






Hadoop大数据集群搭建
基础条件:VMware+CentOS7(操作简单,在此省略)
完成基础条件下打开虚拟机,进行以下操作
必读预告:关于复制粘贴功能,可能部分虚拟机很难用,所以可以在MobaXtem_Portable进行后续操作
关于地址问题,文章所用地址是在本人亲测可用情况下使用,看自己的适合哪个
由于是配置完成后整理,可能部分步骤并不严谨,欢迎指正
一、前置准备
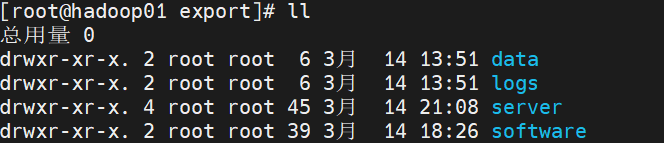
1.创建文件夹
ps:可能发现并没有创建,所以可以先创建export,再创建4个小的~
mkdir export
cd export
mkdir server
mkdir software
mkdir data
mkdir logs
2.网络配置
三个虚拟机的ip分别配置为:
192.168.121.134 node1
192.168.121.135 node2
192.168.121.136 node3
1)编辑-虚拟网络编辑器
2)更改设置
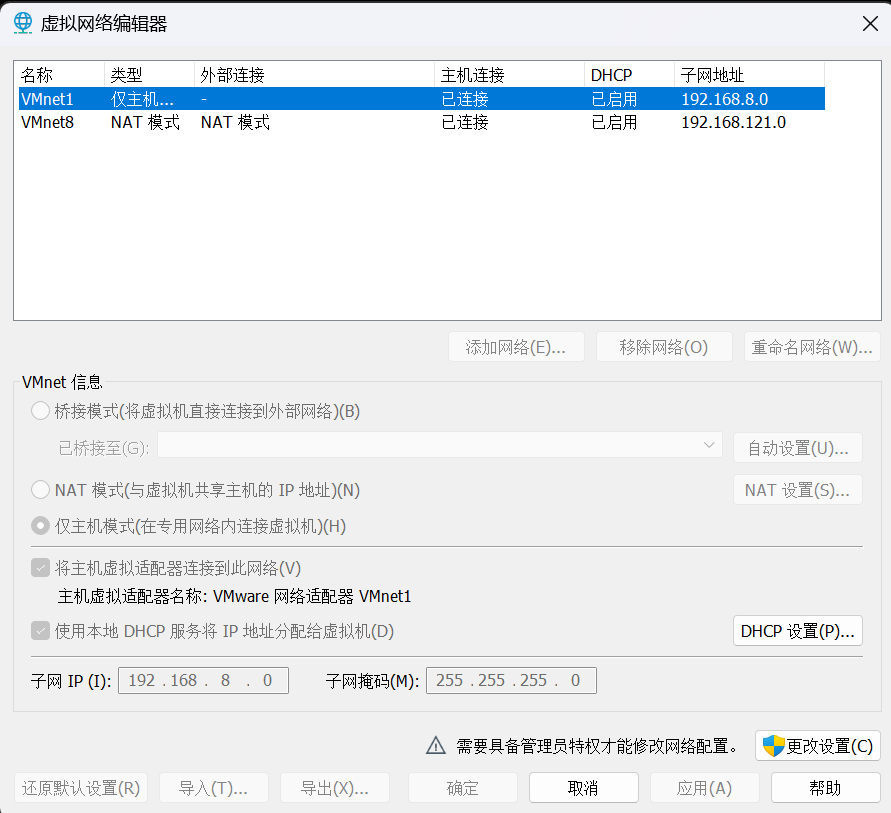
3)更改子网IP
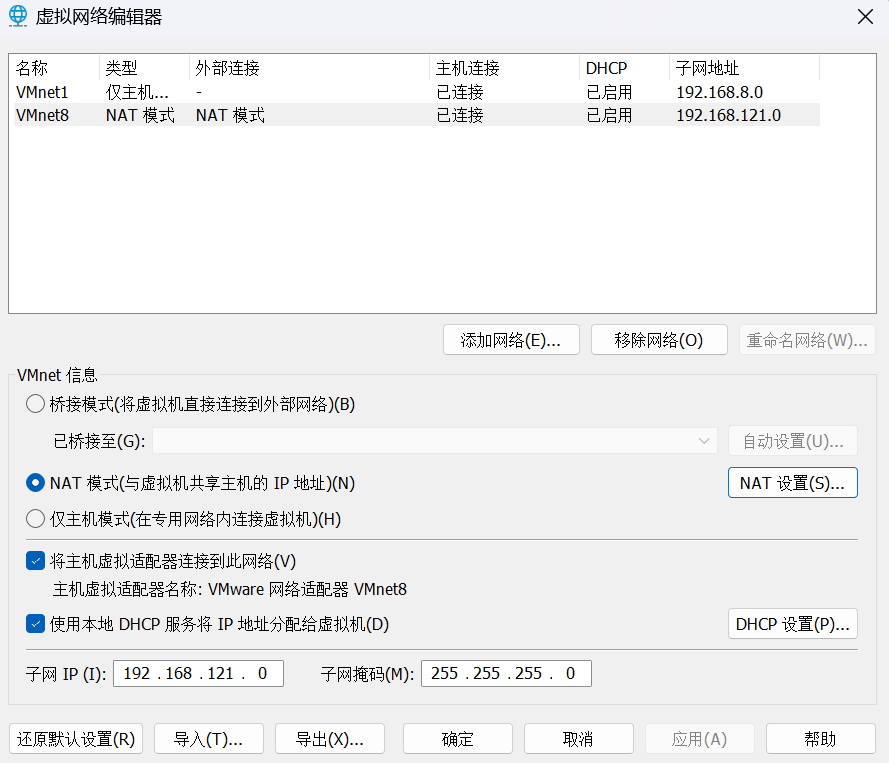
4)更改NAT设置
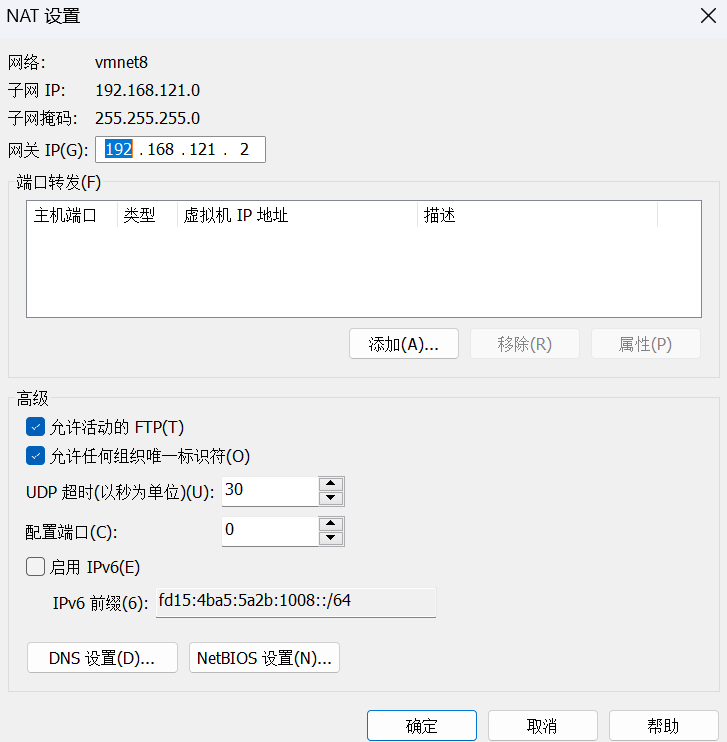
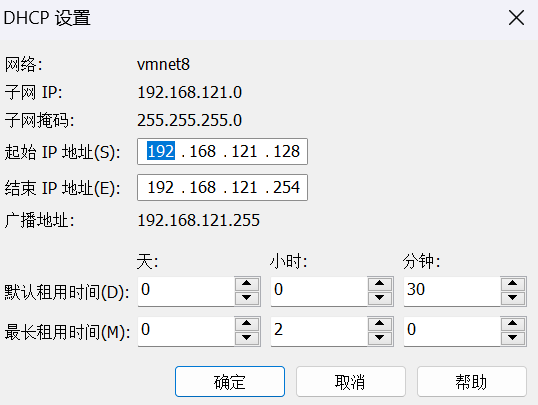
5)更改DHCP设置
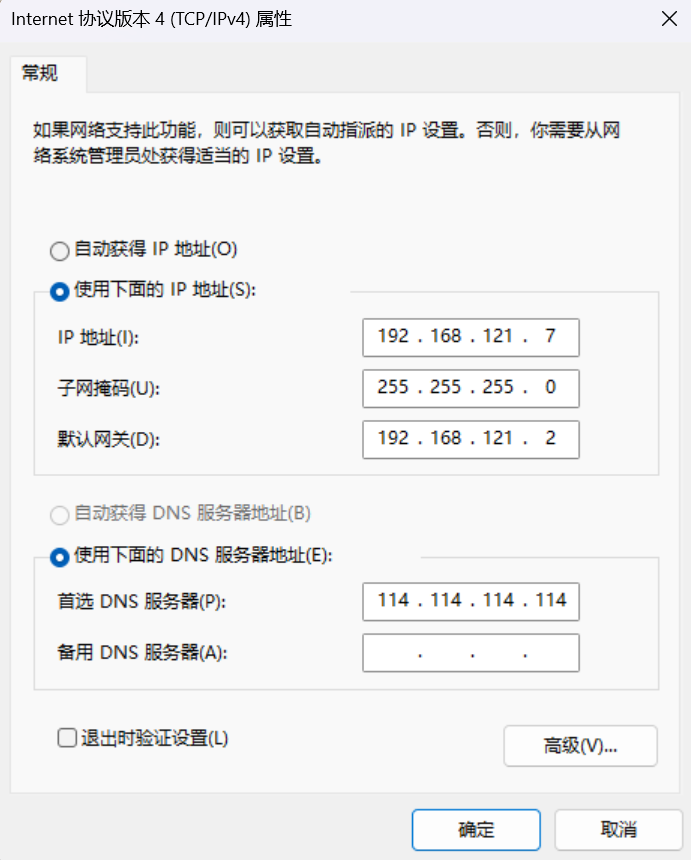
6)设置本机网络
控制面板->网络和Internet->网络和共享中心->更多适配器设置->VMware->属性->ipv4->配置
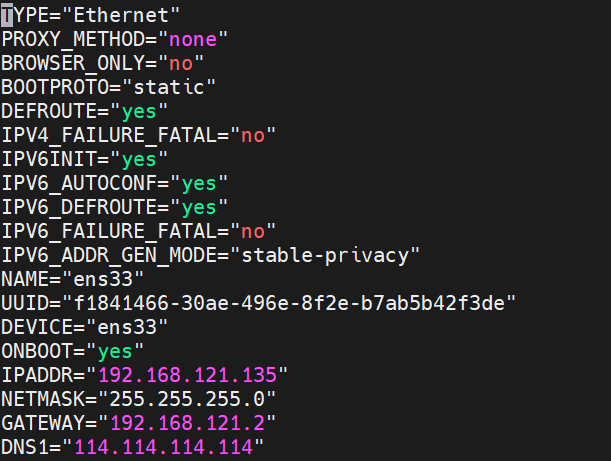
7)修改静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改BOOTPROTO和ONBOOT属性,增加以下IP设置
8)重启虚拟机,测试网络是否OK
reboot
ping www.baidu.com
3.安装JDK
1)下载安装SSH远程连接工具MobaXtem_Portable
通过ssh远程连接192.168.121.134
2)创建后点击等待后输入密码成功登录,cd进入/export/software目录下将jdk压缩包放入
3)解压
tar zxvf jdk-8u65-linux-x64.tar.gz
4)移动解压后的文件夹至server(这里用的相对路径,其它路径可能并没有出现在server下)
mv jdk1.8.0_65 ../server
5)修改profile文件(关于编辑文件的,vim可能显示命令not found,所以改用vi)
vi /etc/profile
6)在结尾位置增加语句(G跳转最后一行,按“i"进入输入模式,如果输出了,可以esc+:q!这样退出不保存)
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
(第一行是你jdk存放的地址,但有时候你后面配置完成后java -version显示not found,本人这里查错是改成绝对路径/root/export/server/jdk1.8.0_65就正常了)
加入后esc+:wq保存退出
6)重新加载环境变量文件
source /etc/profile
7)验证java环境
java -version

4.自检yum镜像(多半要改成国内)
一般会出现cannot find a valid baseurl for repo:base/7/x86_64情况
解决方法:改用国内镜像
vi /etc/yum.repos.d/CentOS-Base.repo
将原有内容删除,替换为以下内容
[base]
name=CentOS-$releasever - Base - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[updates]
name=CentOS-$releasever - Updates - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[extras]
name=CentOS-$releasever - Extras - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
[centosplus]
name=CentOS-$releasever - Plus - mirrors.aliyun.com
baseurl=http://mirrors.aliyun.com/centos/$releasever/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
清理并重建缓存
sudo yum clean all
sudo yum makecache
sudo yum update
5.配置ip映射
打开hosts文件,增加自己ip
vi /etc/hosts

6.用虚拟机”完整克隆“方式克隆node2,node3,并更改另外两个的ip(即ifcfg-ens33文件,因为克隆出来的ip与原虚拟机ip一样)
顺手配置主机名
vi /etc/hostname
#分别更改为node1 node2 node3
此时在node1上ping node2应该可以
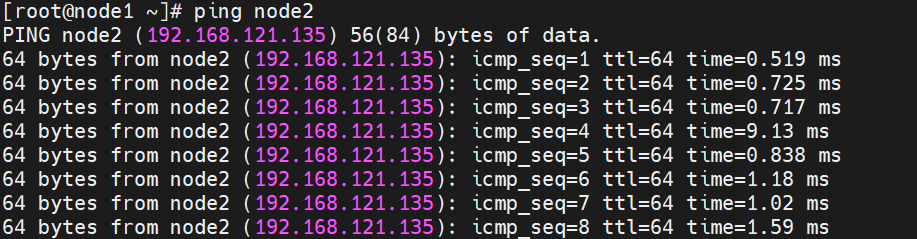
7.ssh服务配置
1)确认ssh服务开启
ps -e | grep sshd
2)三台机器生成公钥私钥
ssh-keygen -t rsa
3)拷贝公钥到另外两台机器
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
4)测试
在node1上输入ssh node2,能够免密登录然后exit退出回来node1
二、Hadoop配置
1.按照安装jdk方式,放置software文件夹后解压,再移置到server文件夹
tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
mv hadoop-3.3.0 ../server
(这里还是相对路径,/export/server似乎并不好用)
2.Linux 关闭防火墙和安全限制、
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vi /etc/selinux/config
#将SELINUX=disable
3.设置时间服务器、更新时间
ntpdate cn.ntp.org.cn
systemctl start ntpd
systemctl enable ntpd
如果提示 没有ntpd服务:yum install ntp -y 进行安装
4.配置hadoop环境变量
echo 'export HADOOP_HOME=/root/export/server/hadoop-3.3.0' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
(这里用的绝对路径,直接/export/server/hadoop-3.3.0可能并不好用)
可以用hadoop version用来检测
5.修改配置文件
#进入hadoop
cd /root/export/server/hadoop-3.3.0/etc/hadoop
以下操作一般并没有出错的地方,顾此处简略说明
1)修改 hadoop-env.sh :
修改 hadoop-env.sh :
# 首先要配置JDK,Java运行环境
export JAVA_HOME=/root/export/server/jdk1.8.0_65
# 以上配置完成后,在文件最后在添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2)修改 core-site.xml :
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
新代码插入中间
3)修改 hdfs-site.xml:
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
4)修改 mapred-site.xml :
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
5)修改yarn-zite.xml :
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
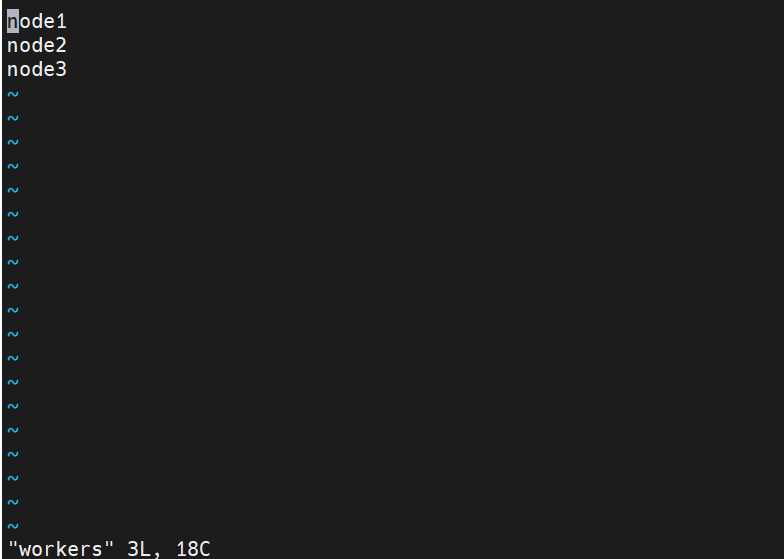
6.修改 workers :(默认localhost 删掉)
vi workers(此时应注意在hadoop目录下)
新增:
node1
node2
node3
7.将集群主节点的配置文件分发到其他子节点
同步(目录转发)给其他两个节点(node1):
在server下:
scp -r hadoop-3.3.0 root@node2:/root/export/server/
scp -r hadoop-3.3.0 root@node3:/root/export/server/
8.格式化文件系统
在主节点上初始化 namenode :
hdfs namenode -format
9.启动hadoop集群
start-all.sh
10.本地机修改hosts
位置:C:\Windows\System32\drivers\etc下
本地机修改hosts:
192.168.121.134 node1
192.168.121.135 node2
192.168.121.136 node3
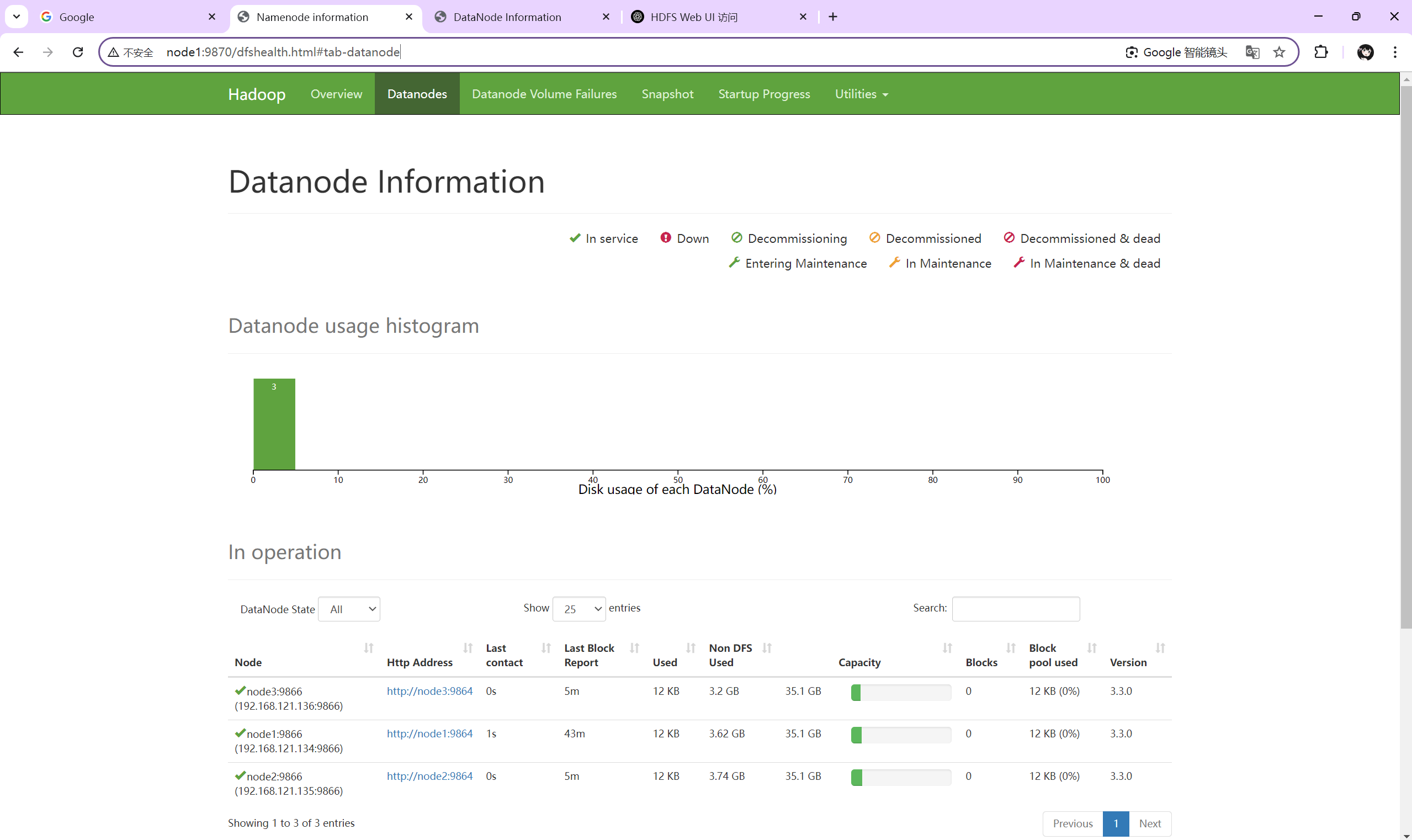
11.访问网址
分别访问:
node1:9870 (HDFS服务访问:namenode服务所在的服务器)
node1:8088(Yarn服务访问:正在计算的任务状态&日志,resourcemanager所在的服务器)
最终效果
参考:
指导teacher—大可tchr
CSDN小飞飞V5—https://blog.csdn.net/weixin_63721954/article/details/130792569?fromshare=blogdetail&sharetype=blogdetail&sharerId=130792569&sharerefer=PC&sharesource=m0_74014989&sharefrom=from_link


















 2405
2405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









