






一.opencv的一些基础用法
1.颜色分割

import cv2
import numpy as np
image=cv2.imread(r"C:\python study file\logo.png")#读取目标图像
image_hsv=cv2.cvtColor(image,cv2.COLOR_BGR2HSV)
low_red=np.array([0,50,50])
high_red=np.array([30,255,255])
low_blue=np.array([110,50,50])
high_blue=np.array([130,255,255])
low_green=np.array([50,50,50])
high_green=np.array([70,255,255])
low_black=np.array([0,0,0])
high_black=np.array([180,255,46])
red_mask=cv2.inRange(image_hsv,low_red,high_red)
blue_mask=cv2.inRange(image_hsv,low_blue,high_blue)
green_mask=cv2.inRange(image_hsv,low_green,high_green)
black_mask=cv2.inRange(image_hsv,low_black,high_black)
red=cv2.bitwise_and(image,image,mask=red_mask)
blue=cv2.bitwise_and(image,image,mask=blue_mask)
green=cv2.bitwise_and(image,image,mask=green_mask)
cv2.namedWindow("image",0)
cv2.namedWindow("red",0)
cv2.namedWindow("blue",0)
cv2.namedWindow("green",0)
cv2.namedWindow("black",0)
cv2.resizeWindow("image",300,200)
cv2.resizeWindow("red",300,200)
cv2.resizeWindow("blue",300,200)
cv2.resizeWindow("green",300,200)
cv2.resizeWindow("black",300,200)
cv2.imshow("image",image)
cv2.imshow("red",red)
cv2.imshow("blue",blue)
cv2.imshow("green",green)
cv2.imshow("black",black_mask)
cv2.waitKey()
cv2.destroyAllWindows()
通过该段代码我们把蓝色,绿色,红色,黑色分割了出来,不同的是由于黑色与背景颜色相同,这里输出的是它的掩模,以下是分割效果

在实际使用中,原始图像不可能像这个图一样边界清晰,因此我们需要使用滤波器对图像进行模糊操作,以减少图像中的细微差异。 关于不同滤波器的具体使用场景,我们后面再详细介绍。
2.图像覆盖(如何加上水印)
如何为我们可爱的狗狗加上“opencv”的水印呢

import cv2
import numpy as np
image=cv2.imread(r"C:\python study file\logo.png")#读取目标图像
image_hsv=cv2.cvtColor(image,cv2.COLOR_BGR2HSV)
dog=cv2.imread(r"C:\Users\13560\Desktop\1697631732804.jpg")
low_black=np.array([0,0,0])
high_black=np.array([180,255,46])
black_mask=cv2.inRange(image_hsv,low_black,high_black)
opencv=cv2.bitwise_not(black_mask)
opencv=cv2.cvtColor(opencv,cv2.COLOR_GRAY2BGR)
opencv=cv2.resize(opencv,(180,120))#将"opencv"字样缩小
#这里copy一个dog的副本,为什么不使用一个简单的赋值呢?
#因为在对数组进行操作时,实际上的对象是该数组的引用,因此一个简单的赋值并不能复制出一个多维数组的副本;
dogtemp=np.copy(dog)
dogtemp[:120,:180]=opencv #一个简单的覆盖,将opencv图像覆盖在狗狗的左上角
cv2.imshow("opencv",opencv)
cv2.imshow("dog+opencv",dogtemp)
cv2.imshow("dog",dog)
#获取最终有水印的图像
for i in range(0,120):
for j in range(0,180):
if(np.all(np.equal(dogtemp[i,j],np.array([255,255,255])))):#判断是否为[255,255,255]白色,注意这里的色彩空间是BGR
dogtemp[i,j]=dog[i,j]
cv2.imshow("dog_in_opencv",dogtemp)
cv2.waitKey(0)
cv2.destroyAllWindows()
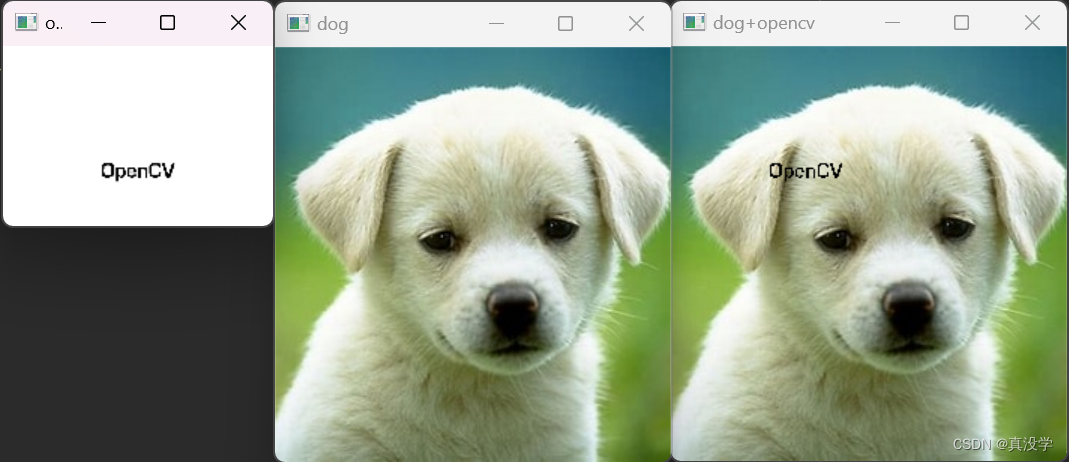
以下是得到最终图像的过程图像

(1)优化
可以看到上面采用的是嵌套循环,遍历检查每个像素点的BGR值是否为目标值,并替换为底层图像的背景,但这种方法很耗时,对此我们进行优化。
import cv2
dog=cv2.imread(r"C:\Users\13560\Desktop\1697631732804.jpg")
cv2.imshow("dog",dog)
Gray_opencv=cv2.imread(r"C:\Users\13560\Desktop\1697631732805.png",cv2.IMREAD_GRAYSCALE)#这里读入opencv的灰度图
cv2.imshow("Gray_opencv",Gray_opencv)
a,opencv_mask=cv2.threshold(Gray_opencv,0,1,cv2.THRESH_BINARY_INV)#这里采用两个二值化选取掩膜
a,dog_mask=cv2.threshold(Gray_opencv,0,1,cv2.THRESH_BINARY)
opencv=cv2.imread(r"C:\Users\13560\Desktop\1697631732805.png")
cv2.imshow("opencv",opencv)
for c in range(0,3):#循环三个通道,这里的图片都是BGR格式
dog[:120,:180,c]=(dog_mask* dog[:120, :180, c]+opencv_mask*opencv[:,:,c])
# 保存输出图像
cv2.imshow('dog+opencv', dog)
cv2.waitKey(0)
cv2.destroyAllWindows()这里通过二值化构建了两个只含0和1的掩膜,且opev_mask与dog_mask异或是得到一个全1矩阵的,这里不理解的可以运行代码看看这两个掩膜的具体格式。通过各自掩膜与图像各个通道值的乘积之和,我们最后可以得到如下各个图以及目标图像。
3.图像全景拼接
(1)特征检测与提取
-->关键点检测
最朴素并且可能是最幼稚的方法应该是使用Harris Corners之类的算法来提取关键点。然后,我们通过某种相似性度量来匹配相应关键点(如欧式距离)。有时候两个图像虽然有公共区域,但是同样还可能存在缩放、旋转、来自不同相机等因素的影响。我们知道,角点具有角点不变的特性,这样就避免了旋转图像对关键点的影响,但如果是缩放图像呢?
缩放图像可能导致我们检测到的角点变为一条线,于是我们需要的是旋转和缩放不变的特征。那就是opencv_contrib中的SURT,SIFT,以及ORB算法。
-->关键点和描述符
在最新版本中,SIFT已经移到opencv库中免费使用了,如果需要SURT,ORB及其它申请专利的算法,请下载opencv_contrib;
(由于一些版本兼容问题)
环境:python3.7+opencv 3.4.2.16+opencv_contrib 3.4.2.16
import numpy as np
import cv2
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
# 获取输入图片
(imageB, imageA) = images
# 检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA,'sift')
(kpsB, featuresB) = self.detectAndDescribe(imageB,'sift')
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self, name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
def detectAndDescribe(self,image,method=None):
#检测并提取特征
if method =='sift':
descriptor=cv2.xfeatures2d.SIFT_create()
elif method=='surf':
descriptor=cv2.xfeatures2d_SURF.create()
elif method=='brisk':
descriptor=cv2.BRISK_create()
elif method=='orb':
descriptor=cv2.ORB_create()
(kps,features)=descriptor.detectAndCompute(image,None)
kps = np.float32([kp.pt for kp in kps])
return (kps, features)
# 读取拼接图片
imageA = cv2.imread(r"C:\Users\13560\Desktop\1697705254977.jpg")
imageB = cv2.imread(r"C:\Users\13560\Desktop\1697705271024.jpg")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述代码中我们实现了一个Stitcher类进行两个图像的拼接,以下是图像的处理结果,以及特征点的对应。
 以下是特征点的提取与匹配:
以下是特征点的提取与匹配:

上面我们自己实现了图像拼接的类,但这个类及函数已经内置在了cv2.Stitcher这个类中,这样一来我们的代码实现就变得更加简单了,像这样:(也可以实现类似上图的效果)
import numpy as np
import cv2
##注意这里的opencv版本是4.x,老版本的函数名与新版本有差异
##而且Stitcher不再需要opencv_contrib了
imageA = cv2.imread(r"C:\Users\13560\Desktop\1697705254977.jpg")
imageB = cv2.imread(r"C:\Users\13560\Desktop\1697705271024.jpg")
stitcher=cv2.Stitcher.create(cv2.STITCHER_PANORAMA)
result,imageC=stitcher.stitch((imageA,imageB))
if result == cv2.STITCHER_OK:
cv2.imshow("re",imageC)
cv2.waitKey()
cv2.destroyAllWindows()
else:
print('Error during stitching')
当然没有手动效果好(狗头)















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









