







 本篇文章详细介绍了RAG技术,包括其原理、与传统微调的区别,以及茴香豆这款模型的特点和应用。茴香豆提供了商业化许可和本地部署选项,降低了知识更新的成本。同时,实践部分展示了Web版和InternStudio部署方法。
本篇文章详细介绍了RAG技术,包括其原理、与传统微调的区别,以及茴香豆这款模型的特点和应用。茴香豆提供了商业化许可和本地部署选项,降低了知识更新的成本。同时,实践部分展示了Web版和InternStudio部署方法。
课程链接:茴香豆:搭建你的 RAG 智能助理_哔哩哔哩_bilibili
整节课共分为三个模块
一、RAG:
是什么、原理、RAG vs Fine-tune、架构、向量数据库、评估和测试
二、茴香豆:
茴香豆介绍、茴香豆的特点、架构、构建步骤
三、实践演示:
茴香豆Web版演示
Intern Studio部署茴香豆知识助手
InternLM2-Chat-7B & 茴香豆InternLM2-Chat-7B RAG助手 的比较

传统上采集新增语料,接着通过微调等方式对模型进行再训练
遇到的问题:知识更新太快、语料大、训练成本高、 时效性等
而茴香豆RAG助手无需训练即可回答对应问题
RAG技术概述

定义
RAG(Retrieval Augmented Generation/检索增强生成技术)
涉及从外部知识源解锁相关信息,并将这些信息用于指导语言模型生成更准确、更丰富的回答
可以将RAG理解成搜索引擎,将用户输入的内容作为索引,在外部知识库中搜寻相应的内容,结合大语言模型的能力生成回答。
特点
解决LLMS在处理知识密集型任务时可能遇到的挑战。
如生成幻觉、对于新闻新技术等新知识的缺失问题,以及在回答时很难给出到我们可追溯以及透明的过程和论证,而RAG可以提供更准确的回答、降低训练过程产生的成本、实现外部记忆。
应用
问答系统 文本生成 信息检索 图片描述(在结合多模态大模型之后)
RAG工作原理
RAG结合了检索和生成技术,利用外部知识库增强LLM性能
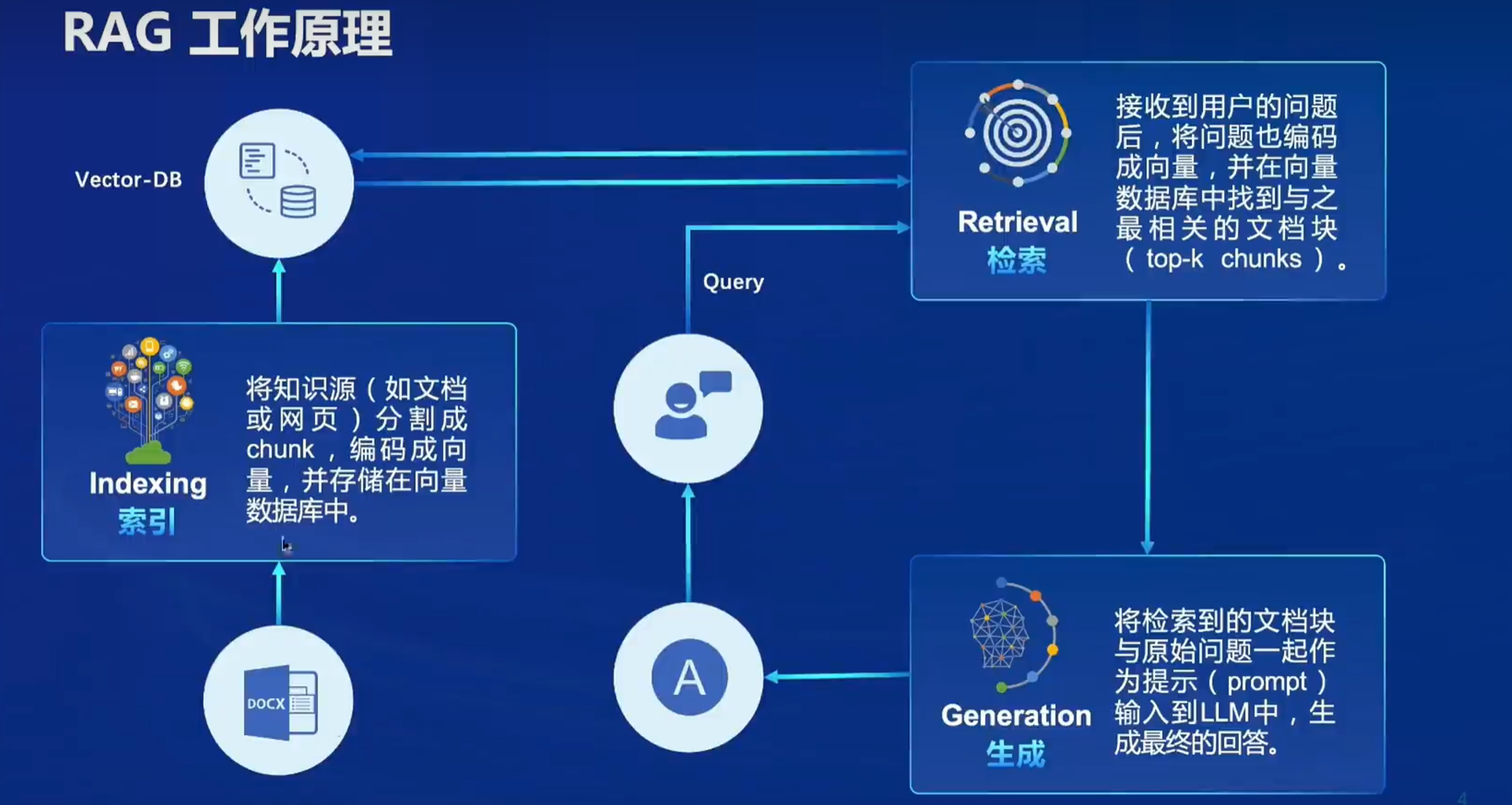
1.1 向量数据库
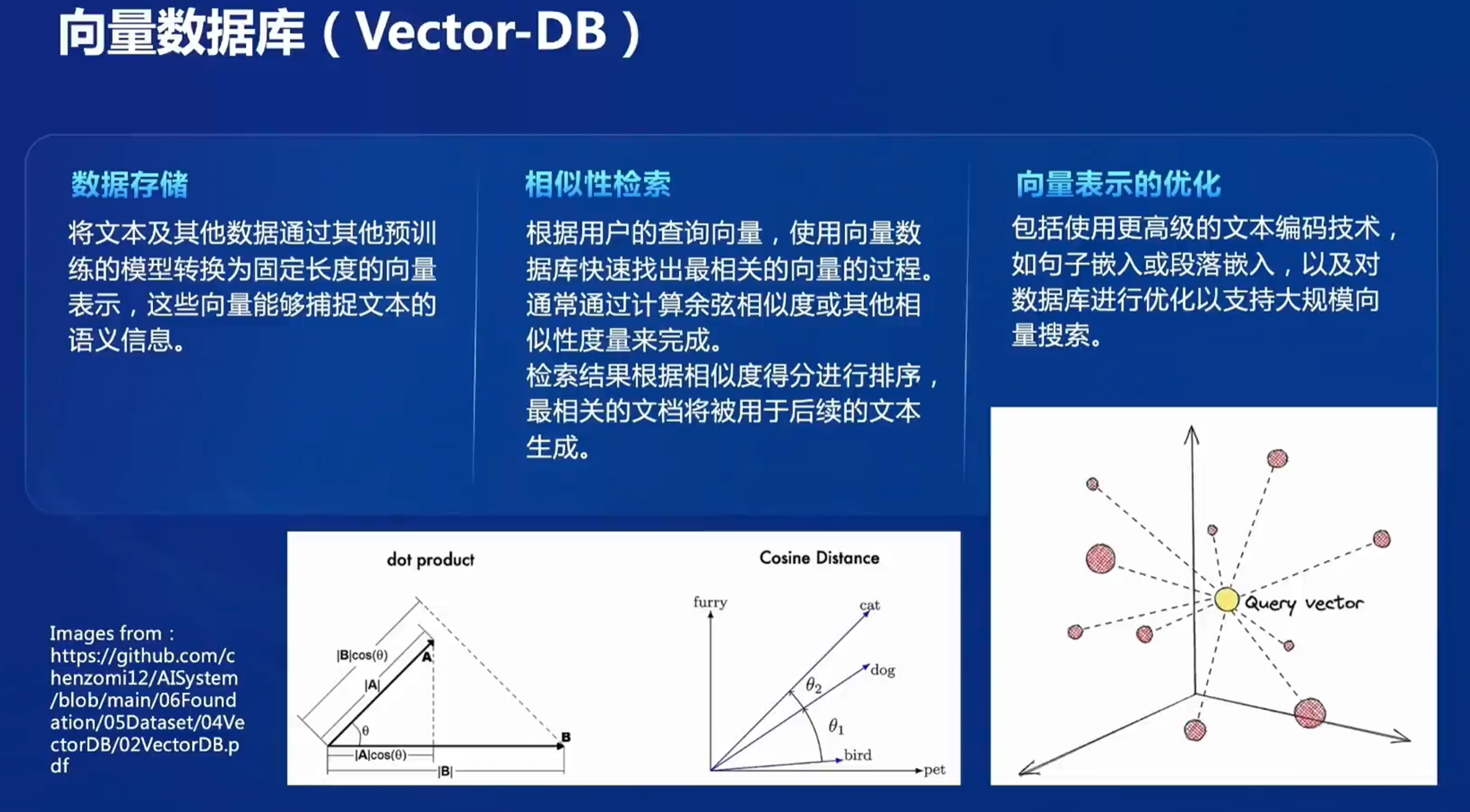
向量数据库是RAG技术当中专门储存外部数据的地方,主要实现将文本及数据通过预训练的模型转换为固定长度的向量。
是快速回答的基础,因此需要能够高效地实现相似性检索。
面向大规模数据以及需要高速响应的需求时,向量数据库也需要优化,尤其对向量表示的优化,对向量表示的优化将直接影响RAG结果的好坏
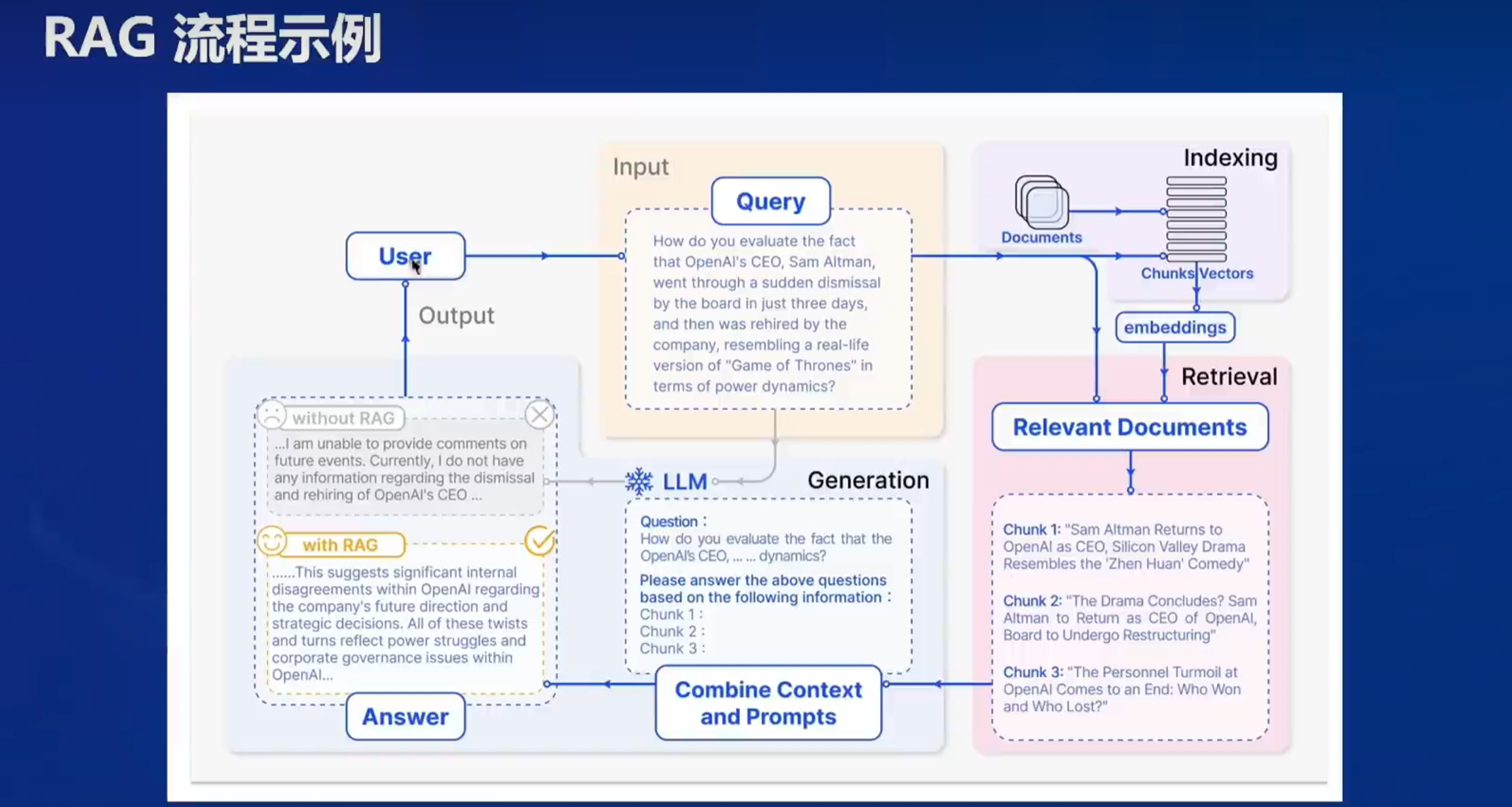
1.2传统问答体系中的大模型&RAG处理流程解构
用户的提问被输入检索模块,
传统大模型生成无关信息或生成幻觉,
而RAG检索模块把问题向量化后进行一个embeddings,然后在已经存在的向量数据库中进行搜索,从中检索出相似性最高的片段。
如范例中检索出三段和Sam离职返回openai相关内容的文本,接着将用问题和三段文本共同给到生成模块,生成模块将问题和文本作为提示词开始生成回答内容。
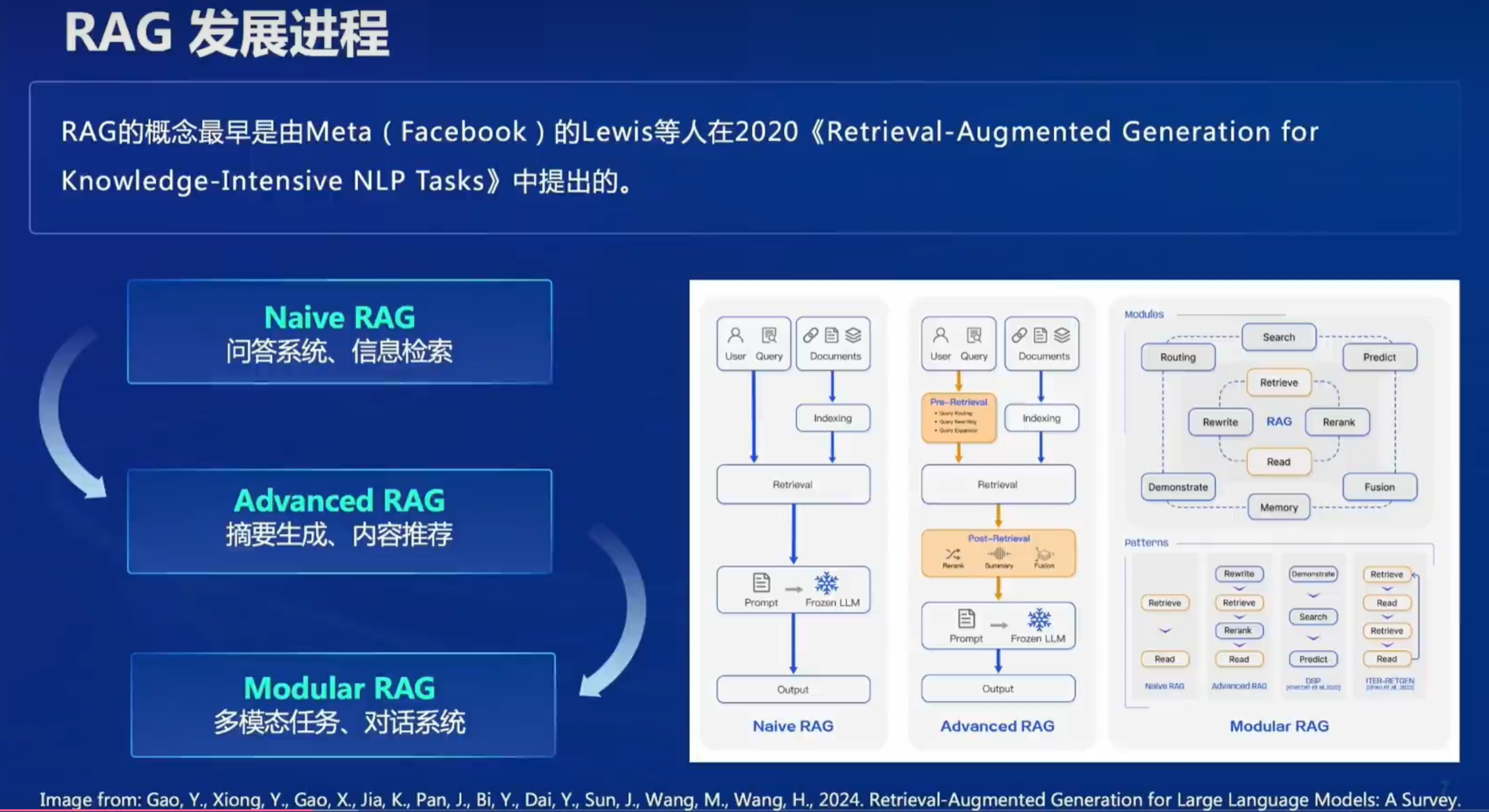
1.3 RAG发展进程
发展时间短但迅猛
Naive RAG
Advanced RAG
Modular RAG
1.4 RAG常见优化方法
1.4.1 提高向量数据库的质量
嵌入优化 结合稀疏和密集检索 多任务
索引优化 细粒度分割 元数据
1.4.2 前检索、后索引部分
查询优化 查询扩展、转换 多查询
上下文管理 重排(re-rank) 上下文选择、压缩
1.4.3 检索优化
迭代检索
递归检索 CoT
自适应检索

1.4.4 LLM微调
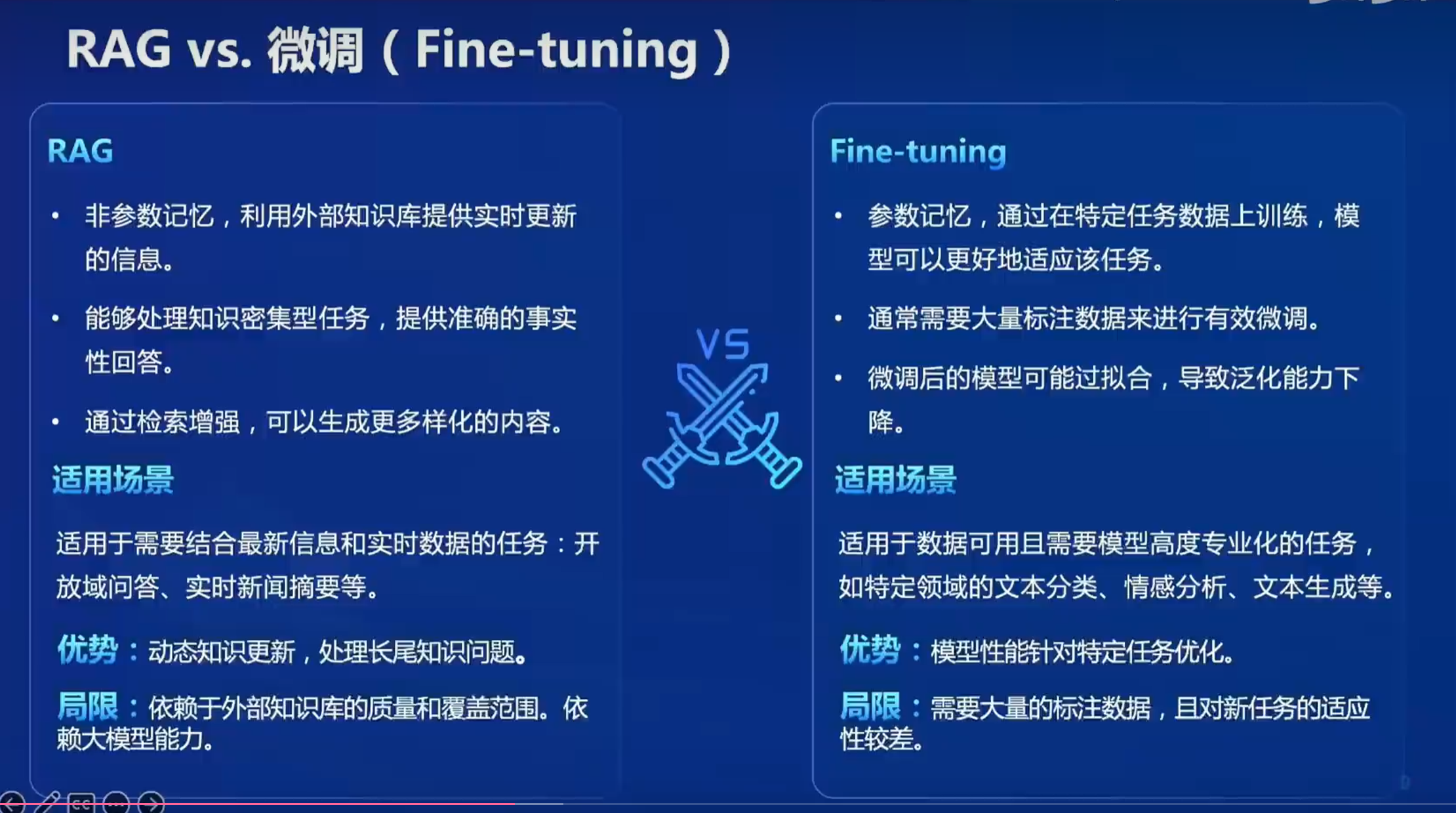
1.5 RAG vs 微调
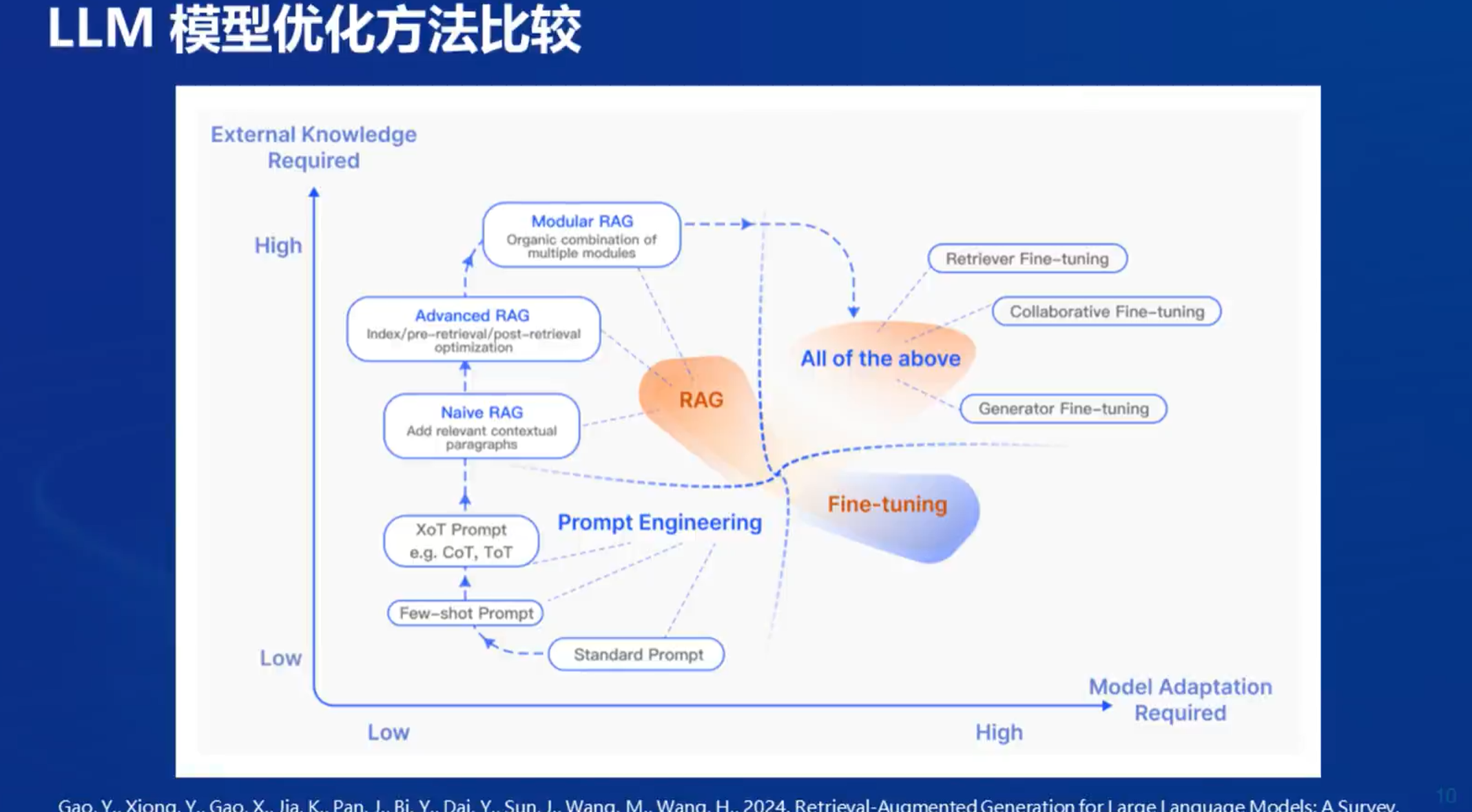
1.6 LLM优化方法比较
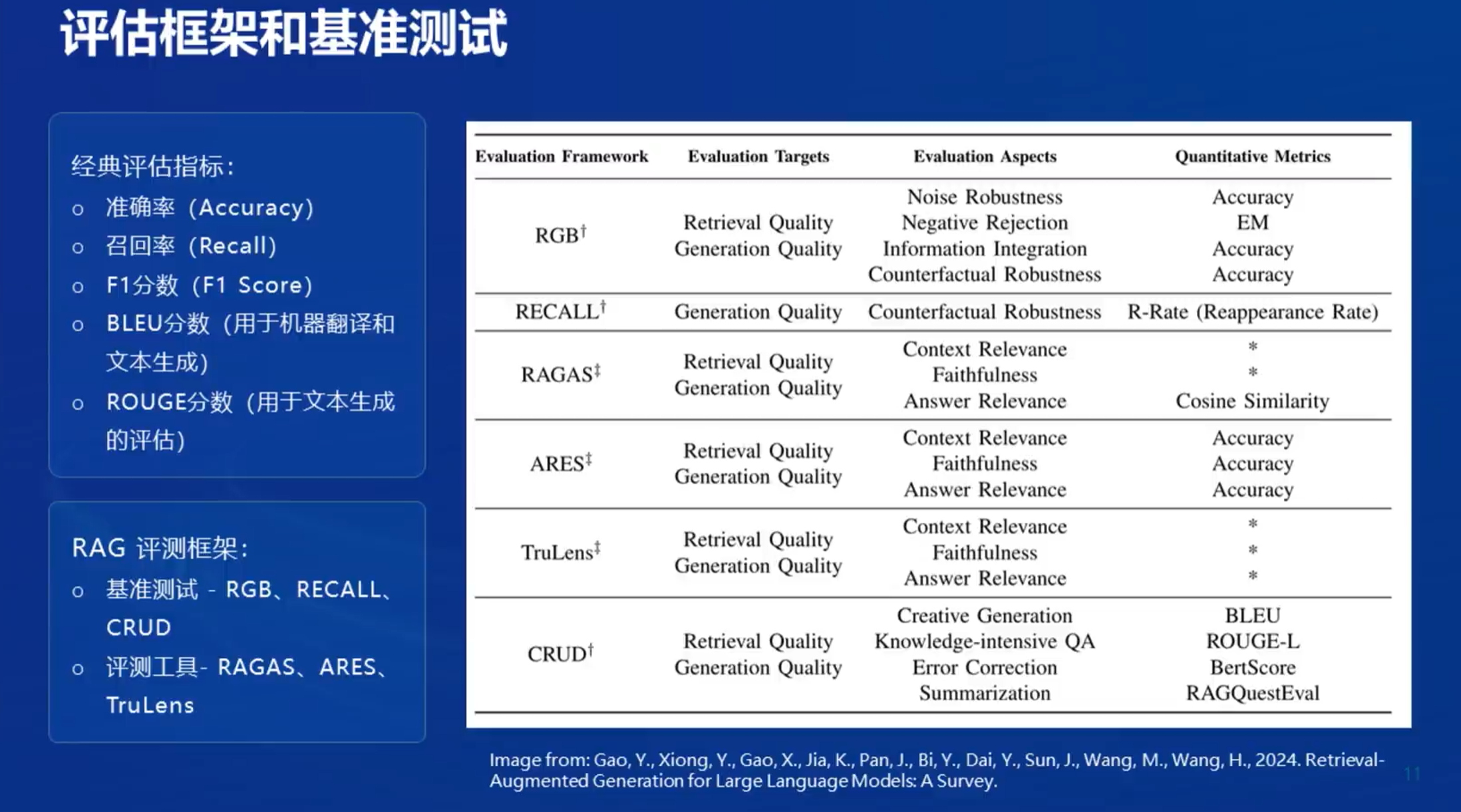
1.7 RAG的评测
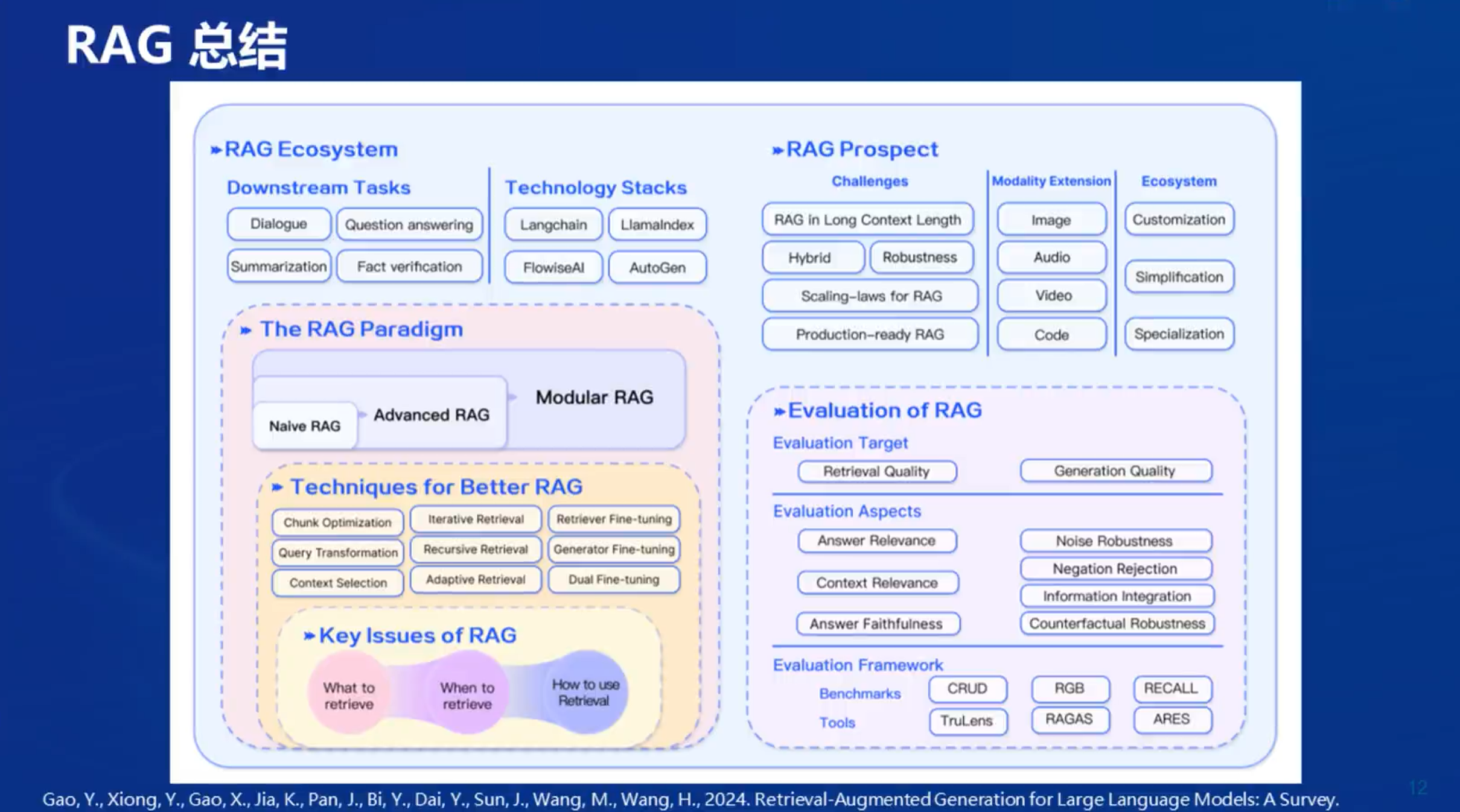
1.8 RAG总结
2 茴香豆

2.1 核心特性
BSD-3-Clause许可证下的模型可用于商业用途,同时提供了云端API调用,减少了本地计算资源需求。它具有完全本地部署的能力,从而保护用户的隐私。此外,该模型具有很强的扩展性,可以适应各种不同的应用场景和需求。

2.2 茴香豆构建
知识库支持markdown word pdf ppt txt等格式的文档

2.3 工作流
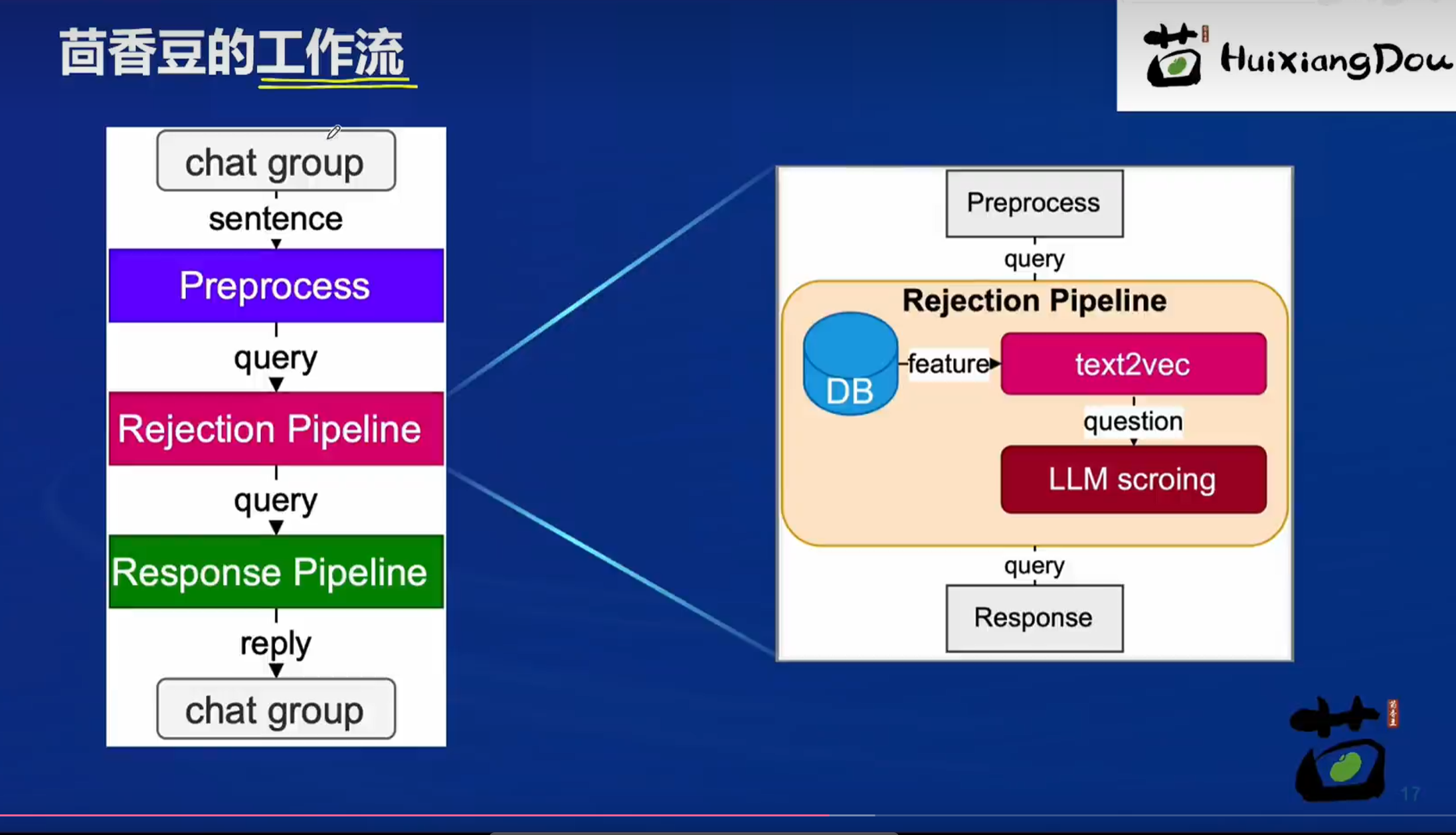
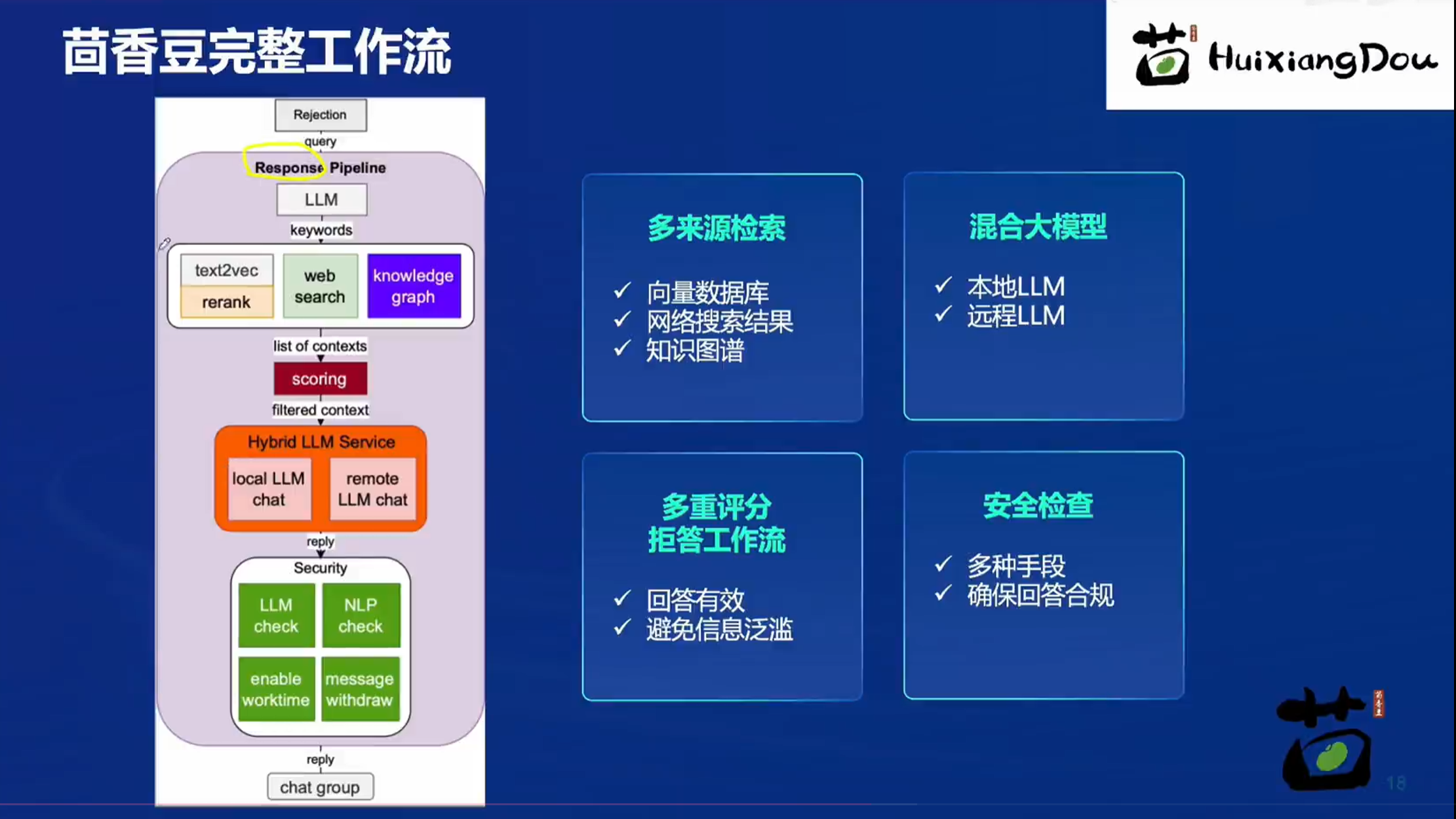
茴香豆仓库:https://github.com/InternLM?HuixiangDou
3.实践
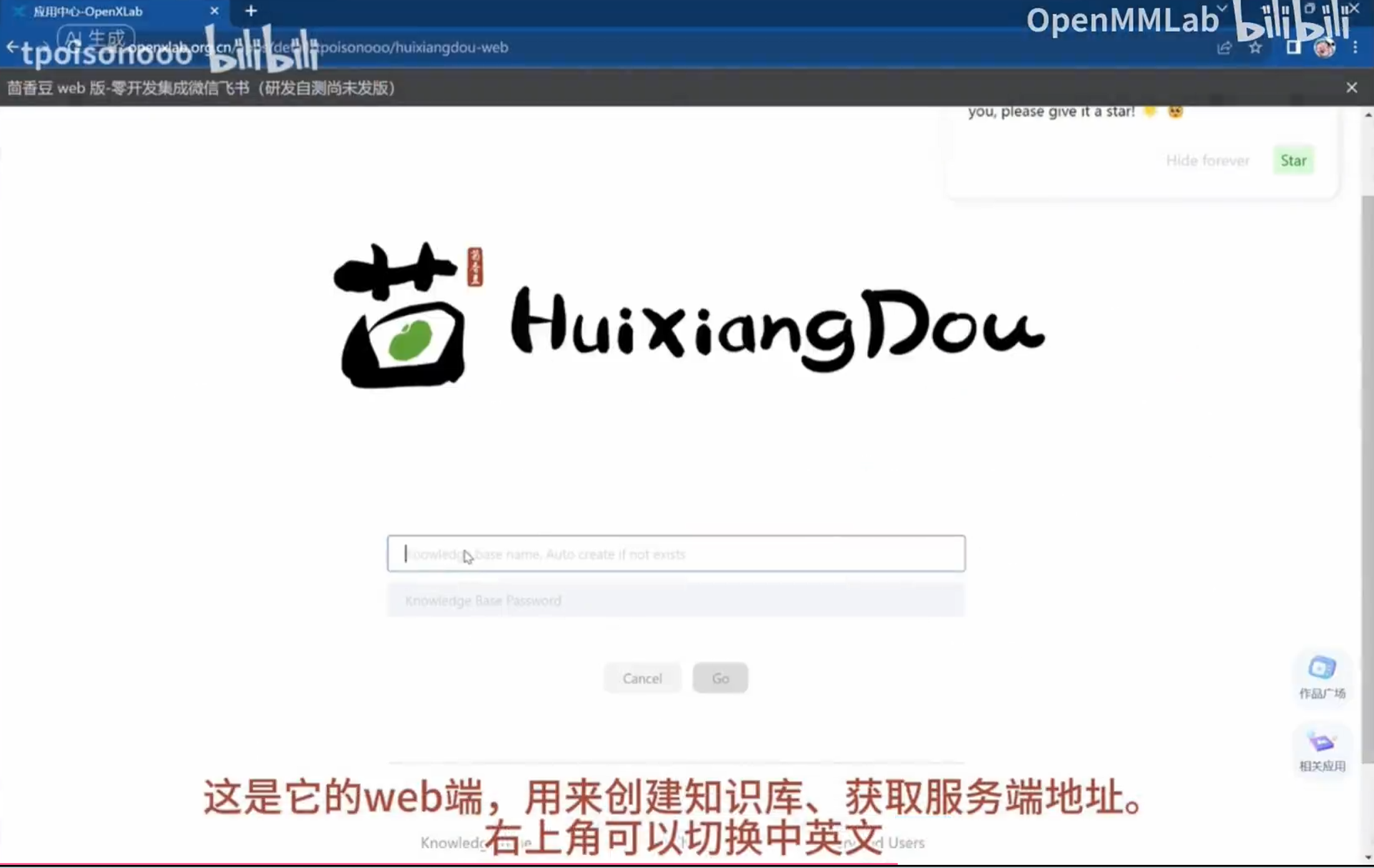
3.1实践一:茴香豆web版
3.2实践二:Intern Studio部署茴香豆

报名链接:















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









