






首先打开随机打开一条微博,并进入进入F12。
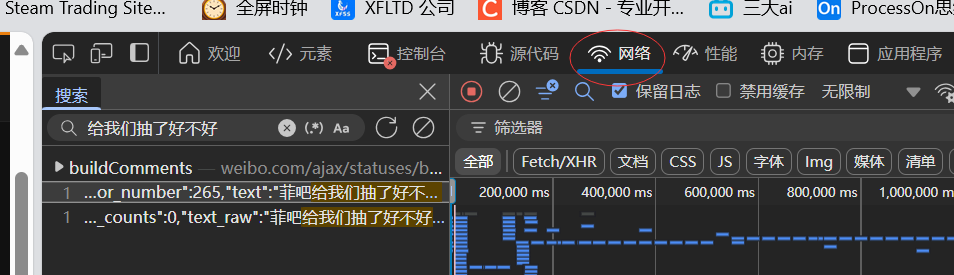
点击网络然后刷新
选中第一天评论然后直接搜索
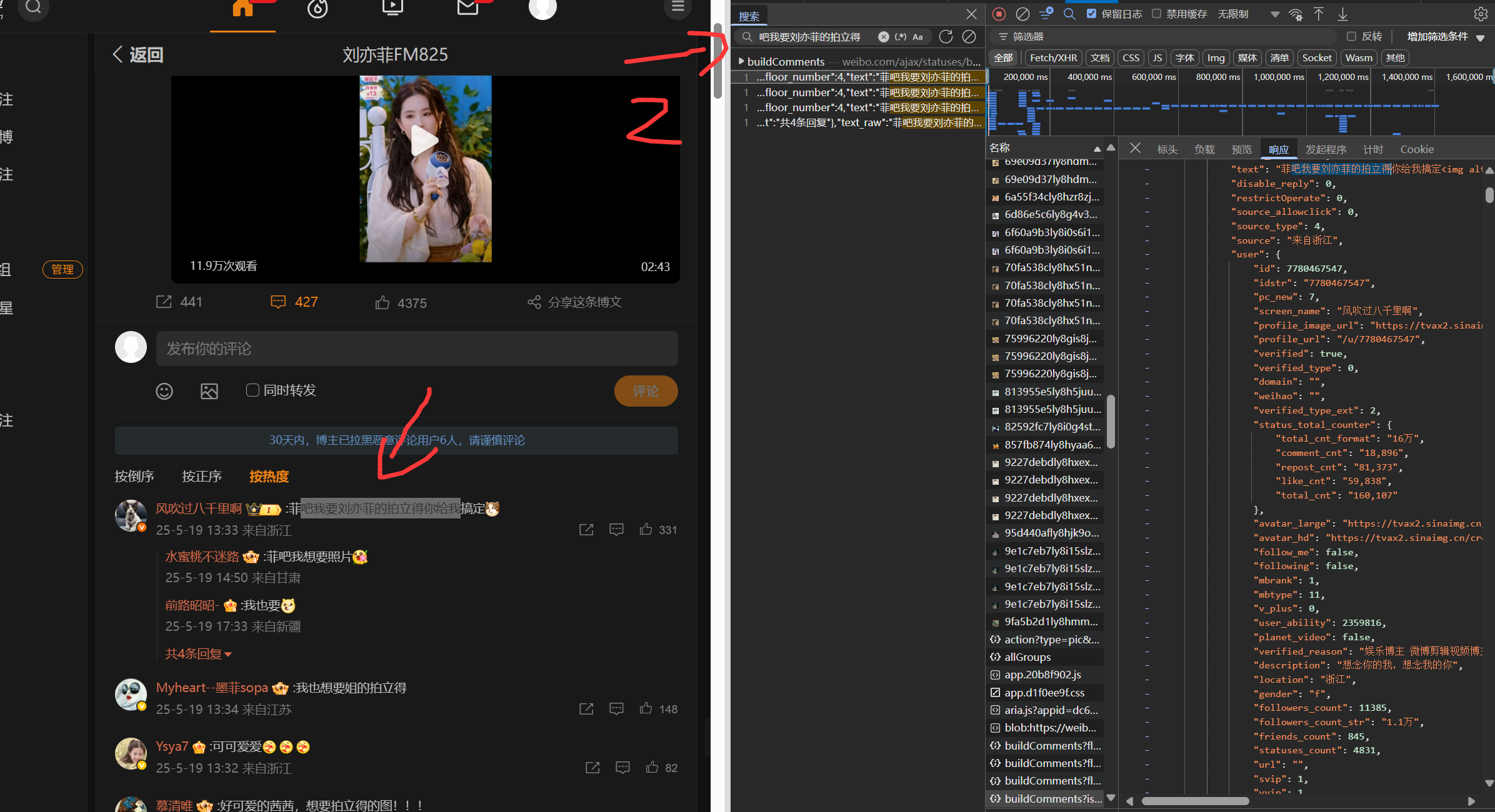
点击预览,发现是json数据这就好办了。
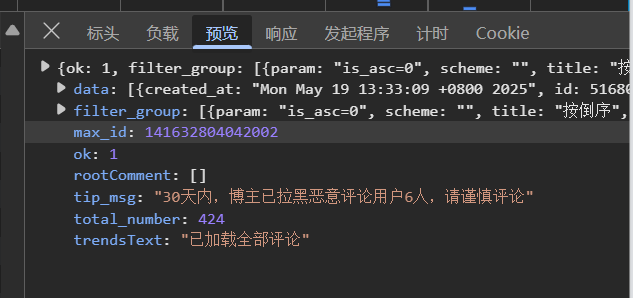
查看负载
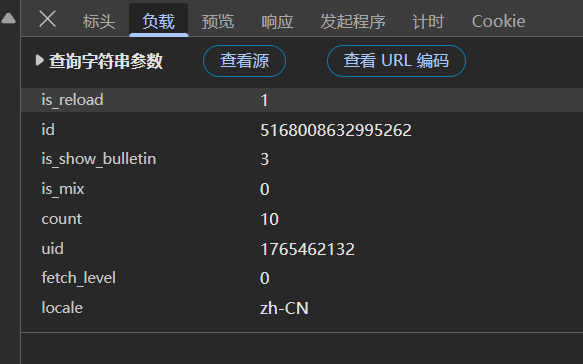

查看表头
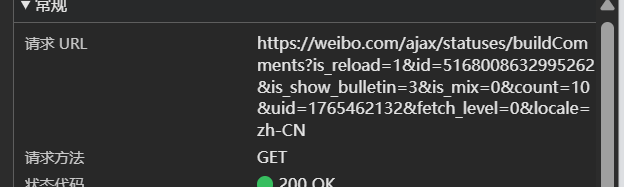
get请求就好弄了
直接写代码,还有headers带上。
import requests
import time
#等待1s
time.sleep(1)
#请求头
headers = {
'cookie':'SCF=AkfFEbIIt9K25XjQVB-Ei7i2ad64n3QkrNoUaXM8UCGulbx9ia1b8LVfqXCGJSIVzH0NL06hgrvq5QhwsgRbzTE.; SINAGLOBAL=9601544246784.834.1742785949889; PC_TOKEN=7614d44475; ALF=1750260544; SUB=_2A25FLz4QDeRhGeFH7FIT8irEwjWIHXVmRT_YrDV8PUJbkNANLRPmkW1NeoJe5zo79MOZImcpVgTX-vaO0u5UOTXg; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW3.SY6Z_g83CRezlZxi3sr5JpX5KMhUgL.FoM4S05EeoBR1K.2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KM7eozX1h.4; XSRF-TOKEN=6rGftJ_koCdwS_tnV7QSWNp4; WBStorage=036f61cc|undefined; _s_tentry=weibo.com; Apache=416113508804.22003.1747668586057; ULV=1747668586180:10:2:1:416113508804.22003.1747668586057:1746188519803; WBPSESS=ruAF00To3bxFjRRKO9IcqbZfbcYBPpyNn_nn-fza1HUoGjFXih-NcK6izx2NA2K5tPB9cii7EmJ346GBSyi2JVeB5FmOdZSiJuo4WSmLGAWu0Wock-Eh7VLXy2mK0w4Ixk1E6VhUBtbo-rLvskFU5g==',
'referer':'https://weibo.com/1765462132/PsxdlczcG',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
url = 'https://weibo.com/ajax/statuses/buildComments?'
params = {
'is_reload':'1',
'id':'5168008632995262',
'is_show_bulletin':'3',
'is_mix':'0',
# 'max_id':'139296342474919',
'count':'20',
'uid':'1765462132',
'fetch_level':'0',
'locale':'zh-CN'
}
response = requests.get(url,headers=headers,params=params)
print(response.status_code)然后查看第一条评论所在得位置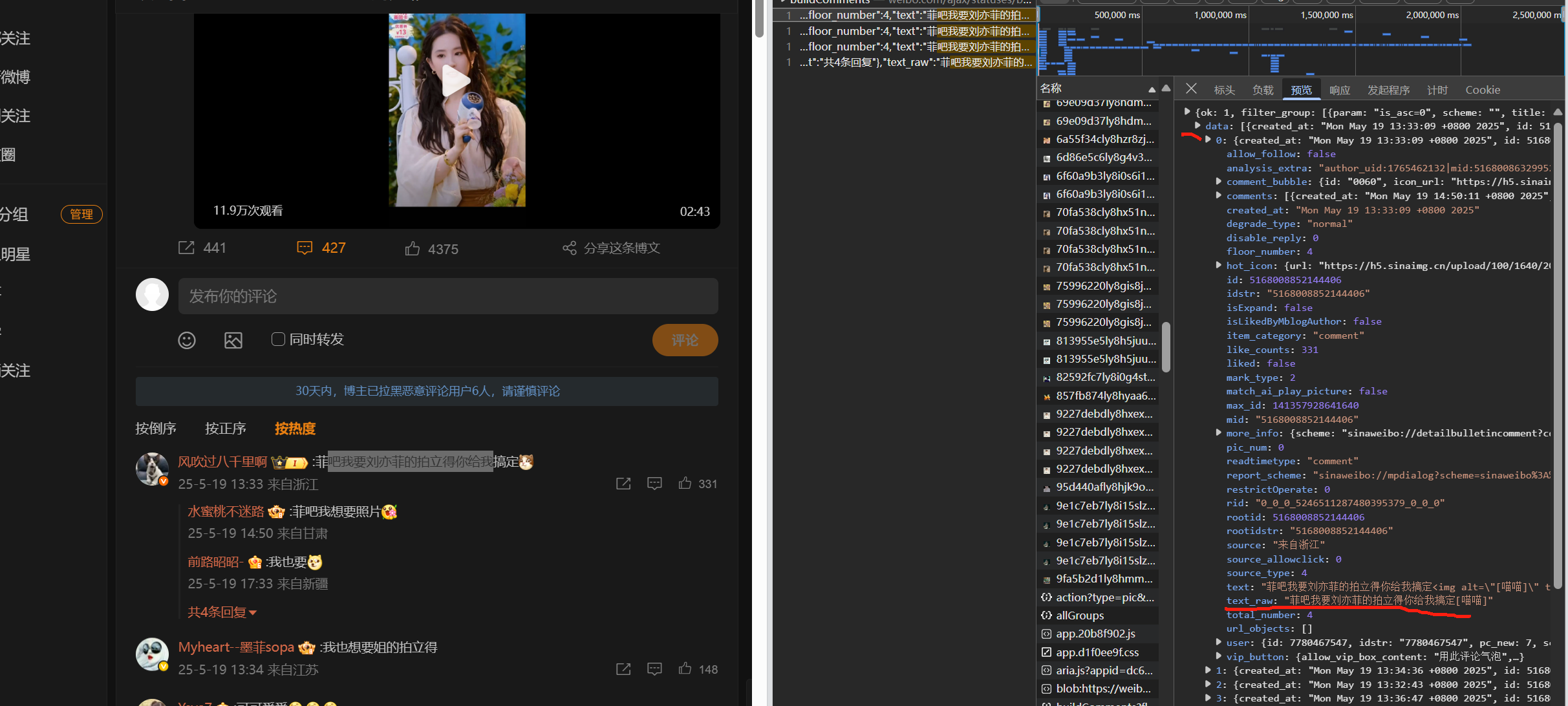 发现在data里面得第一条数据里面得‘text_raw’
发现在data里面得第一条数据里面得‘text_raw’
json = response.json()
data = json['data']
for i in data:
#评论内容
text_raw = i['text_raw']
print(text_raw)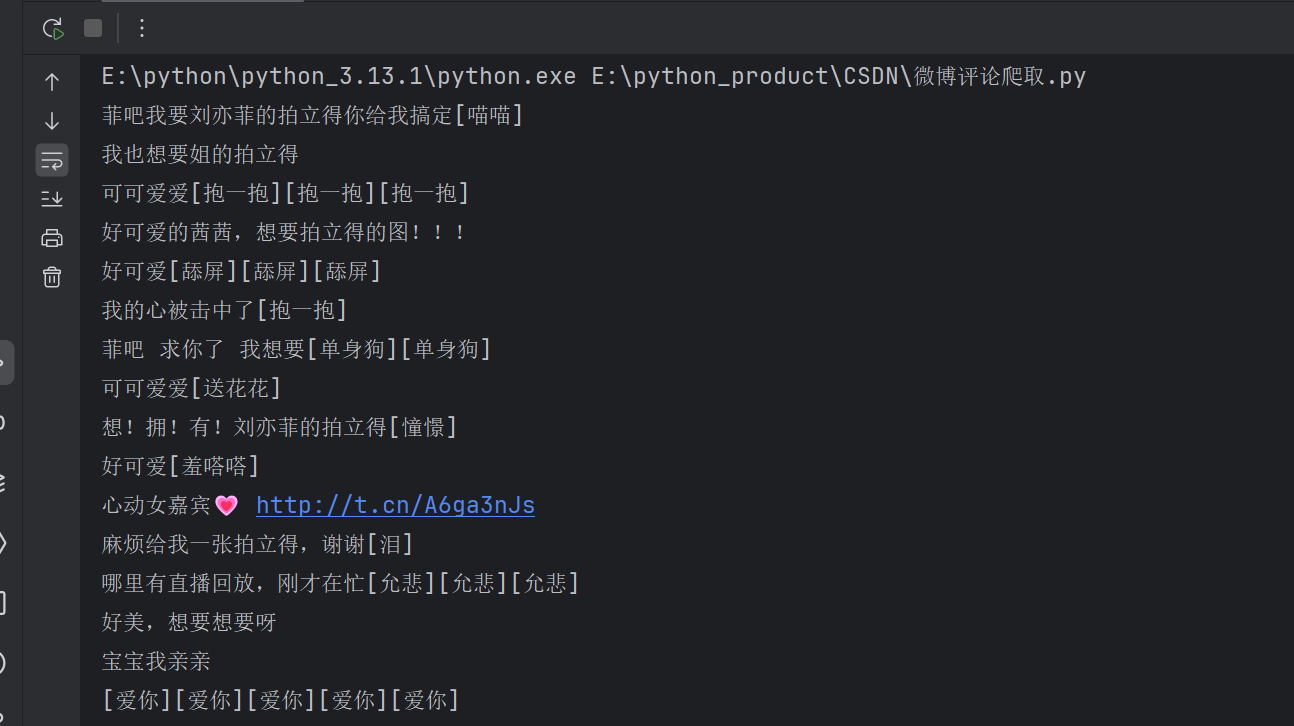
然后把获取用户
id','昵称','性别','地点','评论时间','评论内容
json = response.json()
data = json['data']
print('id','昵称','性别','地点','评论时间','评论内容')
for i in data:
#id
id = i['user']['id']
# 昵称
screen_name = i['user']['screen_name']
# 性别
gender = i['user']['gender']
if gender == 'f':
gender = '女'
elif gender == 'm':
gender = '男'
else:
gender = '保密'
# 坐标
location = i['user']['location']
#评论时间
created_at = i['created_at']
#评论内容
text_raw = i['text_raw']
print(id,screen_name,gender,location,created_at,text_raw)运行结果
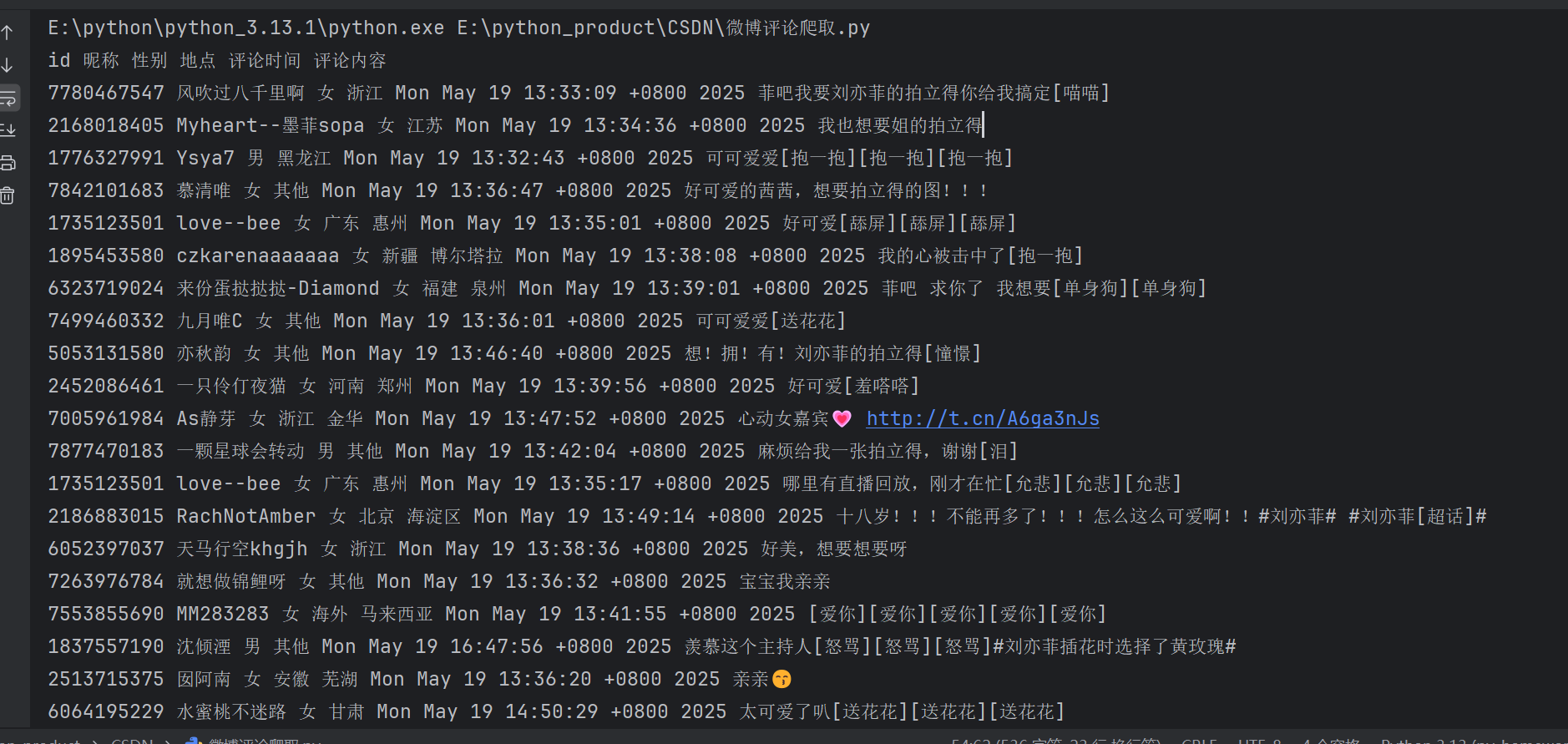
但这里只能获取前20条的评论
我们需要获取的是所有的评论
所有找的第21条的数据然后搜索还有第41条的数据搜索对比一下参数
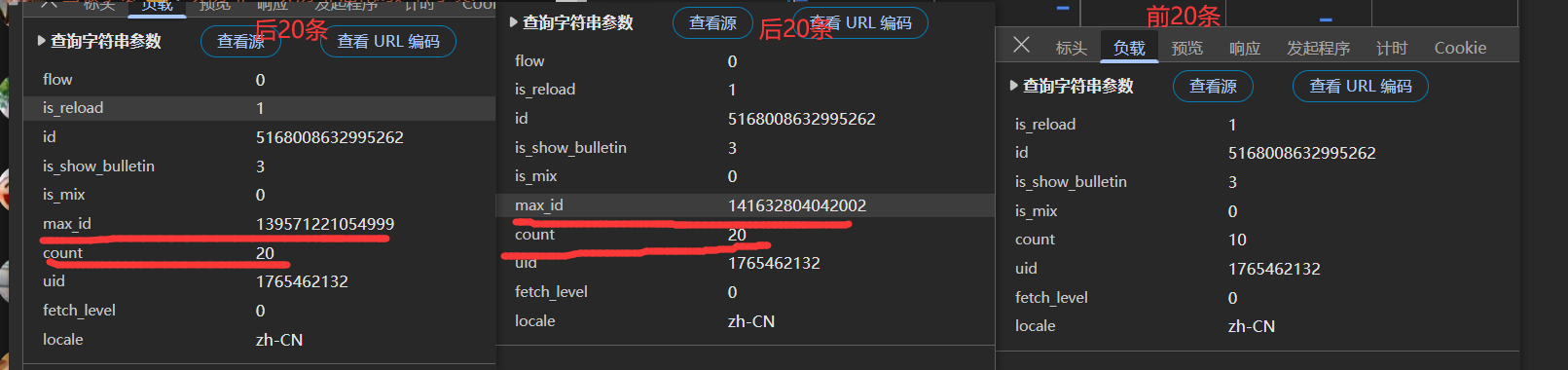
发现后面都有一个flow参数,但第一个没有,我们使用第请求头不带flow参数行不行。
然后还多了一个max_id参数并且count的值变成了20
我们先把第一个试一试把count从10变成20
params = {
'is_reload': '1',
'id': '5168008632995262',
'is_show_bulletin': '3',
'is_mix': '0',
'count': '20',
'uid': '1765462132',
'fetch_level': '0',
'locale': 'zh-CN'
}发现结果并不影响。
然后添加max_id参数
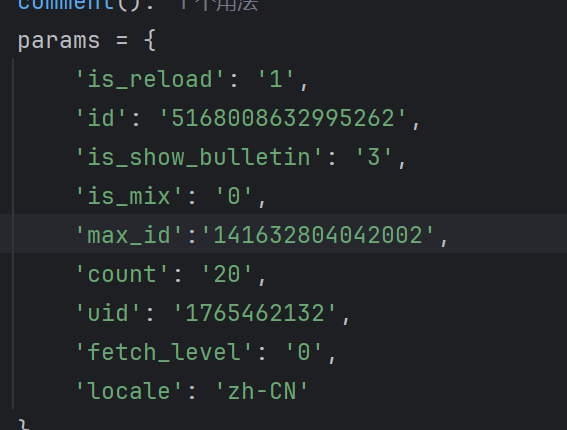
运行结果

然后发现max_id参数是从上一个评论里面的结果里面获取的
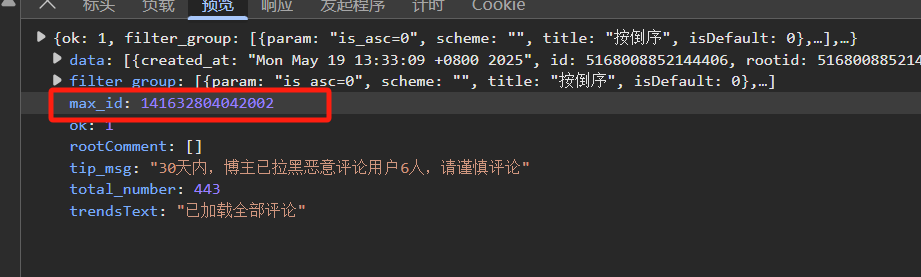
所以我们添加一个函数获取上一条评论的max_id的值并保持即可
max_id = json['max_id']
return max_id然后设置一个循环,但是前20条的评论中max_id是空所以用一个循环获取max_id
max_id = ''
for i in range(1,3):
max_id = comment(max_id=max_id)完整代码就是
import requests
import time
#等待1s
time.sleep(1)
#请求头
headers = {
'cookie':'SCF=AkfFEbIIt9K25XjQVB-Ei7i2ad64n3QkrNoUaXM8UCGulbx9ia1b8LVfqXCGJSIVzH0NL06hgrvq5QhwsgRbzTE.; SINAGLOBAL=9601544246784.834.1742785949889; PC_TOKEN=7614d44475; ALF=1750260544; SUB=_2A25FLz4QDeRhGeFH7FIT8irEwjWIHXVmRT_YrDV8PUJbkNANLRPmkW1NeoJe5zo79MOZImcpVgTX-vaO0u5UOTXg; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW3.SY6Z_g83CRezlZxi3sr5JpX5KMhUgL.FoM4S05EeoBR1K.2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KM7eozX1h.4; XSRF-TOKEN=6rGftJ_koCdwS_tnV7QSWNp4; WBStorage=036f61cc|undefined; _s_tentry=weibo.com; Apache=416113508804.22003.1747668586057; ULV=1747668586180:10:2:1:416113508804.22003.1747668586057:1746188519803; WBPSESS=ruAF00To3bxFjRRKO9IcqbZfbcYBPpyNn_nn-fza1HUoGjFXih-NcK6izx2NA2K5tPB9cii7EmJ346GBSyi2JVeB5FmOdZSiJuo4WSmLGAWu0Wock-Eh7VLXy2mK0w4Ixk1E6VhUBtbo-rLvskFU5g==',
'referer':'https://weibo.com/1765462132/PsxdlczcG',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
url = 'https://weibo.com/ajax/statuses/buildComments?'
def comment(max_id):
params = {
'is_reload': '1',
'id': '5168008632995262',
'is_show_bulletin': '3',
'is_mix': '0',
'max_id':max_id,
'count': '20',
'uid': '1765462132',
'fetch_level': '0',
'locale': 'zh-CN'
}
response = requests.get(url, headers=headers, params=params)
# print(response.status_code)
# print(response.json())
json = response.json()
data = json['data']
print('id', '昵称', '性别', '地点', '评论时间', '评论内容')
for i in data:
# id
id = i['user']['id']
# 昵称
screen_name = i['user']['screen_name']
# 性别
gender = i['user']['gender']
if gender == 'f':
gender = '女'
elif gender == 'm':
gender = '男'
else:
gender = '保密'
# 坐标
location = i['user']['location']
# 评论时间
created_at = i['created_at']
# 评论内容
text_raw = i['text_raw']
print(id, screen_name, gender, location, created_at, text_raw)
max_id = json['max_id']
return max_id
# print(max_id)
if __name__ == '__main__':
max_id = ''
for i in range(1,3):
max_id = comment(max_id=max_id)但这样只是获取了里面的评论的数量,完全是根据最后rang中的乘以20来算的。
这样还是不能获取里面全部的443条评论。
所以可以设置一个函数来获取443条评论然后除以20在加1来设置程序的运行次数。
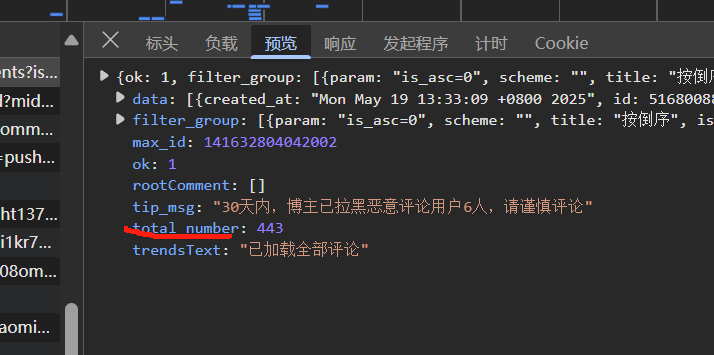
首先写一个函数获取评论数量。
发现评论数量在
def total_number():
params = {
'is_reload': '1',
'id': '5168008632995262',
'is_show_bulletin': '3',
'is_mix': '0',
'count': '20',
'uid': '1765462132',
'fetch_level': '0',
'locale': 'zh-CN'
}
response = requests.get(url, headers=headers, params=params)
json = response.json()
#评论数量
total_number = json['total_number']
print(total_number)结果为
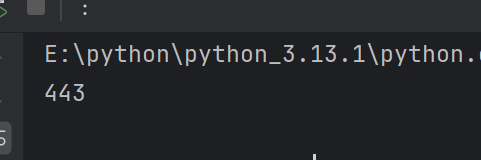
可以正常获取评论数量,然后就可以写一个函数。
用评论数量除以20然后商加一的次数。
这样就能解决运行次数的问题了
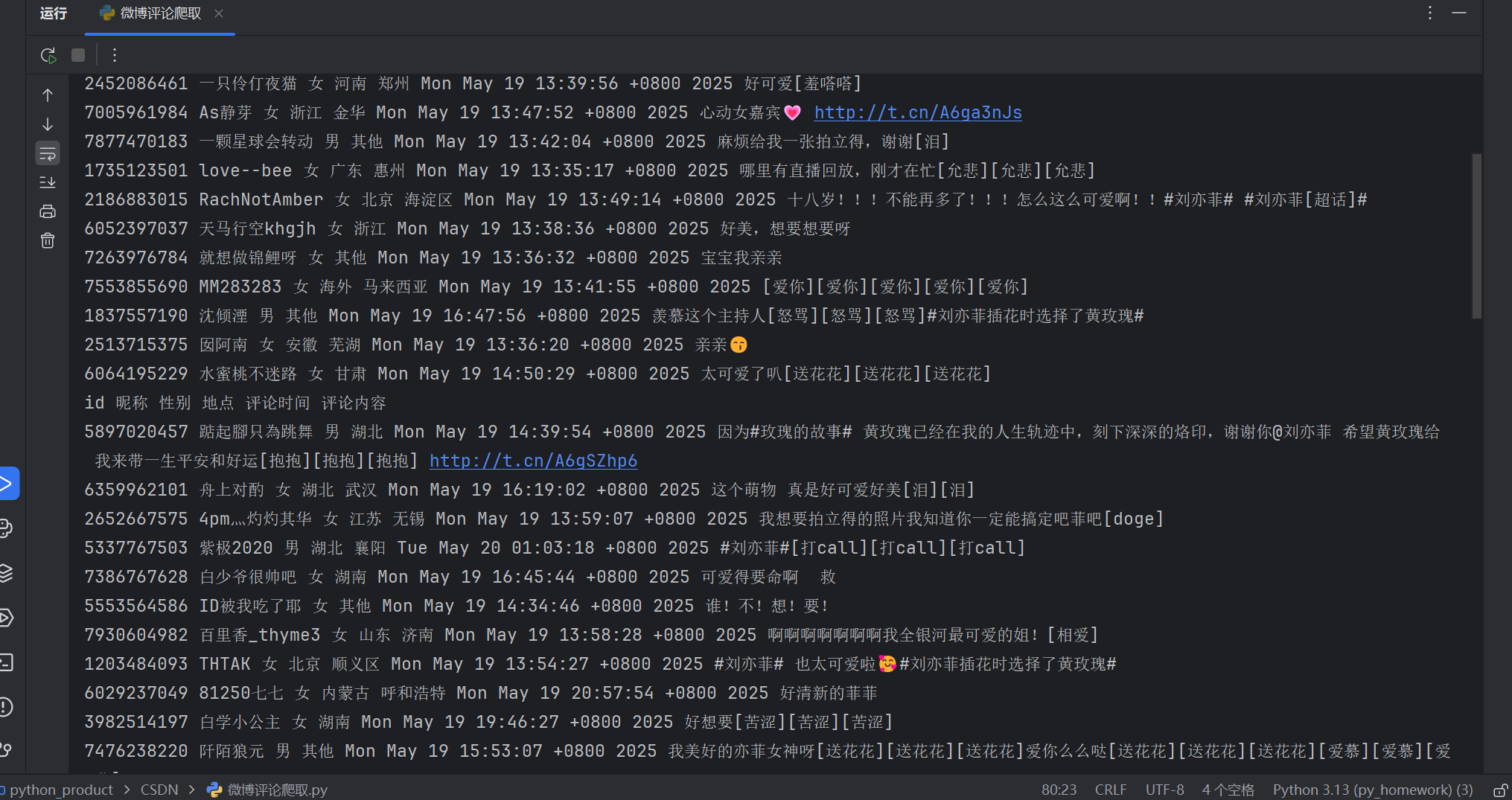
接下来就是写入csv文件了
开头加入

然后末尾加入

即可
还有就是在函数里面最好加入
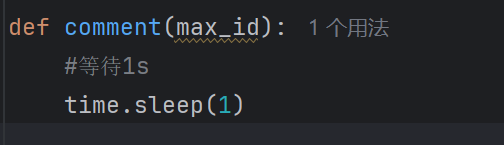
我觉得能防止被封ip,
运行结果
完整代码
import requests
import csv
import time
f = open('评论.csv',mode='w',encoding='utf-8-sig',newline='')
writer = csv.writer(f)
#写入表头
writer.writerow(('id','昵称','性别','地点','评论时间','评论内容'))
#等待1s
time.sleep(1)
#请求头
headers = {
'cookie':'SCF=AkfFEbIIt9K25XjQVB-Ei7i2ad64n3QkrNoUaXM8UCGulbx9ia1b8LVfqXCGJSIVzH0NL06hgrvq5QhwsgRbzTE.; SINAGLOBAL=9601544246784.834.1742785949889; PC_TOKEN=7614d44475; ALF=1750260544; SUB=_2A25FLz4QDeRhGeFH7FIT8irEwjWIHXVmRT_YrDV8PUJbkNANLRPmkW1NeoJe5zo79MOZImcpVgTX-vaO0u5UOTXg; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WW3.SY6Z_g83CRezlZxi3sr5JpX5KMhUgL.FoM4S05EeoBR1K.2dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1KM7eozX1h.4; XSRF-TOKEN=6rGftJ_koCdwS_tnV7QSWNp4; WBStorage=036f61cc|undefined; _s_tentry=weibo.com; Apache=416113508804.22003.1747668586057; ULV=1747668586180:10:2:1:416113508804.22003.1747668586057:1746188519803; WBPSESS=ruAF00To3bxFjRRKO9IcqbZfbcYBPpyNn_nn-fza1HUoGjFXih-NcK6izx2NA2K5tPB9cii7EmJ346GBSyi2JVeB5FmOdZSiJuo4WSmLGAWu0Wock-Eh7VLXy2mK0w4Ixk1E6VhUBtbo-rLvskFU5g==',
'referer':'https://weibo.com/1765462132/PsxdlczcG',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0'
}
url = 'https://weibo.com/ajax/statuses/buildComments?'
def total_number():
params = {
'is_reload': '1',
'id': '5168008632995262',
'is_show_bulletin': '3',
'is_mix': '0',
'count': '20',
'uid': '1765462132',
'fetch_level': '0',
'locale': 'zh-CN'
}
response = requests.get(url, headers=headers, params=params)
json = response.json()
#评论数量
total_number = json['total_number']
return total_number
# print(total_number)
def comment(max_id):
#等待1s
time.sleep(1)
params = {
'is_reload': '1',
'id': '5168008632995262',
'is_show_bulletin': '3',
'is_mix': '0',
'max_id':max_id,
'count': '20',
'uid': '1765462132',
'fetch_level': '0',
'locale': 'zh-CN'
}
response = requests.get(url, headers=headers, params=params)
# print(response.status_code)
# print(response.json())
json = response.json()
data = json['data']
print('id', '昵称', '性别', '地点', '评论时间', '评论内容')
for i in data:
# id
id = i['user']['id']
# 昵称
screen_name = i['user']['screen_name']
# 性别
gender = i['user']['gender']
if gender == 'f':
gender = '女'
elif gender == 'm':
gender = '男'
else:
gender = '保密'
# 坐标
location = i['user']['location']
# 评论时间
created_at = i['created_at']
# 评论内容
text_raw = i['text_raw']
print(id, screen_name, gender, location, created_at, text_raw)
writer.writerow([id, screen_name, gender, location, created_at, text_raw])
max_id = json['max_id']
return max_id
# print(max_id)
if __name__ == '__main__':
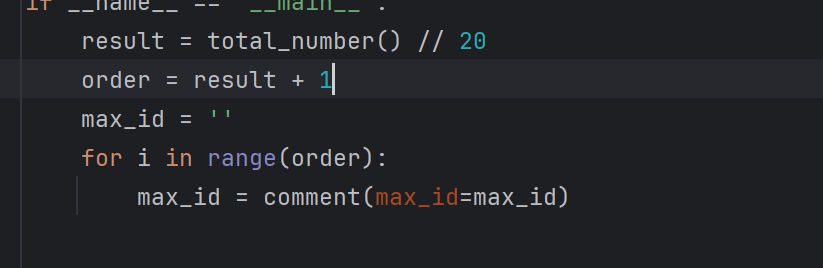
result = total_number() // 20
order = result + 1
max_id = ''
for i in range(order):
max_id = comment(max_id=max_id)
















 2171
2171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









