






首先通过Spark读取本地的CSV文件,该文件中的内容是由Python爬虫得到
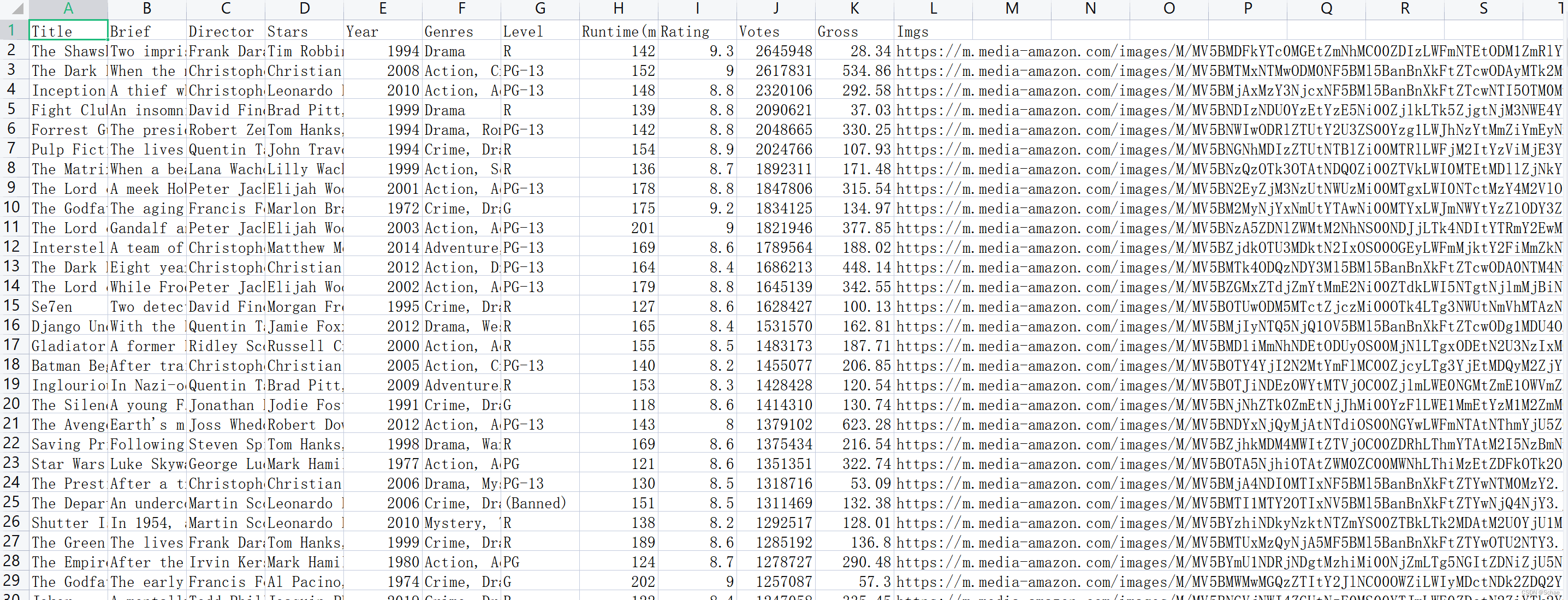
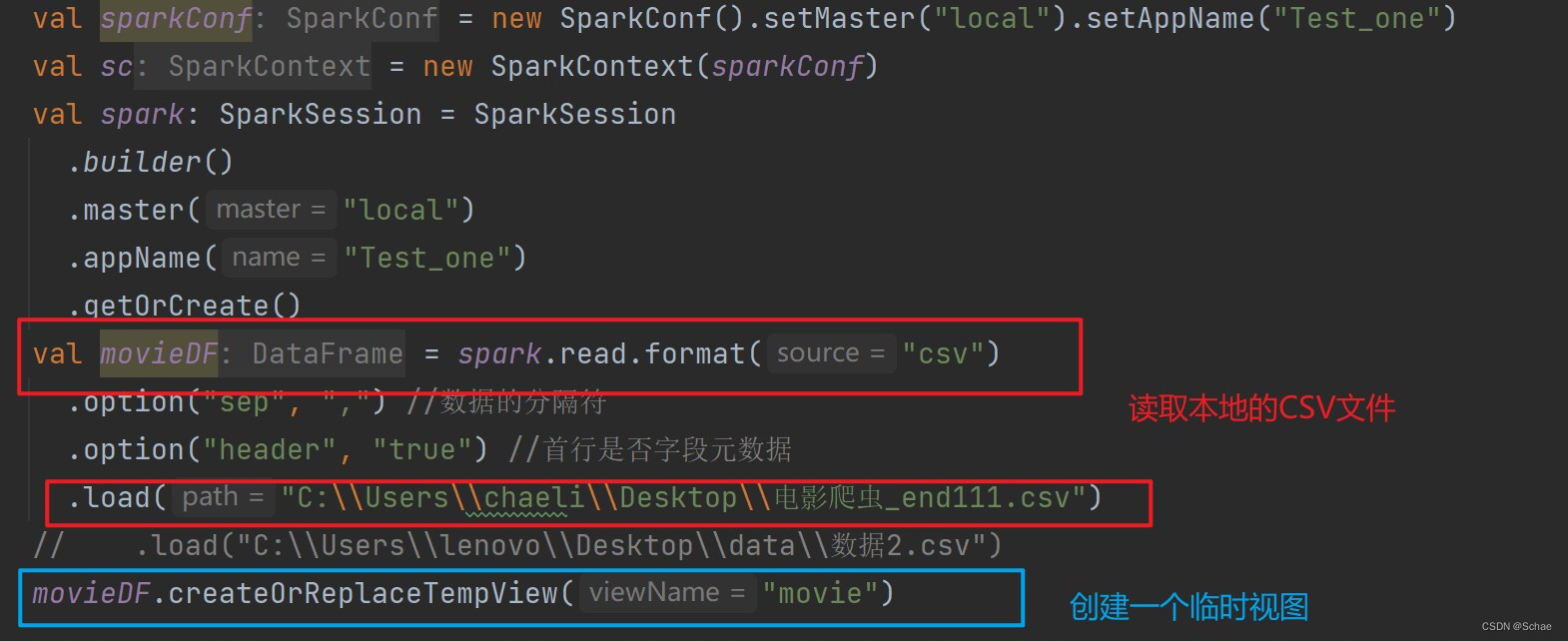 然后对其中相关的数据进行分析,例如电影类型分析、电影导演出现次数前十、电影主演次数出现前十、电影年代分布以及各类型平均票房等。
然后对其中相关的数据进行分析,例如电影类型分析、电影导演出现次数前十、电影主演次数出现前十、电影年代分布以及各类型平均票房等。
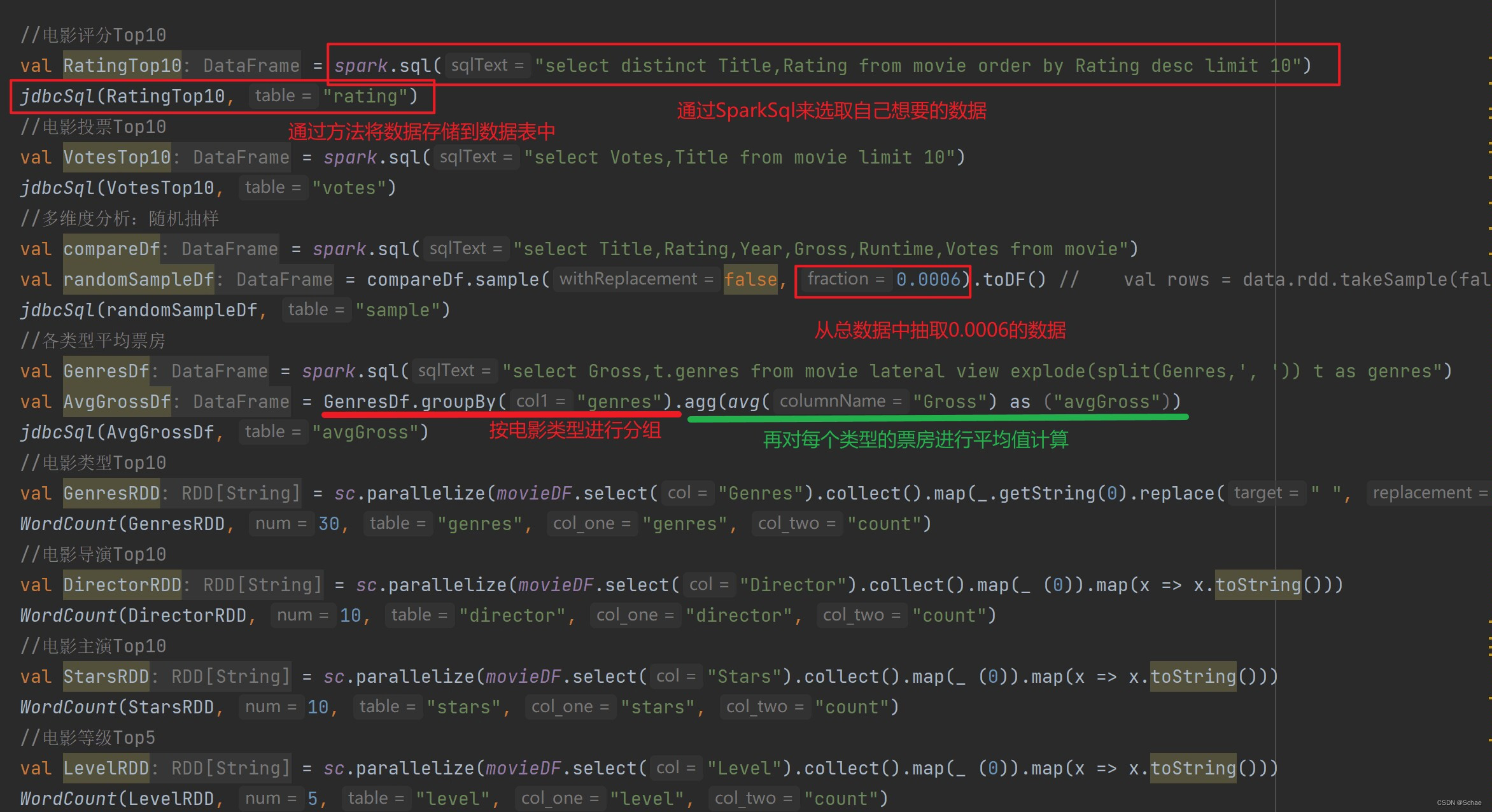
并将这些分析处理的结果写入到数据库对应的表当中。

对于出现次数需要进行相应的词频统计。 
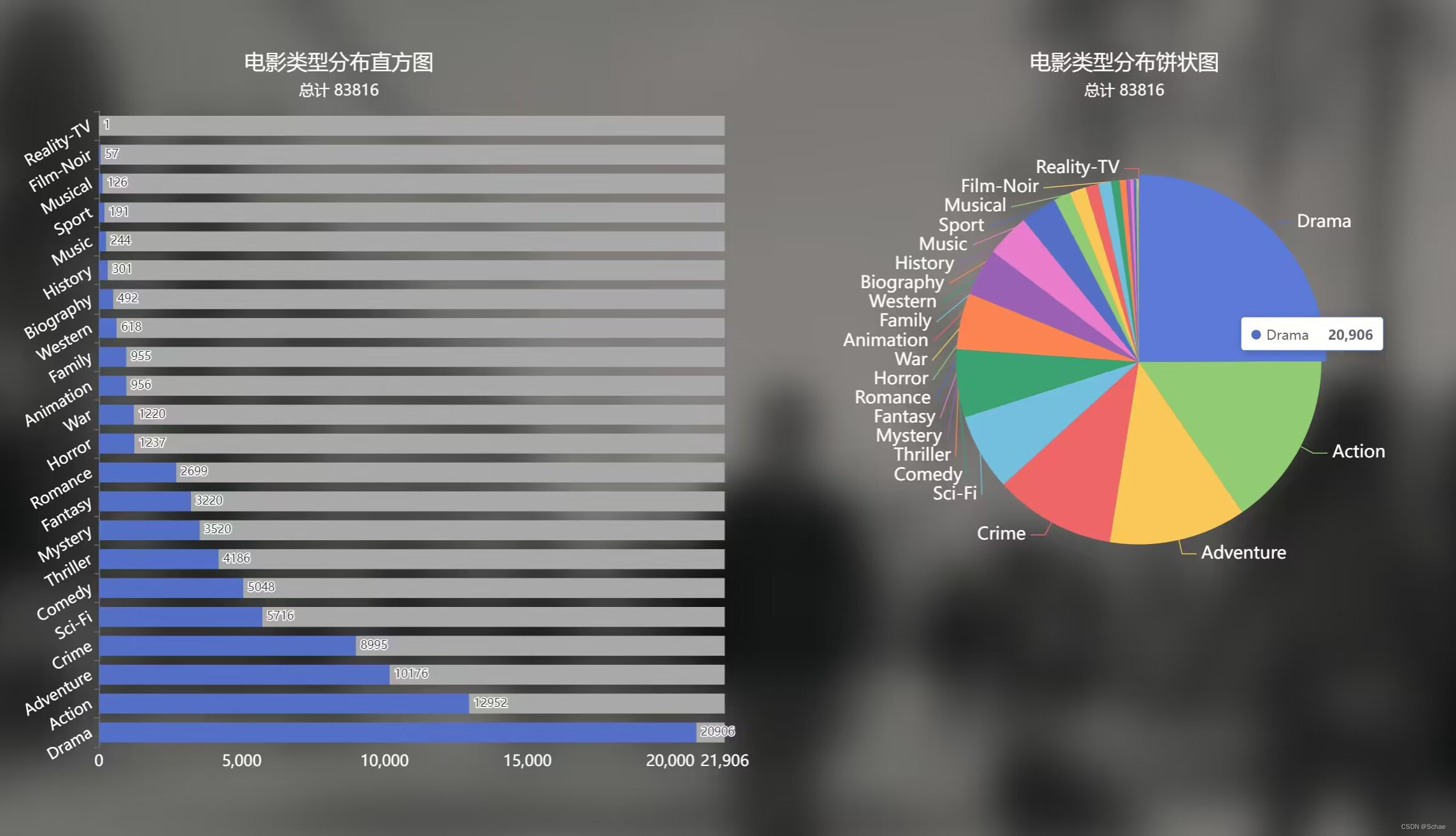
此处以电影类型对应电影出现次数进行举例,以下是存入数据库的数据。
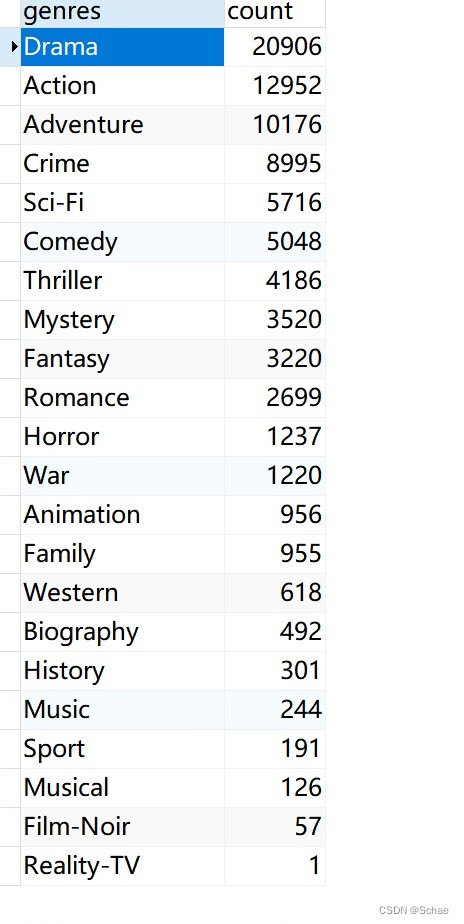
然后我们通过后端去读取该表的数据,首先创建一个实体类Genres。
接着我们在mapper层创建GenreMapper去拿取实体类数据。
接着,在服务层service去调用mapper层中的方法。

最后,在控制层controller中去调用服务层的方法。
通过postman去看是否能拿到理想的值。
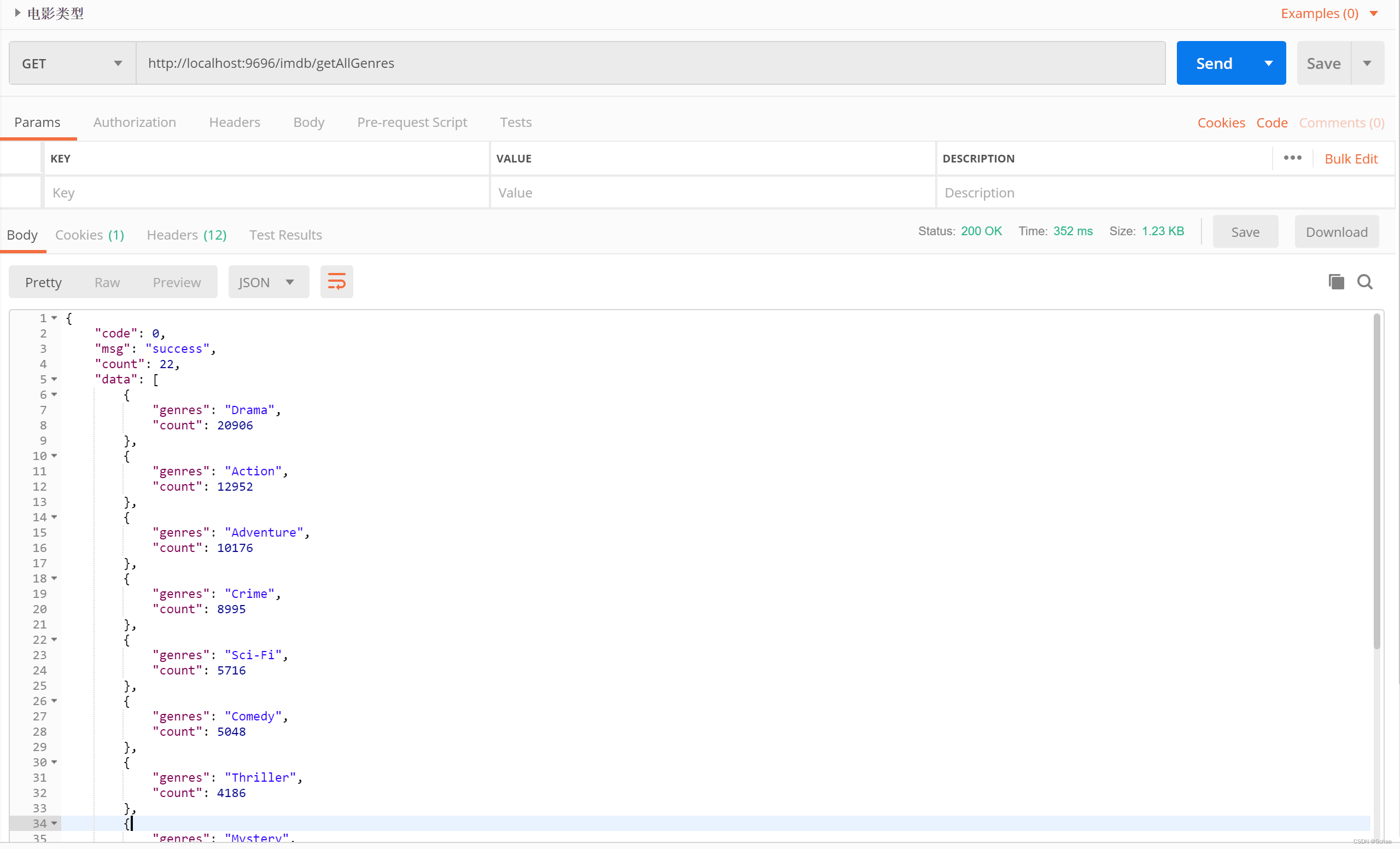
说明获取值成功,但是我还想将结果通过Vue+Echarts展示出来,就还要在前端去获取相应的值。
首先,设定一个容器,来保证图表能够正常的显示。

然后,局部引入Echarts工具。
通过调用后端的接口,传入对应的值。
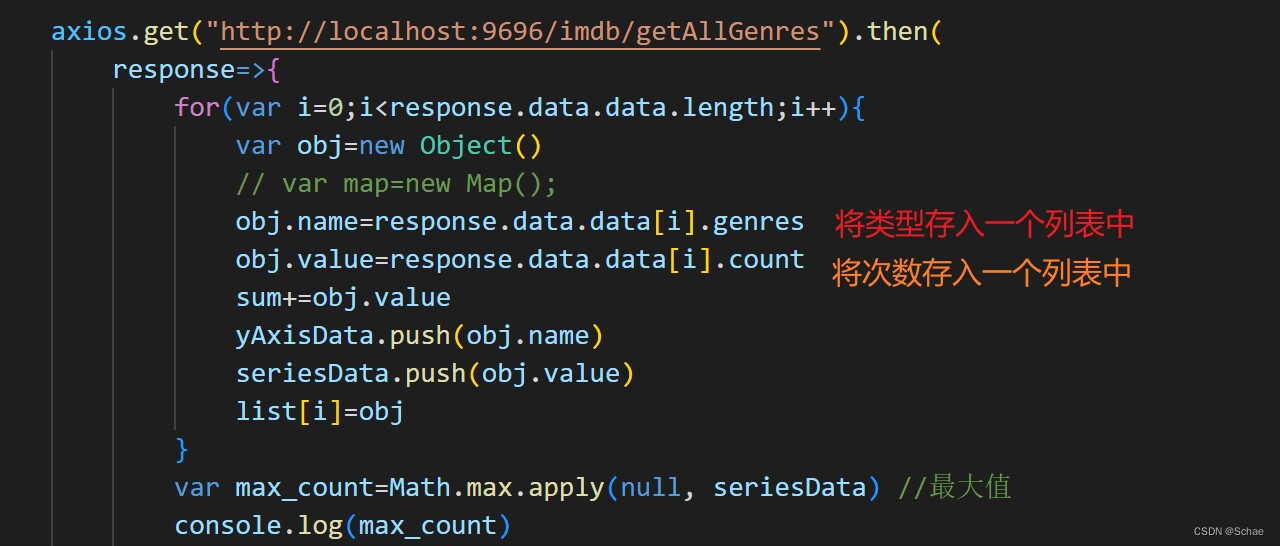
最后重写方法,将刚才的列表赋值给data即可,最终就可以显示出来。















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









