




一、网址
点击进入:当当网9月份图书畅销榜
二、解析网页结构
1.判断网页规律
通过判断下面两个链接,只有最后的数字1改为了2,说明最后一个数字代表页数,这里我们可以使用以下代码进行翻页:
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2025-9-1-{}'.format(page)


2.每个图书的结构组成
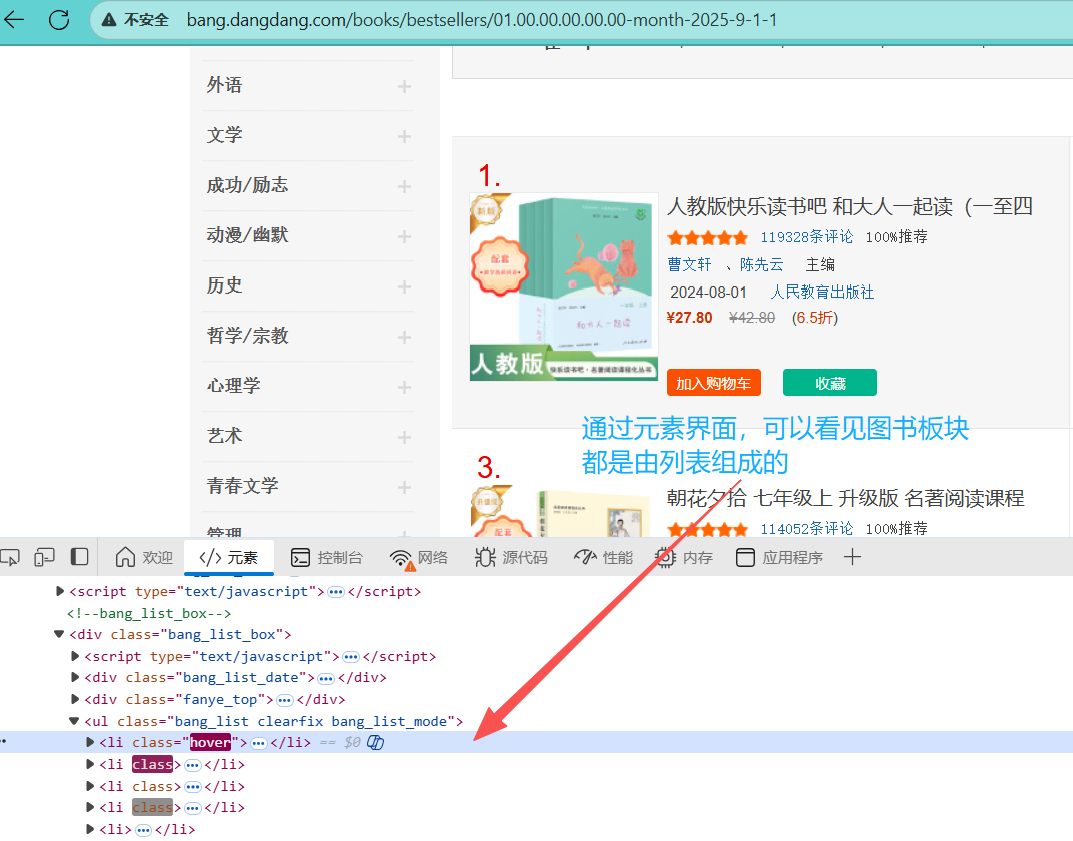
三、获取网页内容
1.向目标网址发请求
def get_html(self, page):
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2025-9-1-{}'.format(page)
response = requests.get(url, headers=self.headers, timeout=10)
timeout的作用是:如果网页没有响应请求,设置10秒超时
2.设置网页返回内容的编码

网页的编码为:gb2312
设置网页编码格式:
response.encoding = 'gb2312'
3.获取网页内容
text = response.text
四、获取图书信息
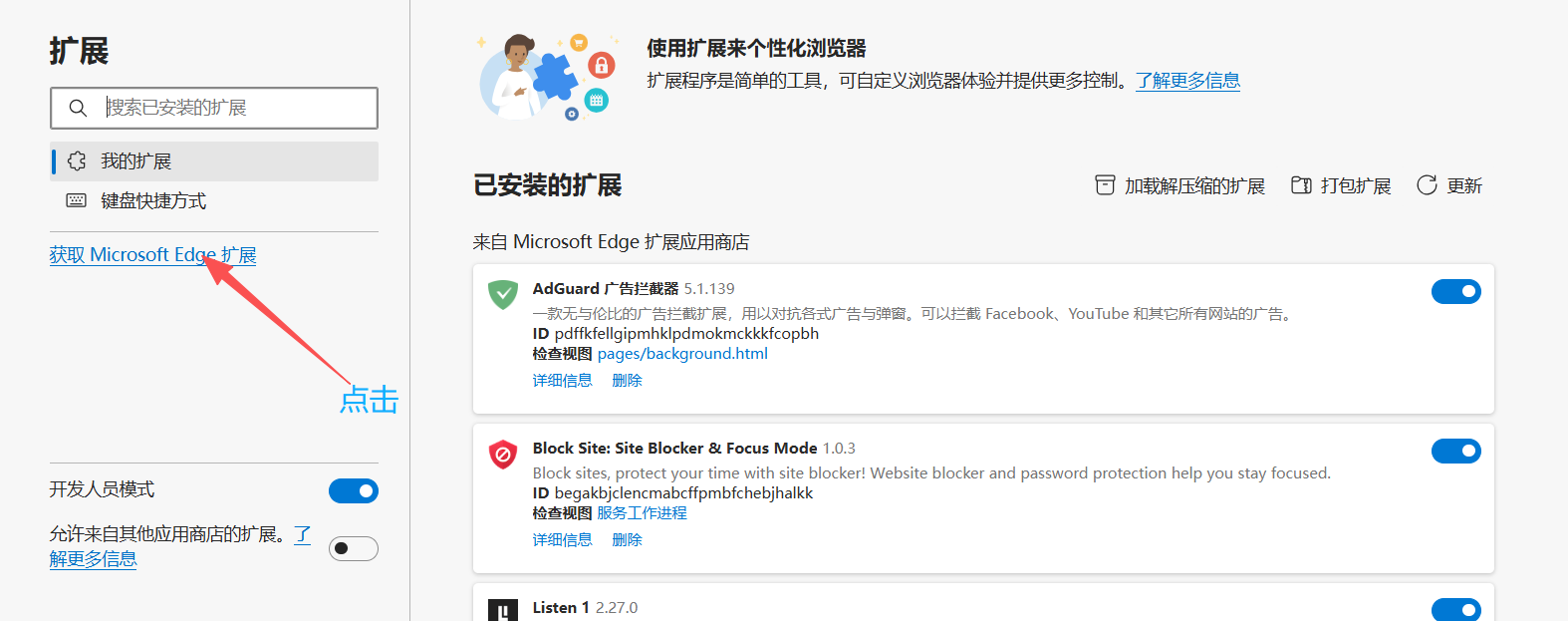
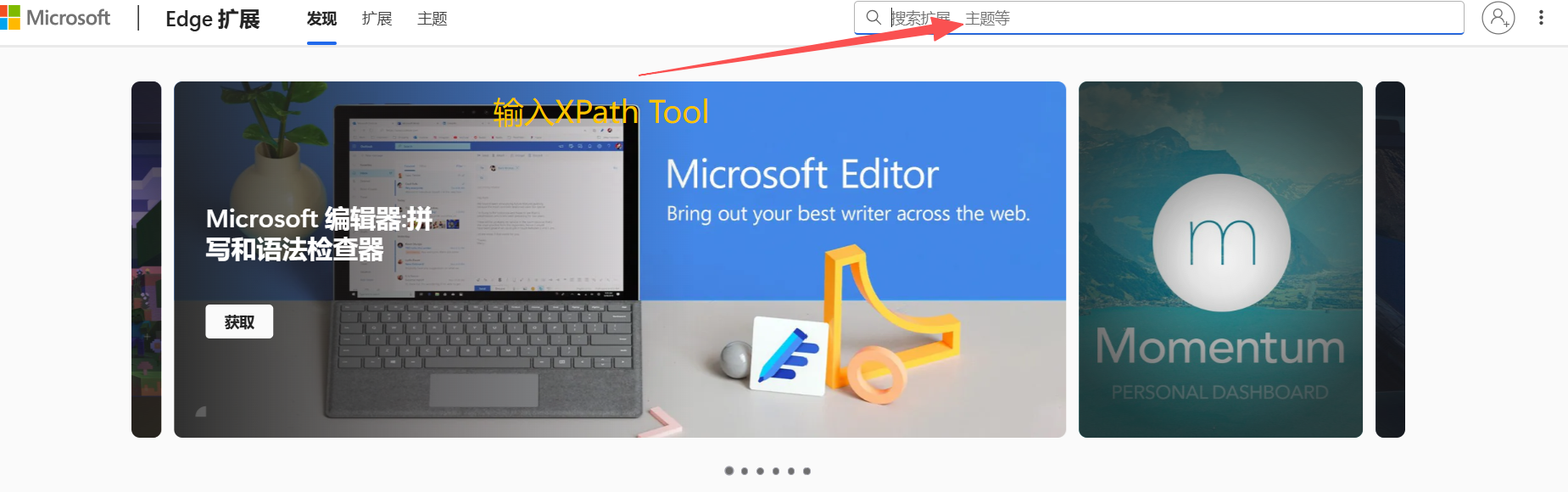
1.下载XPath Tool插件
XPath Tool,是一个可以通过Xpath获取数据的小插件,我用的是edge浏览器,接下来是安装教程:>>
①:
如果点击之后,网页显示无法响应内容,多刷新几次就行了
②:
③:
④:
⑤:
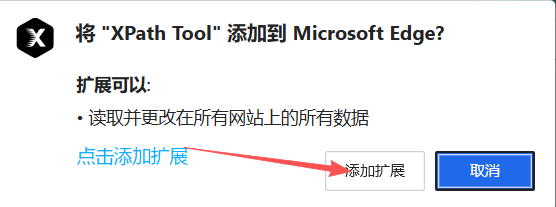

安装成功
2.使用XPath Tool工具查看输入的xpath是否能够获取所有图书的信息
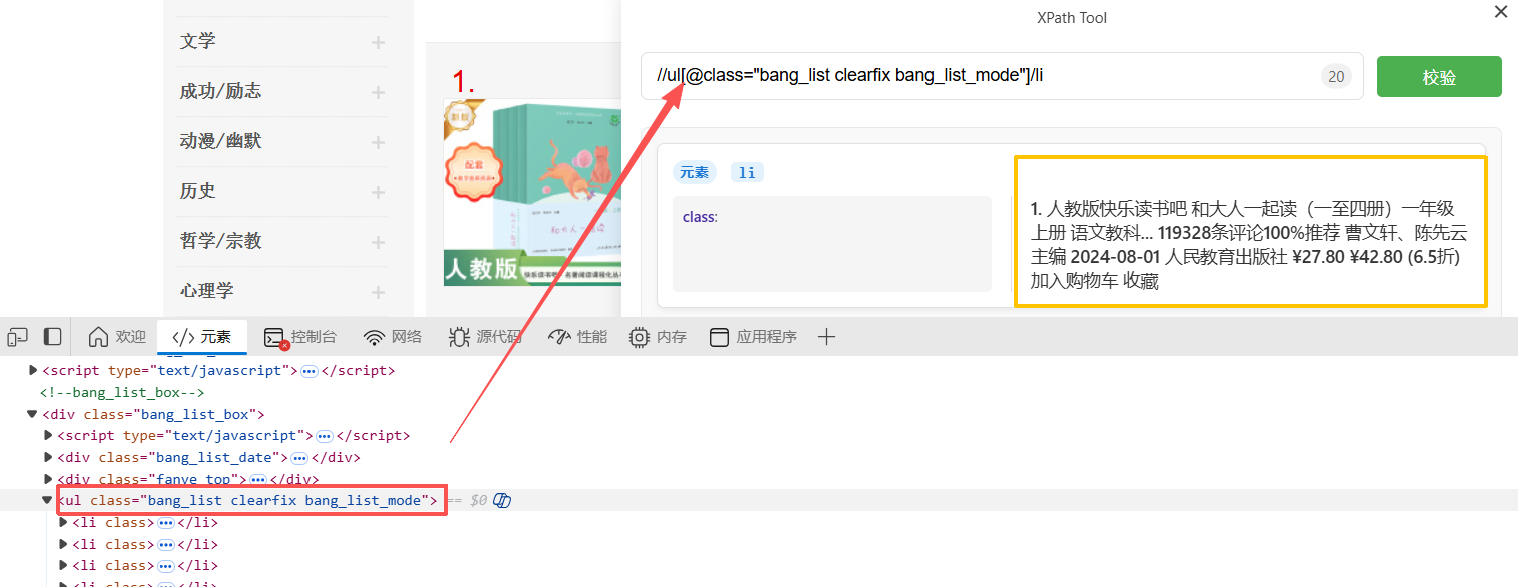
xpath路径:
//ul[@class="bang_list clearfix bang_list_mode"]/li
XPath Tool成功获取了所有图书的信息,说明我们的xpath路径是对的
- 接下来获取单个图书的信息
这里我们先获取图书的书名:>>
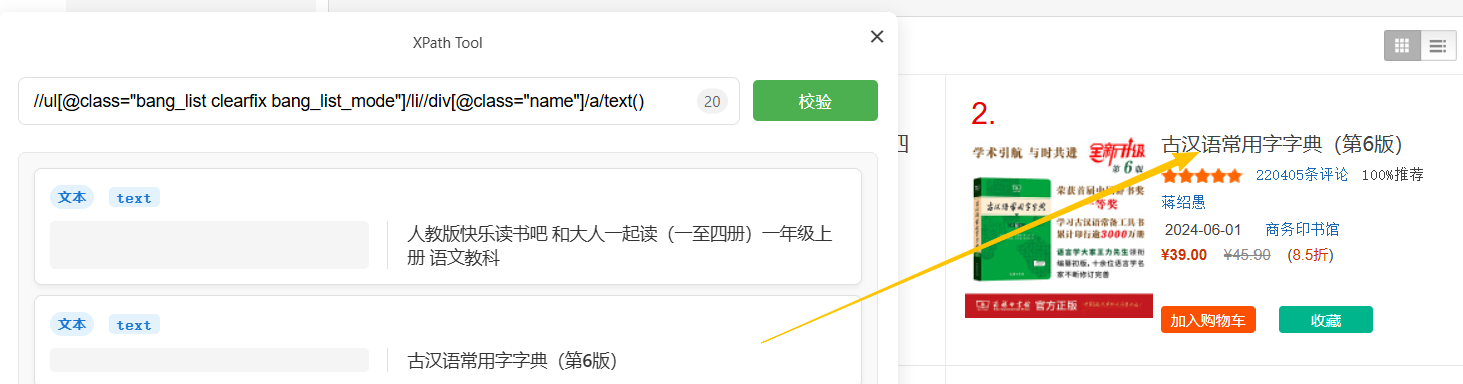
XPath Tool成功获取到了第一本和第二本书籍的名字,说明Xpath路径正确
这是获取每个图书的信息代码:
# 获取书籍信息
def get_info(self, html, num):
# 将网页的内容从HTML转换为XML
tree = etree.HTML(html)
book_list = tree.xpath('//ul[@class="bang_list clearfix bang_list_mode"]/li')
for book in book_list:
# 书名
name = book.xpath('.//div[@class="name"]/a/text()')
# 作者
author = book.xpath('.//div[@class="publisher_info"]/a/text()')
# 推荐程度
recommend = book.xpath('.//div[@class="star"]//span[@class="tuijian"]/text()')
# 评论总数
comment = book.xpath('.//div[@class="star"]/a/text()')
# 出版社
publisher = book.xpath('.//div[@class="publisher_info"][2]/a/text()')
# 出版日期
publish_date = book.xpath('.//div[@class="publisher_info"][2]/span/text()')
# 原价
price = book.xpath('.//div[@class="price"]//span[@class="price_r"]/text()')
# 折扣价
discount_price = book.xpath('.//div[@class="price"]//span[@class="price_n"]/text()')
# 折扣比例
discount_rate = book.xpath('.//div[@class="price"]//span[@class="price_s"]/text()')
# 将返回字段中的空内容添加字段
info = [
name[0].strip() if name else '未知书名',
author[0].strip() if author else '未知作者',
recommend[0].strip() if recommend else '0%推荐',
comment[0].strip() if comment else '0条评论',
publisher[0].strip() if publisher else '未知出版社',
publish_date[0].strip() if publish_date else '未知日期',
price[0].strip() if price else '?',
discount_price[0].strip() if discount_price else '¥0',
discount_rate[0].strip() if discount_rate else '0折'
]
self.ws.append(info)
print('第{}页的数据获取完毕'.format(num))
五、将数据保存到excel文件中
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.title = '9月份畅销书排行榜'
self.ws.append(['书名', '作者', '推荐程度', '评论总数', '出版社', '出版日期', '原价', '折扣价', '折扣比例'])
self.headers = {
'cookie': 'ddscreen=2; __permanent_id=20250424225904258407356457184867347; LOGIN_TIME=1751896512445; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; ddscreen=2; __rpm=...1760167541852%7C...1760167623048',
'referer': 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2025-8-1-1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0'
}
这里的cookie和ua需要自己根据自己的情况去设置
六、完整代码
# 导包
import os
import requests
import time
import random
from lxml import etree
from tqdm import tqdm
from openpyxl import Workbook
class Spider:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.title = '9月份畅销书排行榜'
self.ws.append(['书名', '作者', '推荐程度', '评论总数', '出版社', '出版日期', '原价', '折扣价', '折扣比例'])
self.headers = {
'cookie': 'ddscreen=2; __permanent_id=20250424225904258407356457184867347; LOGIN_TIME=1751896512445; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; ddscreen=2; __rpm=...1760167541852%7C...1760167623048',
'referer': 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2025-8-1-1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36 Edg/140.0.0.0'
}
# 获取网页的内容
def get_html(self, page):
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2025-9-1-{}'.format(page)
# 设置间隔时间,防止被反爬
time.sleep(random.uniform(1, 3))
try:
# 向网页发起请求
response = requests.get(url, headers=self.headers, timeout=10)
# 设置编码(根据网页的charset设置)
response.encoding = 'gb2312'
text = response.text
return text
except Exception as e:
print(f'错误:{e}')
time.sleep(random.uniform(2, 5))
return None
# 获取书籍信息
def get_info(self, html, num):
# 将网页的内容从HTML转换为XML
tree = etree.HTML(html)
book_list = tree.xpath('//ul[@class="bang_list clearfix bang_list_mode"]/li')
for book in book_list:
# 书名
name = book.xpath('.//div[@class="name"]/a/text()')
# 作者
author = book.xpath('.//div[@class="publisher_info"]/a/text()')
# 推荐程度
recommend = book.xpath('.//div[@class="star"]//span[@class="tuijian"]/text()')
# 评论总数
comment = book.xpath('.//div[@class="star"]/a/text()')
# 出版社
publisher = book.xpath('.//div[@class="publisher_info"][2]/a/text()')
# 出版日期
publish_date = book.xpath('.//div[@class="publisher_info"][2]/span/text()')
# 原价
price = book.xpath('.//div[@class="price"]//span[@class="price_r"]/text()')
# 折扣价
discount_price = book.xpath('.//div[@class="price"]//span[@class="price_n"]/text()')
# 折扣比例
discount_rate = book.xpath('.//div[@class="price"]//span[@class="price_s"]/text()')
# 将返回字段中的空内容添加字段
info = [
name[0].strip() if name else '未知书名',
author[0].strip() if author else '未知作者',
recommend[0].strip() if recommend else '0%推荐',
comment[0].strip() if comment else '0条评论',
publisher[0].strip() if publisher else '未知出版社',
publish_date[0].strip() if publish_date else '未知日期',
price[0].strip() if price else '?',
discount_price[0].strip() if discount_price else '¥0',
discount_rate[0].strip() if discount_rate else '0折'
]
self.ws.append(info)
print('第{}页的数据获取完毕'.format(num))
# 整合功能模块
def run(self):
for i in range(1, 27):
html = self.get_html(i)
# 判断返回内容是否成功
if html:
self.get_info(html, i)
else:
print('无法获取网页内容!!!')
self.wb.save('当当网9月份畅销书排行榜.xlsx')
if __name__ == '__main__':
# 实例化类
DDW = Spider()
# 运行程序
DDW.run()
print('所有数据已经获取完成!!!')
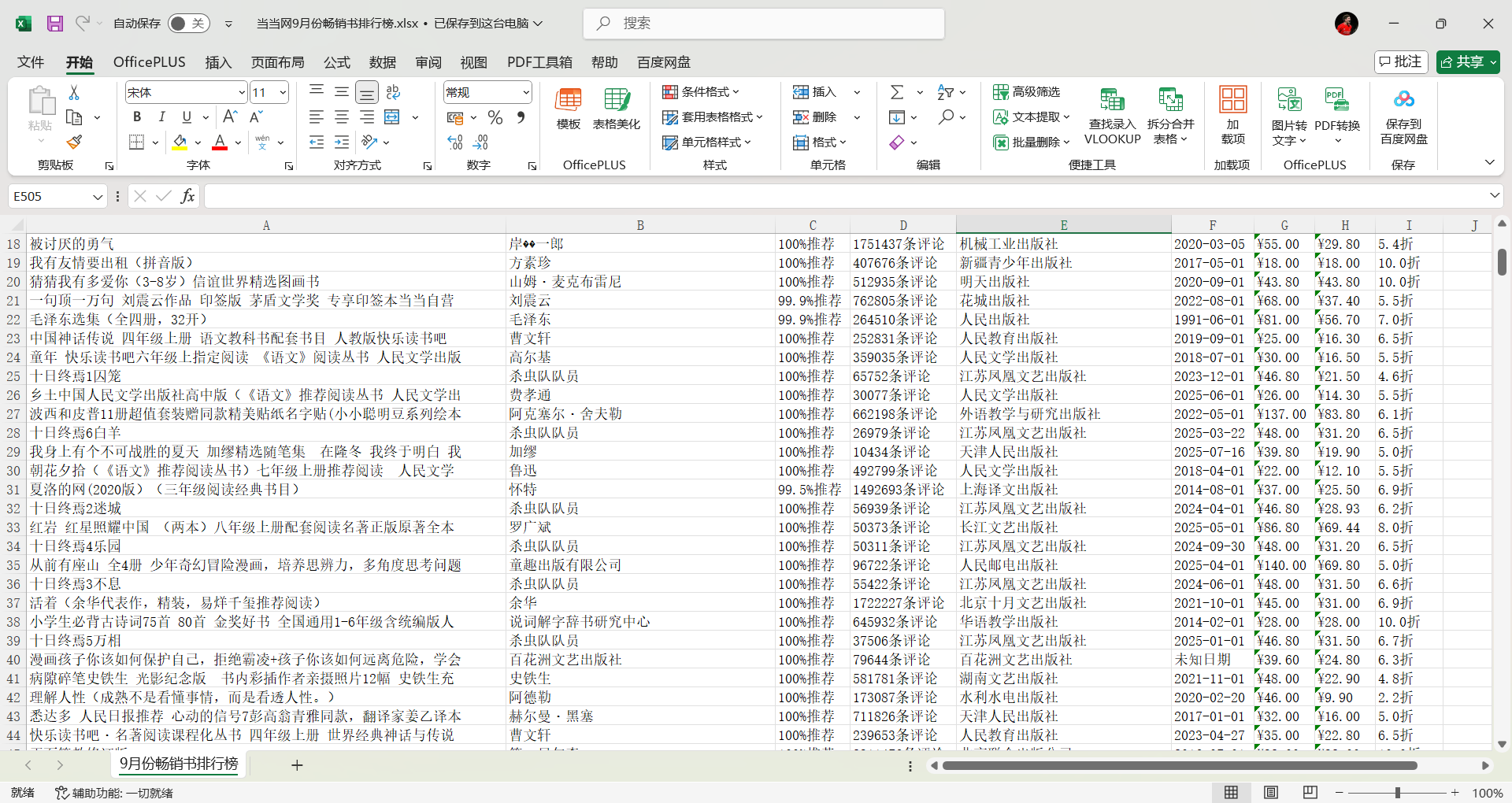
七、数据成果
八、结尾
以上就是关于当当网9月份图书畅销榜单的数据获取的代码,如果有不懂的,欢迎在评论区留言或者私信我

















 2776
2776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









