







1. STAD介绍
动作检测spatio-temporal action detection (STAD)的目的是对视频中的人物动作进行时空定位和分类。
动作检测模型可以被分为两类:帧级(frame-level)和剪辑片段级(clip-level)
- 帧级:在视频的每一帧上独立应用动作检测器生成2D边界框,然后用连接算法将每一帧的检测结果关联,生成3D动作管(action tubes)
- 剪辑片段级:输入短视频片段,直接输出片段中的3D时空管(3D spatio-temporal tubelet)建议。然后将连续的视频片段中的管建议连接在一起形成完整动作管
在线动作检测任务需要对捕获到的帧即时处理,即时给出动作的定位和分类。下面我将主要介绍帧级模型中的具有高效和实时速度(High efficiency and real-time speed)的模型。
2. 高效实时动作检测
2.1 双流SSD——2016
论文标题:Online Real-time Multiple Spatiotemporal Action Localisation and Prediction
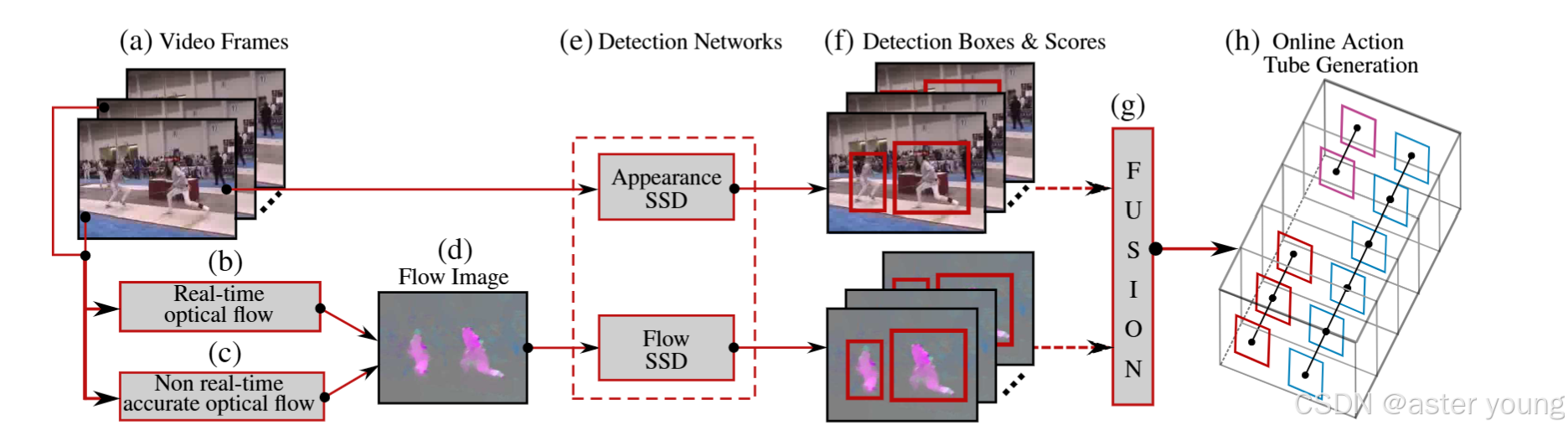
论文发表于2016年,此时I3D网络还未提出,最主流的视频识别网络还是双流神经网络。
双流网络由两个主干网络组成,RGB流和光流,RGB流提取空间特征,光流提取运动特征
由于光流的提取非常耗时且占用空间,基于光流的方法在视频识别和视频检测中逐渐被3D时空卷积方法淘汰。
作者提出的网络在双流神经网络的基础上引入了SSD,做到了实时的动作定位和分类。
单阶段网络优点:
- 单阶段网络相比于双阶段网络有更快的计算速度。
- 两阶段网络需要分别训练区域提议网络和分类网路,只能找到局部最优解。单阶段网络检测器与动作分类器联合训练,避免了这个问题。
- 单阶段网络的训练成本相比于两阶段网络更低,不需要额外用COCO数据集预训练RPN。
RGB流生成基于外观的检测框,光流生成基
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









