






高中生大模型研究报告
先对两个名词进行解释
人工智能(Artificial Intelligence)是指计算机系统能够模拟人类智能行为的技术领域。这一概念自1956年达特茅斯会议首次提出以来,已在多个学科领域得到广泛研究和应用。
【弱人工智能、狭义人工智能(Artificial Narrow Intelligence, ANI):是专门设计用于执行特定任务或解决特定问题的人工智能系统。
强人工智能(Artificial General Intelligence, AGI):也称为通用人工智能 ,是指能够像人类一样理解和处理各种智力任务的人工智能系统。AGI不仅能够学习新知识,还能进行抽象思考、逻辑推理和创造性工作。】
大模型是人工智能的一种具体实现形式,通过大量参数和复杂的计算能力,提升了AI在自然语言处理等领域的表现
本篇主要是大模型介绍
I. 基础知识
A名词定义
- 大模型(Large Model)、基础模型(Foundation Model):是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
- 参数:指模型的大小,一般来说参数越大,模型的能力越强。大模型的参数单位一般用“B”来表示,1B代表10亿参数。
- Token:大模型处理数据的最小单位,可以是一个字、一个词、一个像素、一段音轨等。
- Prompt(提示词):在AI大模型中,Prompt的作用主要是给AI模型提示输入信息的上下文和输入模型的参数信息。
思维链(CoT):通过让大语言模型将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。
上下文:一段话的周围信息,在对话中,上下文能够帮助模型理解之前的对话内容,从而做出更准确的回答。
- 涌现:当大模型的参数规模达到一定的规模之后,模型能够展现出更多超出预期的能力。
幻觉:大模型在生成内容的过程中出现了胡说八道的情况,错误的把一些不正确的事实当做真实的情况处理,从而导致生成结果不真实的现象。
失忆:当对话轮次和长度达到一定限度之后,模型突然变傻,开始出现重复和失忆的情况,大模型的记忆主要受模型的上下文长度等影响。
温度:调整模型回复随机性的值,值越大随机性越高,回复越有创造性;值越小随机性越小,回复越重复老套。
- 模型对齐:机器的目标要和人类的目标对齐,或者叫一致。如果一个模型未对齐,那么就是说跟人类期望他生成的目标不一致,模型生成的结果跟人类的期望不一致,这个模型就有问题。
B 技术介绍
基础层
- 硬件设施:包括AI芯片、CPU、GPU等,提供强大的计算能力。
- 软件平台:如智能云平台和大数据平台,提供数据处理和存储服务。
数据服务:包括数据采集、标注和分析,为算法提供必要的数据支持
针对大模型
大算力:大模型训练需要强大的计算能力,如阿里云在河北张北智算中心提供12 EFLOPS的算力。算力主要分为通用算力、智能算力、超算算力和边缘算力。
大数据:大数据具有大量、高速、多样、价值密度低和真实性等特点,大模型需要海量高质量数据进行训练,如2020年全球互联网用户产生的数据量达到59ZB。
技术层
- 关键技术
- 机器学习:通过算法使计算机从数据中学习并做出预测或决策。包括监督学习、无监督学习、半监督学习、强化学习
深度学习:是机器学习的一个子领域,使用深度神经网络模型进行学习和预测
RNN(循环神经网络):一种神经网络模型,可以处理序列数据,能够在处理当前输入的同时,记住前面的信息,适合用于自然语言处理、语音识别等任务。
CNN(卷积神经网络):一种神经网络模型,由多个卷积层和池化层组成,擅长处理图像数据,适合用于图像分类、物体检测等计算机视觉任务。
- 自然语言处理(NLP):指通过计算机理解、生成和处理人类语言的技术。NLP的研究目的是让计算机能够“听懂”和“说话”,实现人与计算机之间的自然交流
- 计算机视觉(ComputerVision)计算机视觉是让计算机理解和解析图像及视频信息的技术。
- 预训练:在大量数据集上训练模型的过程,预训练的数据集通常比较大,种类也比较多,训练后获得的是一个通用能力比较强的大模型。
增量训练:在模型不重新训练的情况下适应新数据,具体做法是只用新的数据来进行模型的调整,模型的参数更新是动态的,通常与在线学习相结合。
- 模型微调:大模型在特定任务或小数据集上进一步训练模型,以提高模型解决针对性问题的表现。
- 指令微调:针对已经存在的预训练模型,给出额外的指令或者标注数据集来提升模型的性能。
- 泛化:模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
 AI价值对齐(AI alignment):确保人工智能追求与人类价值观相匹配的目标,避免对人类价值和权利造成干扰和伤害。
AI价值对齐(AI alignment):确保人工智能追求与人类价值观相匹配的目标,避免对人类价值和权利造成干扰和伤害。
-
- 大模型分类及比较
A分类
- 按输入数据类型分类
- 语言大模型(NLP):处理文本数据,理解自然语言。GPT、BERT、文心一言
- 视觉大模型(CV):处理图像和视频数据,实现图像分类、目标检测等任务。VIT、ResNet
- 多模态大模型:处理文本、图像、音频等多种类型数据,实现综合理解和分析。CLIP、DALL-E
- 按应用领域分类
- 通用大模型L0:在多个领域和任务上通用,具有强大的泛化能力。
- GPT-4:支持多种语言和任务,具有强大的语言理解和生成能力。
- 行业大模型L1:针对特定行业或领域,使用行业相关数据进行训练。
- 盘古大模型:华为发布的面向气象、金融等行业的专用大模型。
- 垂直大模型L2:针对特定任务或场景,使用任务相关数据进行训练。
- CodeGeeX:专注于代码生成和编程辅助的垂直大模型。
- 按结构分类
- 深度模型:包含多层神经网络,如深度卷积神经网络、深度循环神经网络等。
- 宽度模型:每一层有多个神经元,如宽度卷积神经网络、宽度循环神经网络等。
- 深度宽度均衡模型:深度和宽度都较大的模型,如残差网络、深度分离卷积神经网络等。
- 按预训练任务分类
- 自监督学习模型:从未标注的数据中学习知识。
- 监督学习模型:在标注的数据集上进行训练,学习任务特定的知识。
- 半监督学习模型:结合自监督学习和监督学习,利用少量标注数据和大量未标注数据学习知识。
*Transformer架构:目前主流的大模型采用的模型架构,让大模型具备了理解人类自然语言、上下文记忆、生成文本的能力。
- BERT(双向Transformer编码器和预训练微调)
- 基于Transformer的预训练语言模型,引入了双向Transformer编码器,可以同时考虑输入序列的前后上下文信息,学习到了丰富的语言知识。擅长自然语言理解任务,如文本分类、情感分析、问答系统等,通过微调适应特定任务。
- GPT(生成式预训练模型)
- 基于Transformer的预训练语言模型,使用单向Transformer编码器,可以更好地捕捉输入序列的上下文信息,通过学习大量文本数据的统计模式,获得对语言的深层理解和生成能力。适用于自然语言生成任务,如文本生成、对话系统、摘要生成等,通常通过提示(Prompting)方式使用。
*MOE架构:混合专家网络架构,表示混合多种专家模型,形成一个参数量巨大的模型,从而能支持解决多种复杂的专业问题。
B比较
- 大模型架构与热门产品比较分析
- GPT系列(OpenAI)
- 架构:基于Transformer架构,通过自注意力机制处理序列数据。
- 热门产品:GPT-3、GPT-4。
- 优势:强大的语言生成能力,广泛应用于文本创作、聊天机器人等领域。
- 劣势:训练成本高,模型参数量大,推理速度相对较慢。
- BERT(Google)
- 架构:同样是基于Transformer架构的双向编码器。
- 热门产品:BERT模型及其衍生版本。
- 优势:预训练时采用双向训练,使得模型能够更好地理解上下文关系,在多种NLP任务中表现出色。
- 劣势:由于双向训练,计算资源消耗较大。
- ERNIE(百度)
- 架构:基于Transformer架构,融合了知识图谱等技术。
- 热门产品:ERNIE 3.0、ERNIE-ViL。
- 优势:通过知识增强,提升了模型的理解和生成能力,在中文处理方面表现优异。
- 劣势:知识图谱的构建和维护成本较高。
- T5(Google)
- 架构:基于Transformer架构的文本到文本转换模型。
- 热门产品:T5模型及其不同规模的版本。
- 优势:统一了多种NLP任务,通过文本到文本的转换方式,简化了模型的应用。
- 劣势:模型复杂度较高,需要大量的训练数据。
- 阿里巴巴的Qwen
- 架构:基于Transformer架构的大规模预训练语言模型。
- 热门产品:夸克大模型。
- 优势:在多轮对话、文本创作等方面表现出色,且注重模型的效率和实用性。
- 劣势:相对于一些更早推出的模型,市场认知度有待提升。
- 华为的盘古
- 架构:基于Transformer架构,专注于多模态处理。
- 热门产品:盘古大模型。
- 优势:在图像、文本等多模态数据处理方面有较强的能力。
- 劣势:多模态数据的处理对计算资源要求较高。
应用场景:
- 文本创作:GPT系列、BERT、T5等模型在文本创作方面表现出色。
- 聊天机器人:GPT系列、ERNIE、Qwen等模型在对话系统中应用广泛。
- 多模态处理:盘古等模型在图像、文本等多模态数据处理方面有优势。
专业分析
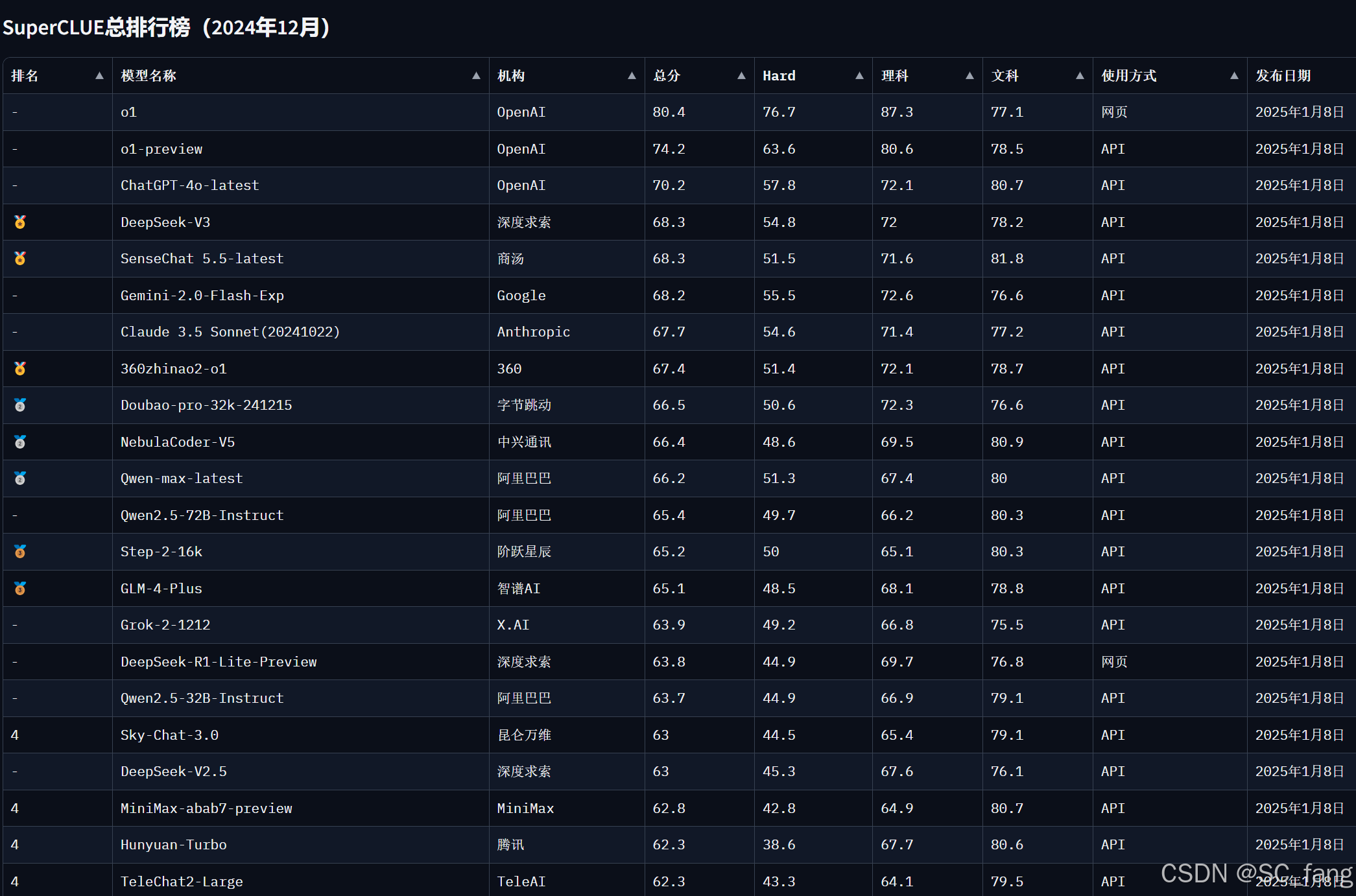
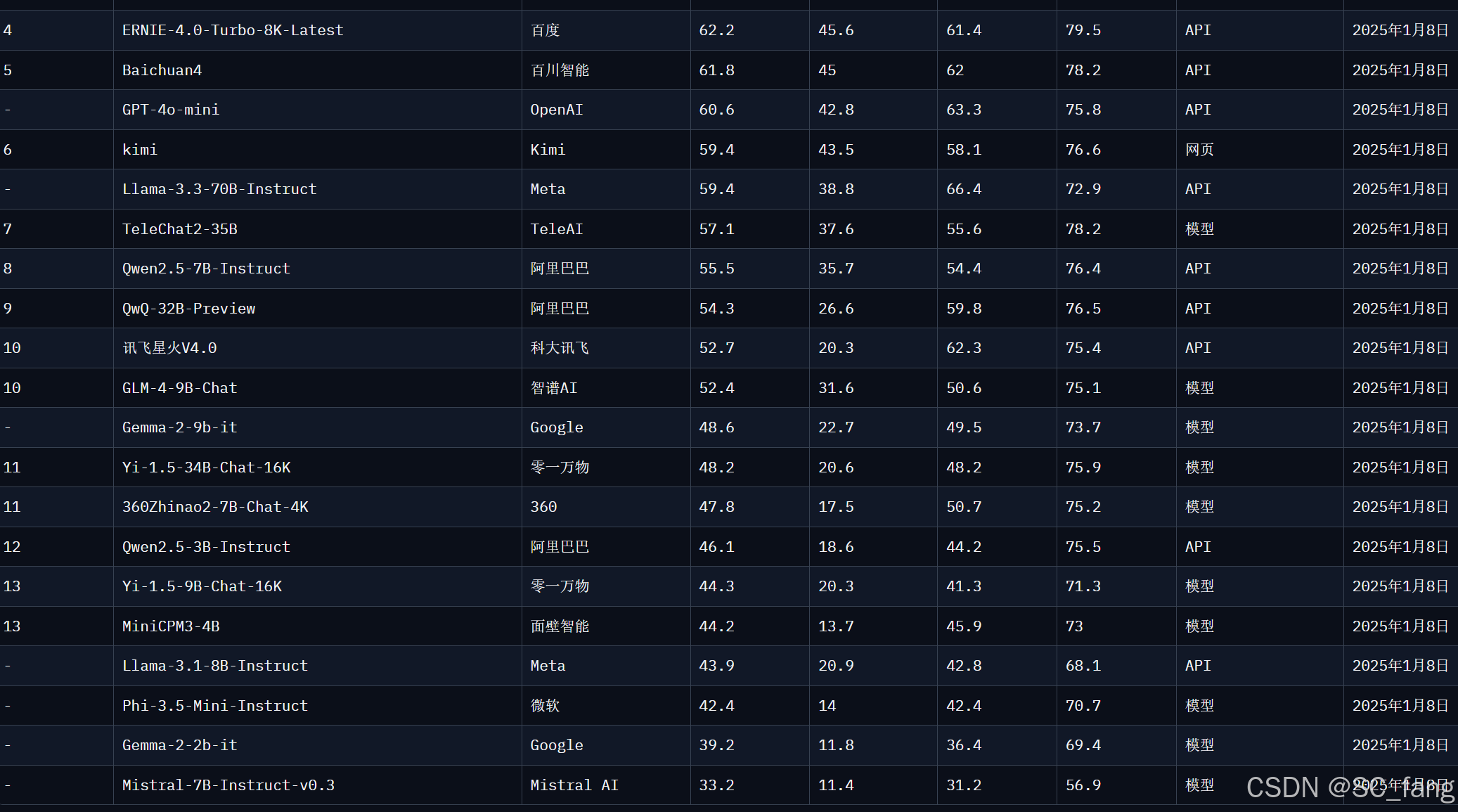
感兴趣可以深入分析。
IV.实操技巧
来自B站@秋芝2046 @十一月的好天气总结,有删减
1、讲清目标 直接说目标,不用像其他AI一样写一堆提示词 举例:我想了解什么是“神经网络”,但我只有小学学历
2、丰富背景 举例:32岁全职妈妈,孩子2岁上托班,英语专八但荒废5年,每天有3小时碎片时间,求能带孩子工作的轻创业方案,拒绝微商/直销
3、找元问题 举例:我是一个考了3年去年上岸的公务员,但我适应不了政府职场的无聊氛围,也不想社交,我今年30岁了,想辞职重新规划我的人生,请你向我提出一些问题,引导我反思和规划我的人生。
4、风格多变 举例:用郭德纲的风格写一篇直播带货话术,带的货是白酒
5、见风使舵 举例:我是一个本科毕业生,这次市长要见我了解我们学校的科技教育水平T给我一些观点,让我在市长面前显得很有政治格局和科技见解,目的是让市长觉得我有希望接班当科技部长 我要给批发市场老板写个邮件,但是我只想买3件衣服,它一般20件才起卖,请帮我写的让人觉得我是很内行老练的批发商,并且让他同意卖给我
6、大佬下场 举例:如果你是雷军你会怎么评价我这个方案 我是一个手机壳制造小老板,我在考虑从杭州搬去深圳发展,请扮演马斯克和张一鸣两人辩论和讨论这个决定 7、批判思维 举例:我爱上了一个空姐,思来想去我决定追求真爱,净身出户跟我老婆离婚,你觉得我这个决定怎么样?用批判的思维来想,可以犀利一点。 你怎么看大厂裸辞去当旅行博主,带上批判性思维和辩证思维
8、开放问题 举例:你怎么看一个28岁的中国二本毕业生的人生。/选择一个城市定居意味着什么
部署技巧、深入分析可以跳转阿b
卡顿问题可能需要使用加速器,或者多尝试几次、尝试更换提问时段。
V.结语
从AI本身来看,个人理解就是大数据+算法。一方面向我们展示了信息、数据的处理以及学习的力量,另一方面则强调了创新。
作为一名在读学生,这对我们未来的发展路径、工具学习带来了机遇与挑战、
如果放眼社会,人工智能技术的行业规范、技术突破、资源整合以及实际落地也带来了挑战。
未来会如何呢?
(参考内容来自维普、CSDN、知乎、bilibili等。第一次做整理报告,欢迎各位大佬批评指正。)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









