






跟着刷题:22 统计每个学校的答过题的用户的平均答题数_哔哩哔哩_bilibili
前面纯纯纯是语法开始,第22题开始就要仔细分析业务了......
22统计每个学校的答过题的用户的平均题数
说明:某学校用户平均答题数量计算方式为该学校用户答题总次数除以答过题的不同用户个数
select
b.university as university
, count(1) / count(distinct a.device_id) as avg_answer_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
group by 1
order by 123统计每个学校各难度的用户平均刷题数(这题有详细解题步骤,因为开始变难了)

事实表、维度表、信息表?
- 事实表:带着业务的?
- 这里的用户信息表user_profile是一张维度表
第一步连接(多表连接)
select
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
left join question_detail c
on a.question_id = c.question_id第二步选出结果要的列

第三步根据限定操作(不同学校、不同难度--->分组)
![]()
bug?刚刚在牛客提交,明明是一样的答案提交错误,等了一会就可以了
select
b.university as university
,c.difficult_level as difficult_level
,count(1) / count(distinct a.device_id) as avg_answer_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
left join question_detail c
on a.question_id = c.question_id
group by 1, 224统计每个用户的平均刷题数

24题与23题只有些许不同
法1:全部连接之后再筛选
此时,所有行都是有值的,然后筛选出“山东大学”的
解释:
- JOIN操作:首先对
question_practice_detail表(a)与user_profile表(b)进行左连接,然后将结果与question_detail表(c)进行左连接。这意味着所有question_practice_detail的记录都会被包含,即使它们在user_profile或question_detail中没有匹配项。 - WHERE子句:在完成连接后,通过
WHERE b.university = '山东大学'过滤出大学为“山东大学”的记录。这意味着只有当user_profile表中的设备ID对应的是山东大学的学生时,这些记录才会被计算在内。但是,因为这个条件放在了JOIN之后,它实际上转化成了对整个JOIN结果集的过滤,可能会影响到分母(即COUNT(DISTINCT a.device_id))的计算,因为它是在过滤之后计数的,理论上这不会影响到本例的结果,因为过滤条件是基于user_profile表的字段,但这种写法可能导致逻辑不清晰。 - GROUP BY:最后按照大学和题目难度级别分组,并计算每组的平均作答数量。
select
b.university as university
,c.difficult_level as difficult_level
,count(1) / count(distinct a.device_id) as avg_answer_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
left join question_detail c
on a.question_id = c.question_id
where b.university = '山东大学'
group by 1,2法2:也可以在连接的同时进行筛选
或者说叫:筛选是山东大学的值连接,那么,左表会有一些值是其它大学的,因为右表没有值 给它连接,那么就连了空值
- 筛选条件的位置:筛选条件
b.university = '山东大学'直接放在了JOIN语句中,而不是在WHERE子句里。这样做在逻辑上等同于先做了一个内连接的筛选,只包括了山东大学的记录,然后再进行其他操作。这种方式比在WHERE子句中应用筛选更加高效,因为它减少了需要处理的数据量,尤其是在user_profile表较大的情况下。 - 使用了
WHERE b.device_id IS NOT NULL来进一步过滤掉那些在user_profile表中没有匹配到的设备ID记录。
select
b.university as university
,c.difficult_level as difficult_level
,count(1) / count(distinct a.device_id) as avg_answer_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
and b.university = '山东大学'
left join question_detail c
on a.question_id = c.question_id
where b.device_id is not null
group by 1,2法3:法3相比前两个更好
法3和法2很像,法3将left join 改为join:在连接的时候就会把右表没有对应值的行直接去掉
连接类型的变化:这里,JOIN user_profile b 使用的是内连接(JOIN默认为内连接),而非之前的左连接(LEFT JOIN)。这意味着只有当question_practice_detail表中的设备ID在user_profile表中存在,并且该用户是山东大学的学生时,这些记录才会被包含在最终结果集中。这与前两个查询不同,前两者使用左连接保留了question_practice_detail表中的所有记录,即便在user_profile中找不到匹配项。
select
b.university as university
,c.difficult_level as difficult_level
,count(1) / count(distinct a.device_id) as avg_answer_cnt
from question_practice_detail a
join user_profile b
on a.device_id = b.device_id
and b.university = '山东大学'
left join question_detail c
on a.question_id = c.question_id
group by 1,225查找山东大学或者性别为男生的信息
关键字:union,上下拼接(列的数量要匹配)
- union:会帮你去重
- union all:不去重

第一步先分别完成以下逻辑:
select
device_id, gender, age, gpa
from user_profile
where university = '山东大学'
select
device_id, gender, age, gpa
from user_profile
where gender = 'male'第二步:用union关键字拼接:
select
device_id, gender, age, gpa
from user_profile
where university = '山东大学'
union all
select
device_id, gender, age, gpa
from user_profile
where gender = 'male'26计算25岁以上和以下的用户数量
用if函数,做辅助列?
select
if(age < 25 or age is null, '25岁以下', '25岁及以上') as age_cut
,count(1) as number
from user_profile
group by 127查看不同年龄段的用户明细
case when的使用
当条件有三个或以上的时候就不用if了,改用case when
case when 条件1 then
when 条件2
when 条件3
else XX end
select
device_id
,gender
,case when age < 20 then '20岁以下'
when age >= 20 and age <= 24 then '20-24岁'
when age >= 25 then '25岁及以上'
else '其他' end as age_cut
from user_profile28计算用户8月每天的练题数量
left()函数:字符串处理函数
day()函数:可以取出日期中的天
select
day(date) as day
,count(1)
from question_practice_detail
where left(date, 7) = '2021-08'
group by 129计算用户的平均次日留存率
临时表查询:with XX as()
函数:date_add() date_sub()
自连接:找到下一天的日期,这里因为是要连接表,所以把下一天的日期减一天,让它跟上一天相等,才能连接表


第一步:
- 这里的
WITH语句用于创建一个名为tmp的临时表。在tmp中,我们通过GROUP BY子句将每个device_id和对应的date分组,确保每个用户每天只有一条记录。 - 然后,我们使用
LEFT JOIN将tmp表连接到自身,通过a.device_id = b.device_id和a.date = DATE_ADD(b.date, INTERVAL 1 DAY)来匹配用户在第二天的记录。如果用户在第二天有记录,b.device_id将不为NULL。
with tmp
as(
select
device_id
,date
from question_practice_detail
group by 1,2
)
select
*
from tmp a
left join tmp b
on a.device_id = b.device_id
and a.date = date_sub(b.date, interval 1 day)连接后的表长这样(部分截图):
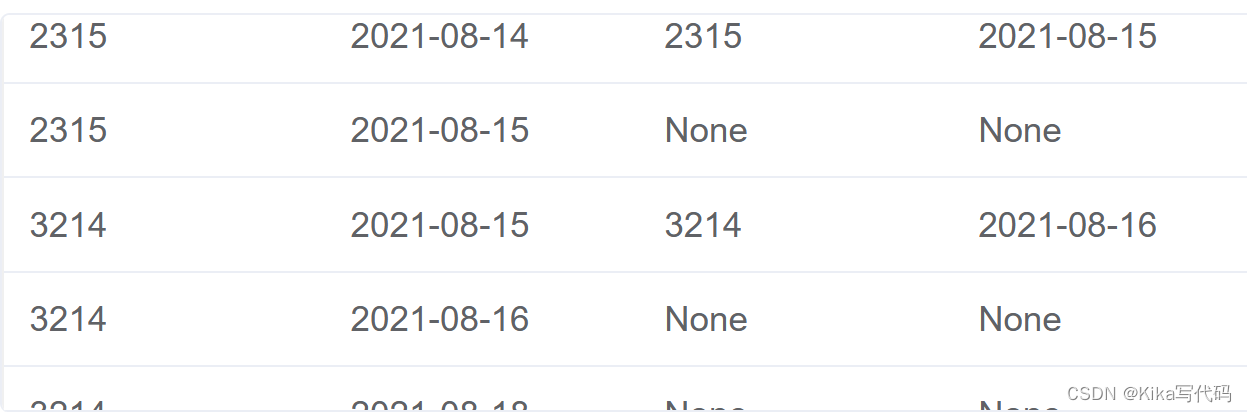
第二步:
- 最后,我们使用
SUM和CASE语句来计算第二天做题的用户数,通过COUNT来计算第一天做题的用户总数,然后用第二天做题的用户数除以第一天的用户总数,得到平均留存率avg_ret。 - 注意谁是分子,谁是分母
- 简言之,连接后的表有四列,我们只关注“前”“后”天之间的关系
- 观察第一列和第二列看出是一个用户有刷题的所有日期的数据,然后所有用户数据上下拼接了。第三第四列就是是否存在后一天的数据,没有就是none
- 前后天,第一天第二天,这里是说同一个东西
with tmp
as(
select
device_id
,date
from question_practice_detail
group by 1,2
)
select
count(b.device_id) / count(a.device_id) as avg_ret
from tmp a
left join tmp b
on a.device_id = b.device_id
and a.date = date_sub(b.date, interval 1 day)30统计每种性别的人数
substring_index()函数:取字段,分隔符
- excel中可以分列做,在sql里没有分列
- 一般很少用,可能是数据库里的数据一般都清洗好了吧

select
substring_index(profile, ',', -1) as gender
,count(1) as number
from user_submit
group by 131提取博客URL中的用户名
select
device_id
,substring_index(blog_url, '/', -1) as gender
from user_submit32截取出年龄
如果不是最后一个字段的话,substring_index()就要写嵌套
select
substring_index(substring_index(profile, ',', 3), ',', -1) as age
,count(device_id) as number
from user_submit
group by 133找出每个学校GPA最低的同学
子查询的使用
- 记得加别名
如果一个学校有多个最低值--->使用窗口函数
第一步:???
select
from(
select
university
,min(gpa) as gpa
from user_profile
group by 1
) a
left join
(
select
*
from user_profile
) b
on a.university = b.university
and a.gpa = b.gpa第二步:选列,排序
select
b.device_id
,a.*
from(
select
university
,min(gpa) as gpa
from user_profile
group by 1
) a
left join
(
select
*
from user_profile
) b
on a.university = b.university
and a.gpa = b.gpa
order by 2这33题有很多的解法,主要还是关注对表格结构(结果和原表)的分析和理解
34统计复旦用户8月练题情况

第一步:
select
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
where b.university = '复旦大学'
and left(a.date, 7) = '2021-08'第二步:
-
sum(if(a.result = 'right', 1, 0))可以写成count(if(a.result = 'right', 1, null))
select
a.device_id as device_id
,b.university as university
,count(question_id) as question_cnt
,sum(if(a.result = 'right', 1, 0)) as right_question_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
where b.university = '复旦大学'
and left(a.date, 7) = '2021-08'
group by 1第三步:
select
a.device_id as device_id
,b.university as university
,count(question_id) as question_cnt
,sum(if(a.result = 'right', 1, 0)) as right_question_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
where b.university = '复旦大学'
and left(a.date, 7) = '2021-08'
group by 1
union all
select
from user_profile a
left join question_practice_detail b
on a.device_id = b.device_id
where b.device_id is null
and a.university = '复旦大学'第四步:
select
a.device_id as device_id
,b.university as university
,count(question_id) as question_cnt
,sum(if(a.result = 'right', 1, 0)) as right_question_cnt
from question_practice_detail a
left join user_profile b
on a.device_id = b.device_id
where b.university = '复旦大学'
and left(a.date, 7) = '2021-08'
group by 1
union all
select
a.device_id as device_id
,a.university as university
,0 as question_cnt
,0 as right_question_cnt
from user_profile a
left join question_practice_detail b
on a.device_id = b.device_id
where b.device_id is null
and a.university = '复旦大学'35浙大不同难度题目的正确率
36查找后排序
37查找后多列排序
38查找后降序排列
39 21年8月份练题总数















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









