






Zookeeper的安装与配置
文章目录
Zookeeper概述
功能:
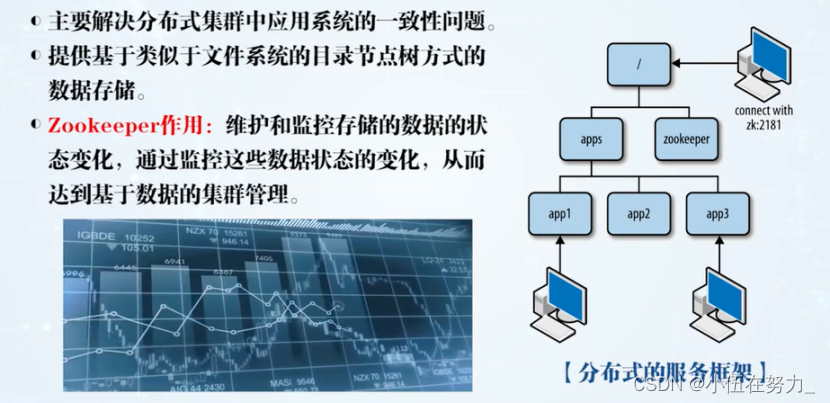
Zookeeper = 文件系统+通知机制
角色介绍:
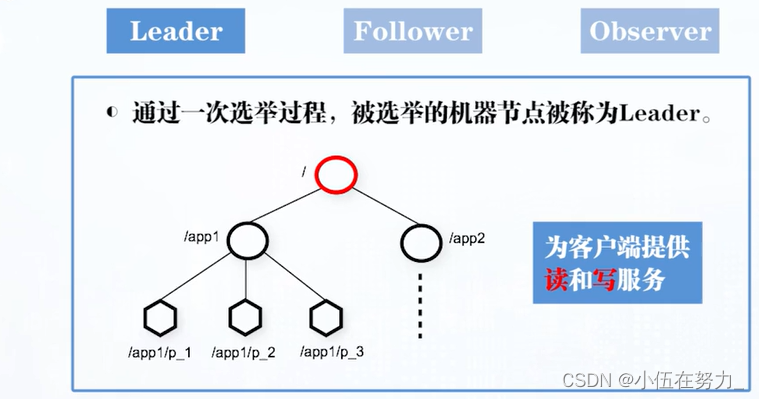
Leader作用:
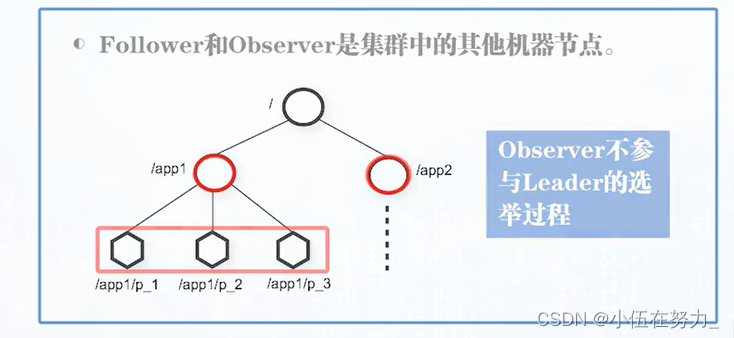
Follower 作用:




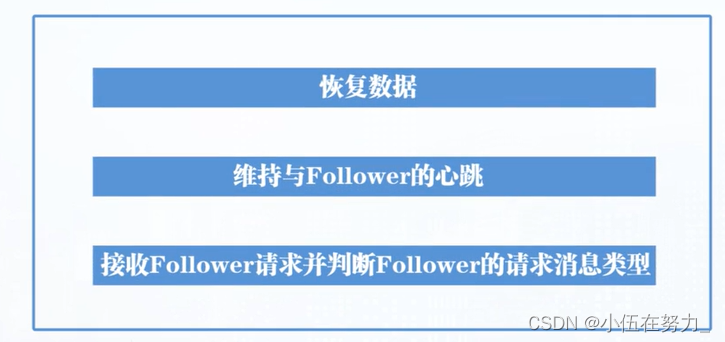
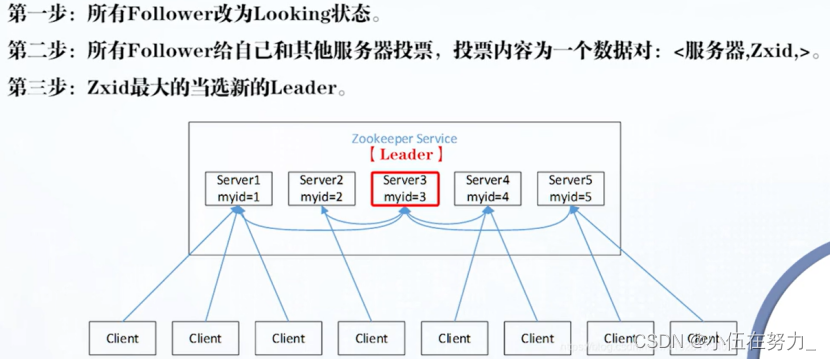
选举Leader过程:
先给自己投,后面myid高投后者,票数过半,当选
3.2 Zookeeper安装(所有机器都要)
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、使用步骤
1.准备将windows系统中的zookeeper上传到/opt/soft:
cd /opt/soft #由于之前创建过了这里直接切换到/opt/soft目录
2.点击上传按钮,将zookeeper上传
3.将zookeeper安装到特定的目录下面:
mkdir -p /usr/zookeeper #创建一个目录用来安装zookeeper
4.安装:
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/zookeeper
3.3 Zookeeper配置(所有机器都需要)
1.切换到相关目录
cd /usr/zookeeper/ zookeeper-3.4.10/conf #接下来的步骤我们在这个目录下进行
2.ls #查看该目录下面有什么
3.我们需要配置文件,但是从“ls”可知,只给了我们一个模板,需要我们复制一份,然后再配置文件
4.cp zoo_sample.cfg zoo.cfg
#zoo.cfg是它的新名字,内容和zoo_sample.cfg一样
5.编辑zoo.cfg
vi zoo.cfg
改为
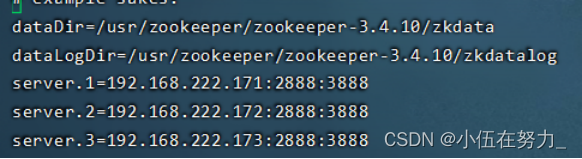

6.返回上一级位置
cd …
7.创建我们在第5步要创建的文件
mkdir zkdata
mkdir zkdatalog
8.进入到zkdata目录下创建一个新文件并编辑它
cd zkdata
vi myid
编辑的内容和虚拟机有关系,如果是master,里面写入1,如果是slave1里面写入2,如果是slave2,里面写入3,如果是masterbak,里面写入4.
9.接下来我们还要配置另外两台虚拟机,为了方便,我们直接远用scp,将master的zookeeper整个文件夹远程拷贝给slave1,slave2,masterbak,这样就不需要配置了
scp -r /usr/zookeeper root@slave1:/usr #这里考的是文件夹所以是scp -r 命令
scp -r /usr/zookeeper root@slave2:/usr #同样拷一份到slave2中去
scp -r /usr/zookeeper root@masterbak:/usr
10.拷贝过来的内容仍然需要做一些修改
到slave1中
cd /usr/zookeeper/zookeeper-3.4.10/zkdata #切换到该目录下
11.对myid 文件中的内容进行修改,因为不同的虚拟机,里面的内容不一样
vi myid
将里面的内容改为2
12.slave2同上10,11步骤,不同的是myid文件中,内容改为3
13.masterbak 同上
配置zookeeper的环境变量(所有都需要)
1.进入到指定的文件夹
vi /etc/profile
zookeeper的环境变量放在Java的环境变量下面
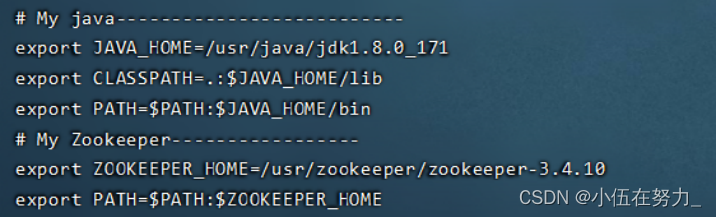
2.使环境变量生效
source /etc/profile
3.运行zookeeper
必须在zookeeper安装目录下
cd /usr/zookeeper/zookeeper-3.4.10
bin/zkServer.sh start #这一步必须所有机器同时运行

可能会出现错误:关闭防火墙再看状态即可(systemctl stop firewalld)
bin/zkServer.sh status #这一步选出谁是领导者谁是跟随者
3.4 Zookeeper运行
Zookeeper的文件系统
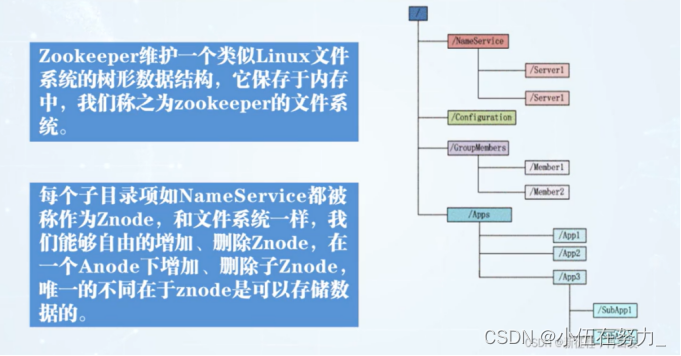
Zookeeper的数据同步的特点

Zookeeper的数据广播
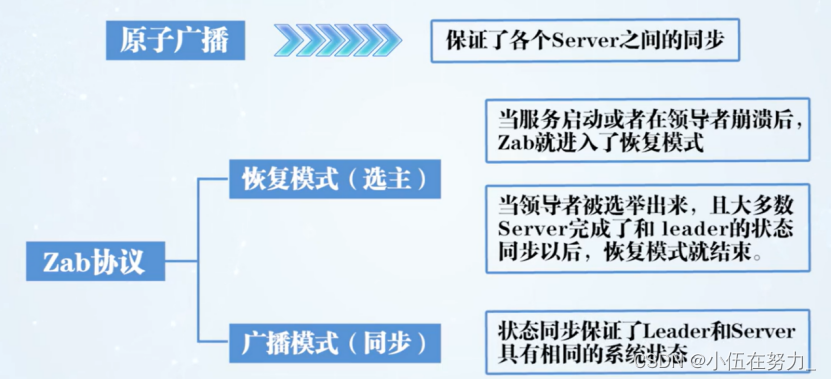


Zookeeper的重新选举


崩溃恢复:



服务器端口应对应该虚拟机的主机号,最后的端口对应原 conf 下 zoo.cfg 文件中所带的 Cli 端口,否则拒绝连接
即在 master(192.168.222.171)下应为
bin/zkCli.sh -timeout 5000 -r -server 192.168.222.171:2181


节点的创建和查看

get path:获取指定节点的内容【数据信息】
ls2 path:列出path节点的子节点及状态信息















 4115
4115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











