






 本文详细介绍了树的概念、结构,包括树的拆分、表示方法,重点探讨了二叉树的特性、特殊形式如满二叉树和完全二叉树,以及堆的性质、插入和删除操作,以及如何利用堆解决TOP-K问题。
本文详细介绍了树的概念、结构,包括树的拆分、表示方法,重点探讨了二叉树的特性、特殊形式如满二叉树和完全二叉树,以及堆的性质、插入和删除操作,以及如何利用堆解决TOP-K问题。
一、树概念及结构
1.1树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限节点组成的一个具有层次的关系的集合。
注意:子树不能相交

- 节点的度:一个节点含有的子树个数称为该节点的度;A为6,D为1,F为3
- 叶节点:度为0的节点称为叶节点;B,C,H等为叶节点
- 分支节点:度不为0的节点;D,E等
- 父节点: 若一个节点含有子节点,则这个节点称为其子节点的父节点,A是B,C,D,E,F,G父节点
- 子节点:一个节点含有子树的根节点称为该节点的子节点;B,C,D,E,F,G是A的子节点
- 兄弟节点: 具有相同的父亲节点互称为兄弟节点;B,C就是兄弟节点
- 树的度:一棵树中,最大的节点的度称为树的度;此树的度为6
- 树的高度或深度:树中节点的最大层次;此树的高度为4
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;H,I互为兄弟节点
- 节点的祖先:从根到该节点所经分支上的所有节点;A是所有节点的祖先
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙;所有节点都是A的子孙
- 森林:由m(m>0)棵互不相交的树的集合称为森林
1.2树的拆分
树的拆分为根,n棵子树(n>=0)
然后继续在n棵子树里面继续拆分根,n棵子树,一直拆分到叶节点
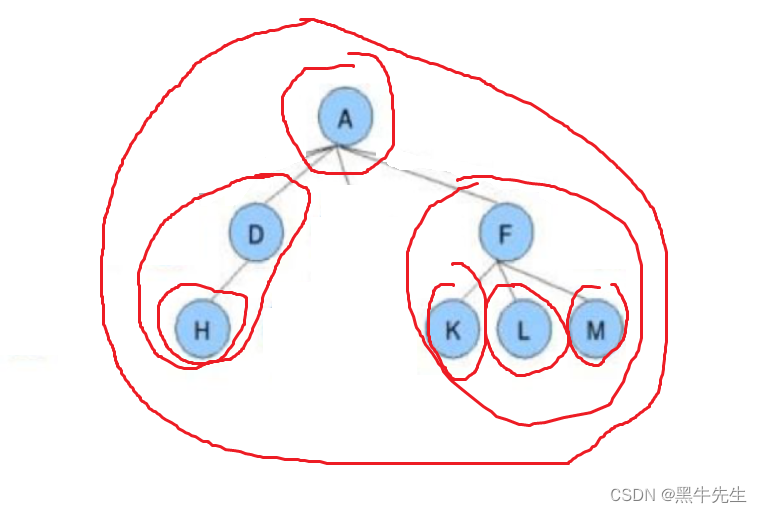
A为根D,F为子树
D为根,H为子树
F为根,K,L,M为子树
1.3树的表示
左孩子右兄弟表示法:
typedef struct TreeNode
{
int val;
struct TreeNode* leftChild;
struct TreeNode* nextBrother;
}TN;
下面的代码就能找到所有的兄弟节点
TN* cur = A->leftChild;
while(cur)
{
cur = cur->nextBrother;
}双亲表示法:

假如继续在A节点下创建一个节点为Q,Q为B,C的兄弟节点,此数组继续

若存储的是森林则
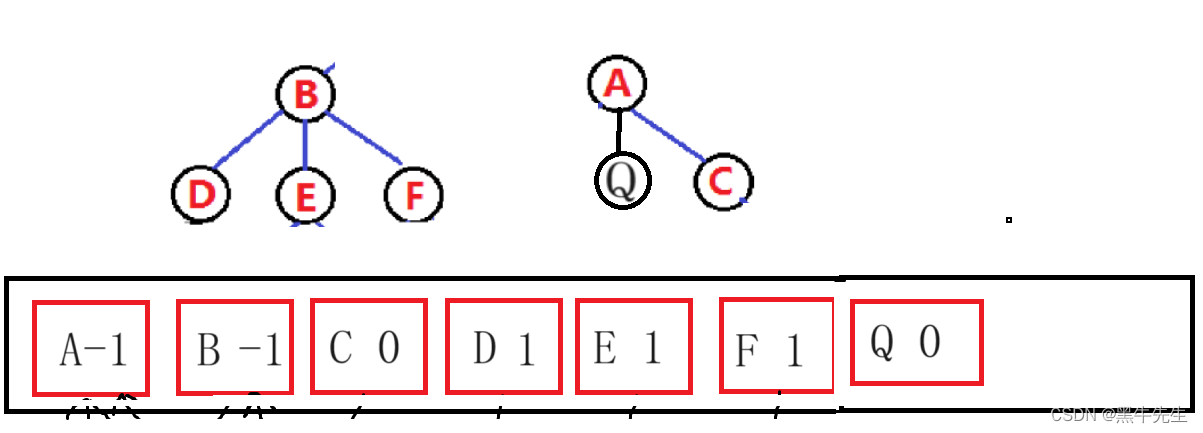
此方法:
物理结构:数组
逻辑结构:森林
二、二叉树
2.1二叉树
1.二叉树不存在度大于2的节点
2.二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树

二叉树单纯存储是没啥价值,不如顺序表/链表
但是搜索二叉树就很有意义
能1.存储数据2.搜索数据

左子树<根<右子树
2.2特殊的二叉树
满二叉树:一个二叉树,如果每一层的节点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且节点总是就是 - 1,则它就是满二叉树。
上图就是满二叉树
完全二叉树:对于深度为K的,有n个节点的二叉树,当且仅当每个节点都与深度为K的满二叉树中编号从1至n的节点---对应时称之为完全二叉树。(n-1层全满,最后一层不要求满,要求从左到右连续)
下图是满二叉树

满二叉树和完全二叉树的数组存储
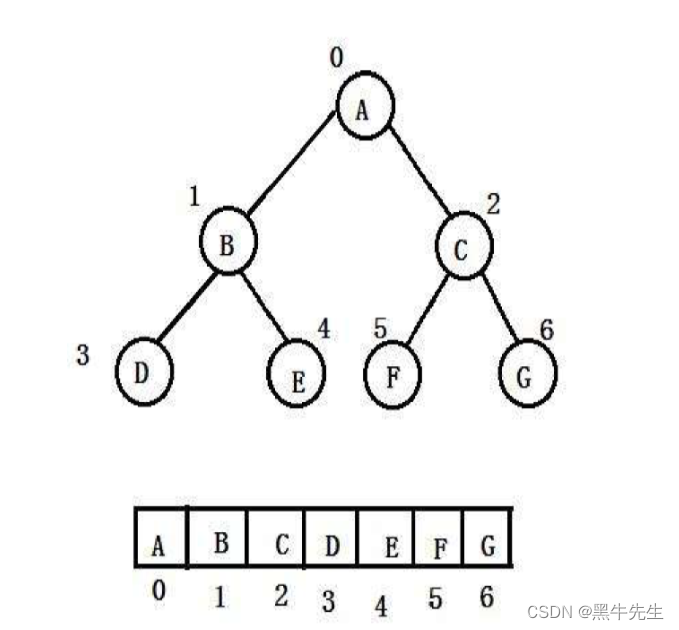
物理结构:数组
逻辑结构:二叉树
父子存储的下标位置规律:
leftchild = parent*2 + 1
rightchild = parent*2 + 2
parent = (child-1)/2如果B想知道左孩子的下标 1*2+1=3
如果G想知道父亲的下标则 6-1/2=2
若进行非完全二叉树的存储会面临空间浪费,不适合
三、堆
堆的性质:
1.堆总是一个完全二叉树
2.堆中某个节点的值总是不大于(大堆)或不小于(小堆)其父节点的值
3.1二叉树节点与高度的关系
3.1.1满二叉树

3.1.2完全二叉树

3.1堆的插入
插入数据后,调整成小堆,可能会影响祖先
使用的是向上调整法
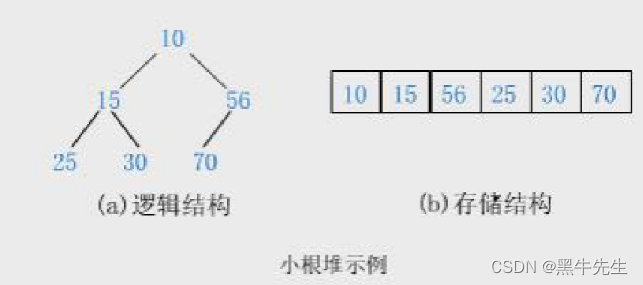
假如要插入一个数据60

60跟他的父节点56比60大,则不用交换
如果插入一个数据为5
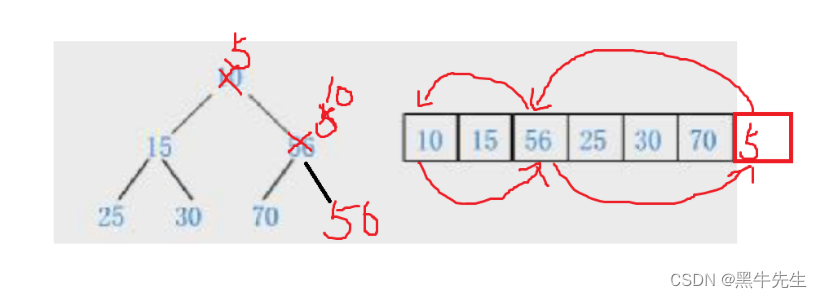
5和他的父节点56比5小,则交换位置,然后5和他的父亲节点10比5小,则继续交换
根据上面的满二叉树和完全二叉树的数组存储就能通过下标的方式进行交换数据
代码展示
void HPPush(HP* php, HPDataType x)
{
assert(php);
if (php->capacity == php->size)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * newcapacity);
if (tmp == NULL)
{
perror("realloc fail:");
}
php->a = tmp;
php->capacity = newcapacity;
}
php->a[php->size] = x;
php->size++;
//向上调整算法
AdjustUp(php->a, php->size - 1);
}下面的代码唯一难理解的点就在于 循环的判断条件
什么时候终止循环
1.父节点小于子节点,break
2.此节点是所有节点中最小的节点时,下标变为0终止循环,跳出while
void swap(HPDataType* a,HPDataType* b)
{
HPDataType tmp = 0;
tmp = *a;
*a = *b;
*b = tmp;
}
void AdjustUp(HPDataType* a,int child)
{
int parent = (child - 1) / 2;
while (child>0)
{
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else {
break;
}
}
}效果展示


3.2堆的删除
为什么不能直接删除堆顶数据
1.堆结构破坏,父子变兄弟,兄弟变父子(需要重新建堆)
2.挪动覆盖时间复杂度是O(N)啥意思?

如果10删除了15就覆盖10的位置,相反56覆盖10的位置以此类推
这里采用的是
首尾数据交换,删除尾部数据
使用向下调整法
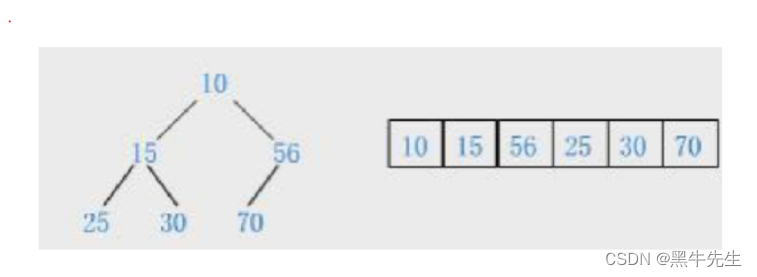
首先10与70进行交换,然后删除尾部

然后使用假设法,选出左右孩子最小的孩子与70进行交换,以此类推,一直交换到子节点小于父节点使结束

代码展示
// 删除堆顶的数据
void HPPop(HP* php)
{
assert(php);
assert(php->size > 0);
//首尾交换
swap(&php->a[0], &php->a[php->size - 1]);
//删除尾巴
php->size--;
AdjustDown(php->a, php->size, 0);
}void AdjustDown(HPDataType* a ,int n,int parent )
{
int child = parent * 2 + 1;
while (child<n)
{
//假设法,先假设左孩子小,右孩子大,反之则相反
if (child+1 < n && a[child] > a[child + 1])
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
parent = child;
//继续左孩子最小
child = parent * 2 + 1;
}
else {
break;
}
}
}3.3TOP-K问题
假如一组数组的堆插入我们应该如何选择---结合二叉树节点与高度的关系来看
若使用向上调整法

则我们的时间复杂度为O(N*logN)
void HPInitArrary(HP* php, HPDataType* a, int n)
{
assert(php);
php->a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (php->a == NULL)
{
perror("malloc fail");
return;
}
memcpy(php->a, a, sizeof(HPDataType) * n);
php->capacity = php->size = n;
//建堆
for (int i = 1; i < php->size; i++)
{
AdjustUp(php->a, i);
}
}若使用 向下调整

时间复杂度就是O(N)
for (int i = (php->size - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, php->size, i);
}如果一个数组要进行升序
如何在不建堆的情况下,继续堆排序
那是建大堆?还是建小堆?
3.3.1小堆


如果建小堆,进行升序,使用向下排序法时间复杂度是O(N) 当我们取走第一个最小的数时 是不是堆的结构又乱了
乱了是不是又要重新进行堆排序,当进行完升序后时间复杂是O(N^2)跟冒泡排序的复杂度一样
3.3.2大堆
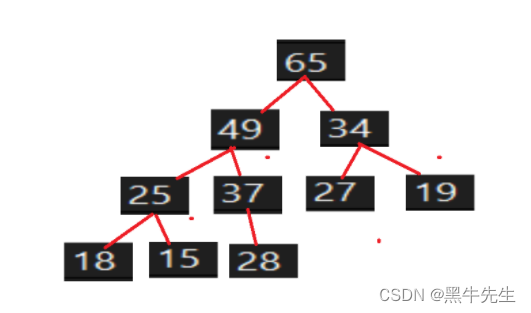
大堆的时间复杂度是O(N*logN)
方法:
1.使用首尾交换
2.最后一个值不看做堆里面,向下调整选出次大的数
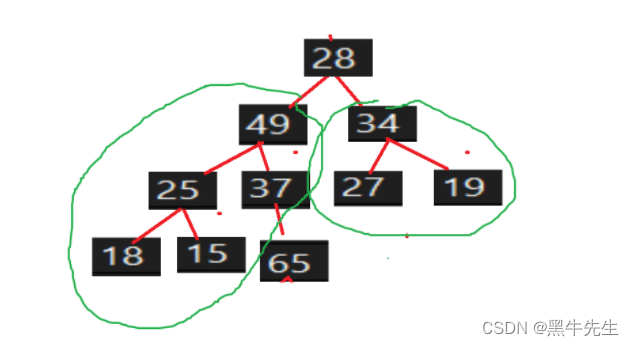
void HPSort(int* array, int n)
{
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(array, n, i);
}
int end = n - 1;
//交换
while (end > 0)
{
swap(&array[0], &array[end]);
AdjustDown(array, end, 0);
end--;
}
}
int main()
{
int array[] = { 27,15,19,18,28,34,65,49,25,37,100,200 };
HPSort(array, sizeof(array) / sizeof(int));
return 0;
}建堆的时间复杂度是O(N)
取出每个数的时间复杂度是O(logN)不懂看3.1
也就是说进行排序的时间复杂度是O(N*logN)
3.3.3TOP-K应用
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
1. 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
假如从10000个数据中选5
//先造个数据
void CreateNDate()
{
// 造数据
int n = 10000;
srand(time(0));
const char* file = "data2.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 100000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
//打印
void PrintTopK(int k)
{
const char* file = "data2.txt";
FILE* fout = fopen(file, "r");
int* mintop = (int*)malloc(sizeof(int) * k);
if (mintop == NULL)
{
perror("malloc error");
return;
}
//从文件读取数据
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &mintop[i]);
}
//建堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(mintop, k, i);
}
//遍历数据
int s = 0;
while (fscanf(fout, "%d", &s)!= EOF)
{
//如果大就替换
if (s > mintop[0])
{
swap(&s, &mintop[0]);
AdjustDown(mintop, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", mintop[i]);
}
}
int main()
{
//CreateNDate();
int k = 5;
PrintTopK( k);
return 0;
}
个最大的数据















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









