




在这里,作为补充知识,为大家讲一下R语言怎么对数据进行分析。现目前,对于我们而言,选择一所合适的大学非常重要,针对于此,我对影响大学平均录取分数线因素进行了分析。
首先我们看看文件里面有些什么属性
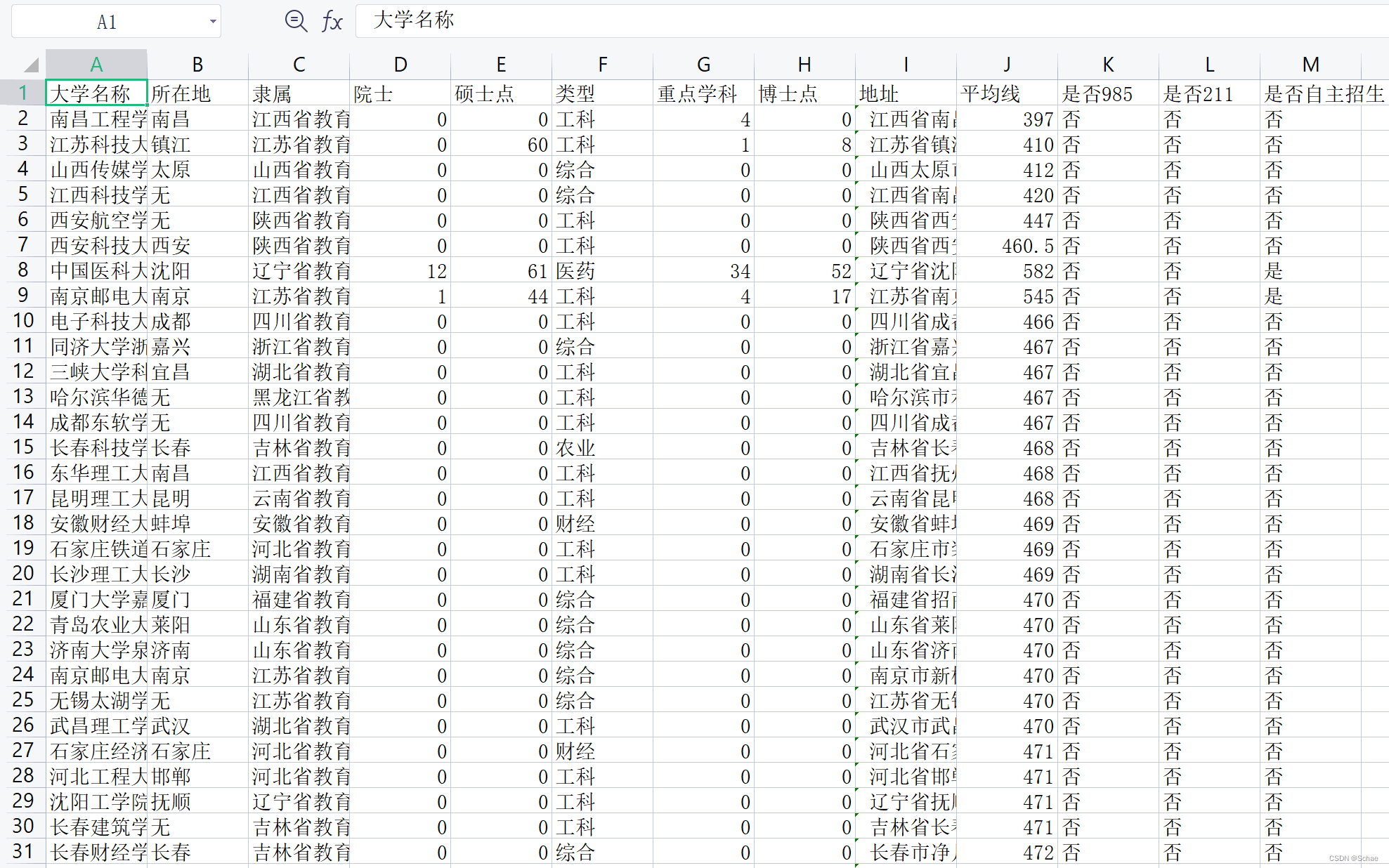
然后我们进行读取文件
x<-read.csv("C:/Users/chaeli/Documents/chapter3-data/data/ch11data.csv",head=T)
x
将有录取平均线的院校作为训练样本集
train<-x[which(x$平均线!="无"),]
train
将没有录取平均线的院校作为验证集
test<-x[which(x$平均线=="无"),]
test
将训练样本集中的平均线转换为数值型
train$平均线<-as.numeric(as.character(train$平均线))
查看训练样本集中的平均线情况
summary(train$平均线)
各录取平均线院校的数量,横轴为录取平均分,纵轴为院校的数量
a<-as.data.frame(table(train$平均线))
plot(a,xlab="录取平均分",ylab="院校的数量")
绘制院校的分布柱状图,学习训练集中的不同类型院校的数量
b<-as.data.frame(table(train$类型))
barplot(b$Freq,names.arg=b$Var1,col=rainbow(12),xlab="院校类型",ylab="院校的数量",main="院校分布")
将学校按照985和非985进行分类,并绘制分布柱状图
c<-as.data.frame(table(x$是否985))
barplot(c$Freq,names.arg=c$Var1,xlab="是否为985院校",ylab="院校的数量")
将院校重点学科数量绘制成散点图
d1<-as.data.frame(table(x$重点学科))
plo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2064
2064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









