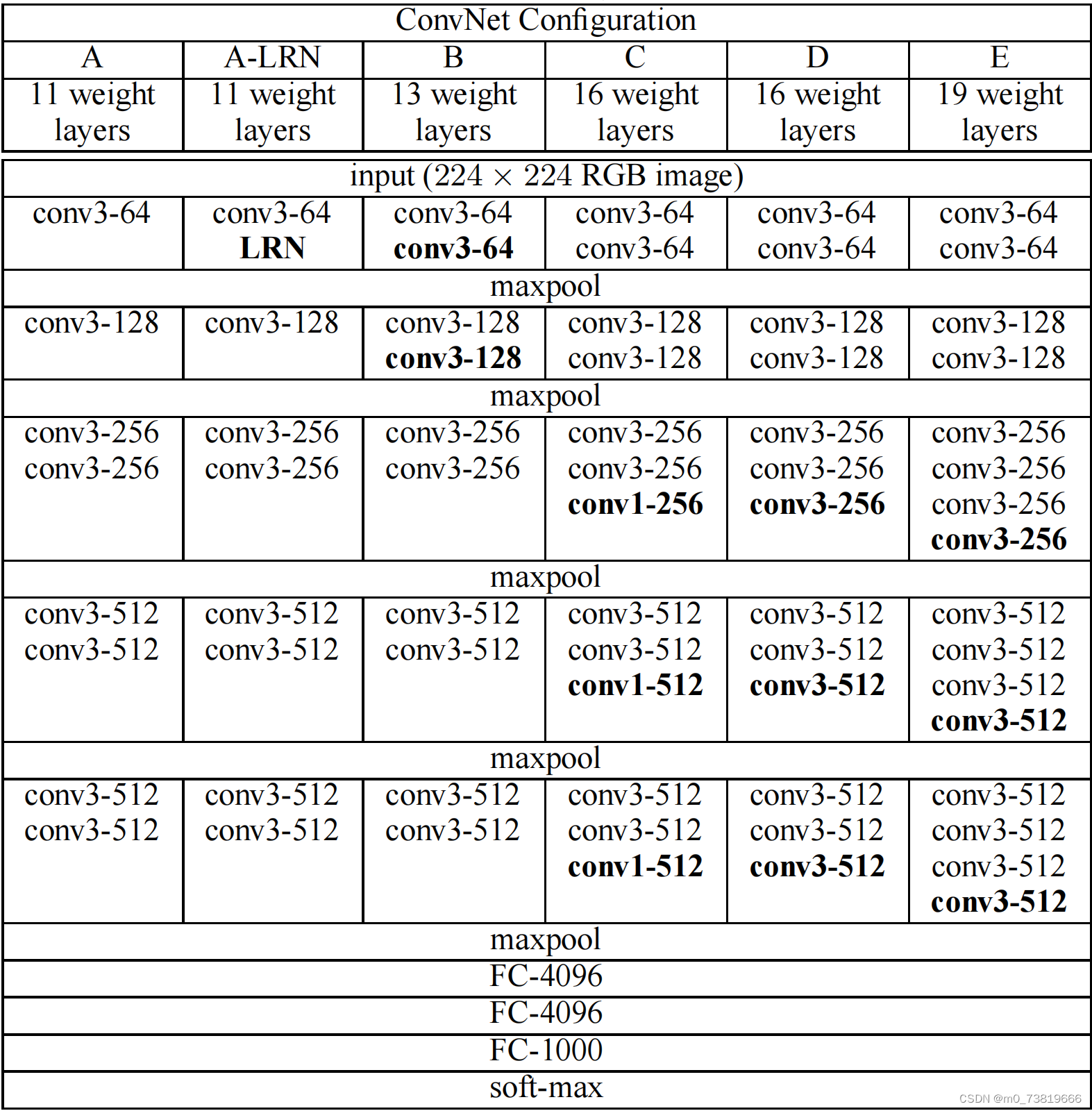

卷积层全部为3 * 3的卷积核,用conv3-xxx来表示,xxx表示卷积核的通道数。作者实验了6种网络结构,其中VGG-16和VGG-19性能好。证明了增加网络深度能在一定程度上影响最终的性能。
以VGG-16为例:
convolution default: kernel_size = 3,padding = 1
pooling default: size = 2,stride = 2
input: 3 * 224 * 224
2 * conv3-64
output: 64 * 224 * 224
maxpool
output: 64 * 112 * 112
3 * conv3-128
output: 128 * 112 * 112
maxpool
output: 128 * 56 * 56
3 * conv3-256
output: 256 * 56 * 56
maxpool
output: 256 * 28 * 28
3 * conv3-512
output: 512 * 28 * 28
maxpool
output: 512 * 14 * 14
3 * conv3-512
output: 512 * 14 * 14
maxpool
output: 512 * 7 * 7
2 * FC-4096
output: 4096 * 1 * 1
FC-1000
output: 1000 * 1 * 1
参数数量:

可见,VGG-16的参数主要集中在全连接层,而根据统计,VGG-16的参数有138M,如此高的参数我们可以预期VGG-16网络有非常高的拟合能力,然而缺点也同样显而易见,参数量的提高导致了训练时间增长,调参难度变大,需要的存储容量大。
3.3 优点与创新点
VGG网络不同于LeNet,AlexNet,现在仍然有许多模型以VGG网络为骨干,笔者决定花较多时间学习VGG网络。
3.3.1 小卷积核
VGG网络的作者在一定程度上受AlexNet启发,许多思路都与AlexNet进行比较,采用小卷积核就是其中一项,下面贴上论文原文:
Rather than using relatively large receptive fields in the first conv. layers (e.g. 11×11 with stride 4 in (Krizhevsky et al., 2012), or 7×7 with stride 2 in (Zeiler & Fergus,2013; Sermanet et al., 2014)), we use very small 3 × 3 receptive fields throughout the whole net, which are convolved with the input at every pixel (with stride 1). It is easy to see that a stack of two 3×3 conv. layers (without spatial pooling in between) has an effective receptive field of 5×5; three such layers have a 7 × 7 effective receptive field. So what have we gained by using, for instance, a stack of three 3×3 conv. layers instead of a single 7×7 layer?
- First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative.
- Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3 × 3 convolution stack has C channels, the stack is parametrised by 3 ( 3 2 C 2 ) = 27 C 2 3(3^2C^2)=27C^2 3(32C2)=27C2weights; at the same time, a single 7 × 7 conv. layer would require 7 2 C 2 = 49 C 2 7^2C^2=49C^2 72C2=49C2parameters, i.e.81% more. This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
由上文的AlexNet可知,AlexNet的第一个卷积层就采用了11 * 11的大型卷积核,而在本网络中,采用了连续的几个3 * 3的卷积核代替之,其优点是在具有相同感受野的条件下,能够增加网络深度来保证学习更复杂的模式,而且能够使得参数更少。
感受野(Receptive Field)相关知识已经在这里学习了。
在这里简单的举个例子:
3个3 * 3的卷积核与1个7 * 7的卷积核相比(stride = 1,padding = 0)
r
0
r_{0}
r0的默认感受野为1,对于3个3 * 3的卷积核:
r
1
r_{1}
r1 =
r
0
r_{0}
r0 + (3 - 1) * 1 = 3
r
2
r_{2}
r2 =
r
1
r_{1}
r1 + (3 - 1) * 1 * 1 = 5
r
3
r_{3}
r3 =
r
2
r_{2}
r2 + (3 - 1) * 1 * 1 * 1 = 7
而7 * 7卷积核的感受野为:
r
1
r_{1}
r1 =
r
0
r_{0}
r0 + (7 - 1) * 1 = 7
可以从公式中看出,3个3 * 3的卷积核与1个7 * 7的卷积核的感受野是相同的。
同理,2个3 * 3的卷积核与1个5 * 5的卷积核的感受野是相同的。
3.3.2 小池化核
VGG-16使用的所有池化采用kernel size = 2 * 2,stride = 1,比AlexNet使用的更小,小kernel使得更能捕获细节变化。当然,此处依然使用overlapping pooling.
3.3.3 使用卷积替代全连接层
作者在测试阶段把网络中三个全连接层依次变为1个conv 7 * 7,2个conv1 * 1,由于没有全连接层,网络中的feature map不会固定,所以网络对任意大小的输入都可以处理。
3.3.4 1 * 1卷积核
作者认为1 * 1的卷积可以增加决策函数的非线性能力,非线性是由激活函数ReLU决定的。1 * 1卷积核更加注重的是当前卷积核的信息整合,对feature map能够很好的将为或者升维。在3 * 3或者5 * 5卷积核进行卷积前先降低feature map的维度,能够提升计算速度。
3.4 总结
VGG网络作为2014年亚军网络,与GoogNet是2014双雄,虽然只是拿到亚军,但是其中提出的思想值得思考,简而言之:卷积核小点好,网络深点好,LRN用处不大。但是,VGG的缺点也十分显而易见:海量的参数,相比于GoogNet,确实是差距明显。虽然前面的小卷积核能够有效的减少参数,但是VGG的主要参数来源是全连接层,而VGG-16有三个全连接层之多,所以这使得train一个vgg网络要花费更长的时间。
4 GoogLeNet

4.1 相关背景
GoogLeNet与VGG网络是2014年ImageNet竞赛的双雄,而GoogLeNet正是那年的冠军,为了纪念最经典的LeNet网络,论文中提到将网络命名为"GoogLeNet".
与VGG网络相同的是,GoogLeNet的理念也是go deeper,然而GoogleNet做了比VGG更大胆的尝试,它并非像VGG一样继承了LeNet和AlexNet的框架,GoogleNet网络有22层,却比AlexNet和VGG网络都小很多。
随着神经网络的快速发展,网络的层数不断增加,工作者们也通过更好的硬件来训练网络,同时也会带来海量的数据和更庞大的网络模型。这样的手段虽然能够带来更好的预测识别效果,但也是有很大的缺陷:
1.更深更宽的网络会带来过拟合(overfitting)
2.庞大的计算量消耗更多的资源
2014年,Google团队受Network in Network和稀疏网络的启发,提出了名为Inception的结构。
GoogLeNet的优点:
- 使用了1 * 1卷积核,减少feature map数
- 采用了模块化结构(Inception-v1),方便添加和修改
- 网络最后采用全剧平均池化(Global Average Pooling)+全连接层+SoftMax
- 额外增加了2个辅助分类器,用以避免梯度消失,辅助分类器是将中间某一层的输出用作分类,并用一个较小的权重加到最终分类结果中。
论文原文:
GoogLeNet
4.2 Inception
当我们要构建一个卷积层时,我们需要选择是使用3 * 3还是5 * 5的卷积核去操作,其次,还要选择是否使用池化层,这里我们可以使用inception,它能够“帮你选择”。
我们知道,卷积层相比较于全连接层,最大的优点就是权值共享(weights share)和稀疏连接(Sparse Connectivity),Inception结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
Inception V1:主要提出了多分支(多分辨率的filter组合)的网络
Inception V2:主要提出了BN层,提高网络性能(减少梯度消失和爆炸、防止过拟合,代替dropout层使初始化学习参数更大)
Inception V3:主要提出了分解卷积,把大卷积因式分解成小卷积和非对称卷积
4.2.1 Inception V1
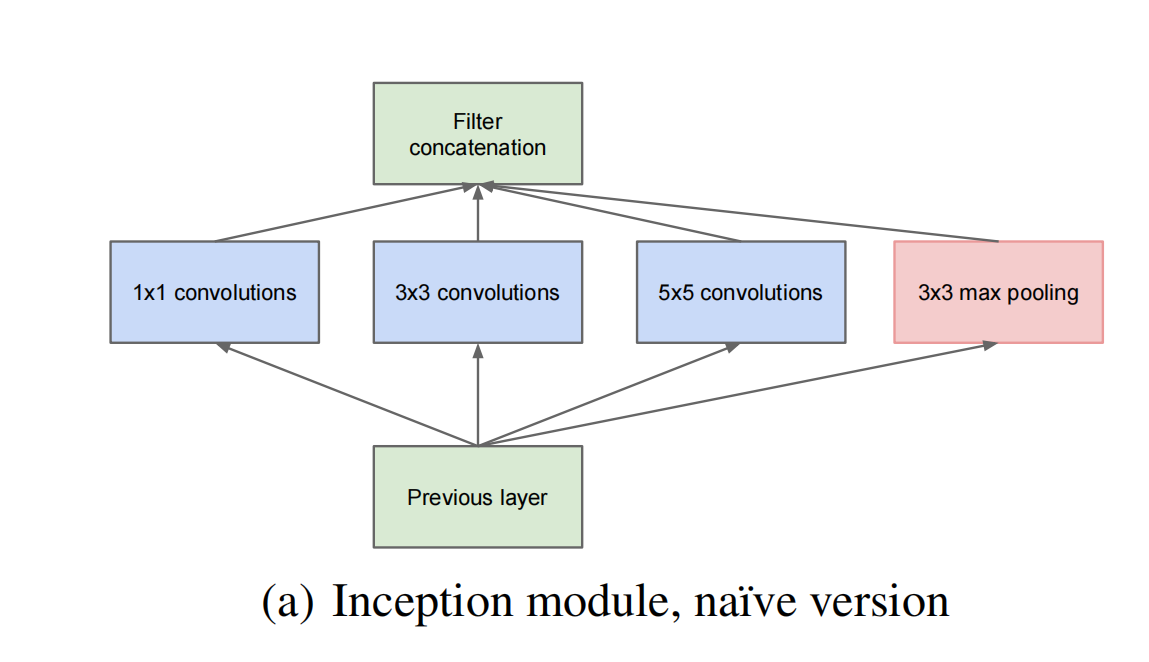
原始的Inception结构:
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度的融合。
- 卷积核大小采用1,3,5,是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding=0,1,2,那么卷积之后接可以得到相同维度的特征,然后这些特征可以直接拼接在一起。
- pooling十分有效,所以Inception也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3 * 3和5 *5卷积的比例也要增加。

如我们所知,inception的开发的初衷之一就是降低参数量,(b)图改进的inception相较于(a)图,又能够很好的降低参数量,这里我们来举个例子:
assume input_size = [192 * 28 * 28]
kernel_size=[32 * 192 * 5 * 5]
parameters_number=192 * 28 * 28 * 32 * 5 * 5=120M
if with 1 * 1 kernel,
C1:kernel_size = [16 * 192 * 1 * 1]
C2:kernel_size= [32 * 16 * 5 * 5]
parameters_number=192 * 28 * 28 * 16 + 16 * 28 * 28 * 32 * 5 * 5=2.4M + 10.0M = 12.4M
可见,参数量缩小至1\10
4.2.2 Inception V2
4.2.3 Inception V3
通过大量使用Inception模块的降维和并行性能钢结构实现,允许减轻结构变化对附近组件的影响。使Inception更有灵活性。
5 ResNet
5.1 相关背景
ResNet,残差网络(Residual Network)是2015年ImageNet的冠军网络,最大的突破在于它使得我们可以训练成功非常深的神经网络,ResNet有152层之多,而ResNet之前,由于梯度消失(Gradients Vanishing)的问题,我们无法训练非常深的神经网络。
5.2 Residual block
5.2.1 残差块的结构

图中结构的推导公式如下:
a
[
l
]
−
−
L
i
n
e
a
r
−
−
R
e
L
U
−
−
a
[
l
+
1
]
−
−
L
i
n
e
a
r
−
−
R
e
L
U
−
−
a
[
l
+
2
]
a^{[l]}--Linear--ReLU--a^{[l+1]}--Linear--ReLU--a^{[l+2]}
a[l]−−Linear−−ReLU−−a[l+1]−−Linear−−ReLU−−a[l+2]
g
(
)
g()
g()表示非线性ReLU
z
[
l
+
1
]
=
w
[
l
+
1
]
∗
a
[
l
]
+
b
[
l
+
1
]
z^{[l+1]}=w^{[l+1]} * a^{[l]}+b^{[l+1]}
z[l+1]=w[l+1]∗a[l]+b[l+1]
a
[
l
+
1
]
=
g
(
z
[
l
+
1
]
)
a^{[l+1]}=g(z^{[l+1]})
a[l+1]=g(z[l+1])
z
[
l
+
2
]
=
w
[
l
+
2
]
∗
a
[
l
+
1
]
+
b
[
l
+
2
]
z^{[l+2]}=w^{[l+2]} * a^{[l+1]}+b^{[l+2]}
z[l+2]=w[l+2]∗a[l+1]+b[l+2]
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
)
a^{[l+2]}=g(z^{[l+2]})
a[l+2]=g(z[l+2])
以上是我们熟知的正向传播的过程,这条路径我们在此处称为"main path"
而在我们的ResNet中,我们可以进行如下操作:要将
a
[
l
]
a^{[l]}
a[l]引出来,放在
a
[
l
+
2
]
a^{[l+2]}
a[l+2]前的
R
e
L
U
ReLU
ReLU之前,这样的连接称作"short cut"/“skip connection”.
所以,我们上述的最后一个等式就变为了:
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
+
a
[
l
]
)
a^{[l+2]}=g(z^{[l+2]}+a^{[l]})
a[l+2]=g(z[l+2]+a[l])
以上,这就是残差块的主要思路。
论文的作者们(Kaiming He等)发现:当我们使用这种残差块(Residual block)时,我们就可以去构建层数较深的神经网络,构建的方法也正如我们所想的一样:只需要去堆叠残差块即可。此外,论文中,将我们通常认为的神经网络(没有使用残差块)称作"plain network".















 1680
1680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









