






Elasticsearch
简介
Elasticsearch是一个开源的分布式搜索和分析引擎,Elasticsearch提供了丰富的分析功能,包括聚合、过滤、排序等,可以对数据进行深入分析和挖掘。
下载与启动
下载地址
注:下载路径不要有中文或者空格,会报错。
配置中文分词器
下载地址
找到下载的对应版本的中文分词器并下载。
下载后解压到Elasticsearch的plugins路径中,路径如下
运行bin目录下的elasticsearch.bat启动Elasticsearch
Elasticsearch客户端
下载Kibana作为访问Elasticsearch的客户端
下载路径:https://artifacts.elastic.co/downloads/kibana/kibana-7.17.5-windows-x86_64.zip
注:下载其他版本修改路径中的版本号即可
成功启动Elasticsearch后去kibana的bin目录下启动kibana.bat
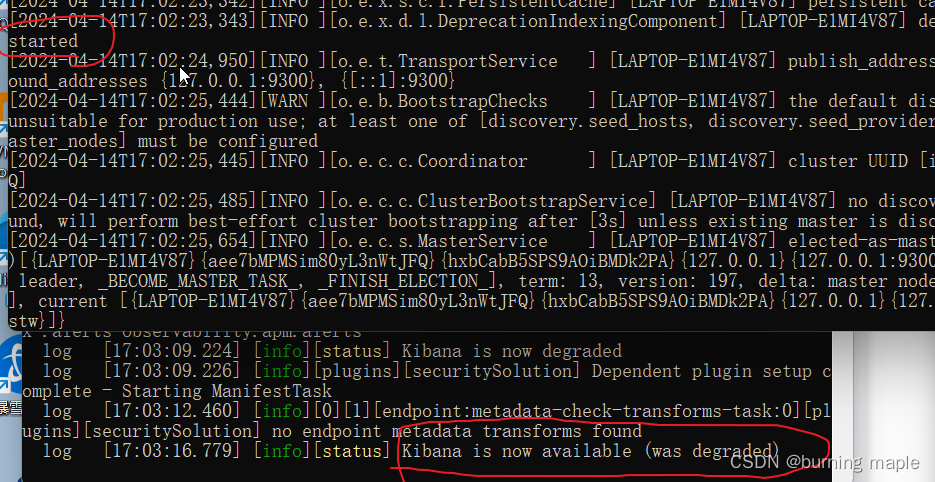
运行成功后访问http://localhost:5601即可进入客户端
相关概念
索引(Index):在Elasticsearch中,索引是存储相关文档的地方,类似于关系型数据库中的数据库。每个索引都有一个唯一的名称,用于标识和检索其中的文档。
文档(Document):文档是索引中的基本单位,它是一个JSON格式的数据对象。在Elasticsearch中,每个文档都有一个唯一的ID,用于唯一标识和检索。
类型(Type):在较早的版本中,Elasticsearch允许在索引中定义多个类型来组织文档。但从Elasticsearch 7.0版本开始,类型已经被弃用,一个索引只能包含一个类型。文档的结构由文档的字段定义。
分片(Shard):为了实现水平扩展和提高性能,Elasticsearch将索引划分为多个分片,每个分片都是一个独立的Lucene索引。分片可以分布在集群的不同节点上,从而提高了搜索和存储的并行性。
副本(Replica):为了提高可用性和容错能力,Elasticsearch允许为每个分片创建零个或多个副本。副本是分片的精确复制品,可以在集群中的不同节点上存储,以防止数据丢失或节点故障。
节点(Node):节点是集群中的单个实例,负责存储数据、处理搜索请求和执行集群管理任务。一个Elasticsearch集群可以包含一个或多个节点,节点可以加入或离开集群而不会中断服务。
集群(Cluster):集群是一组相互连接的节点,共同承载和处理数据。所有节点都通过集群名称进行标识,它们共享索引和搜索请求,并协同工作以保持集群的健康状态。
搜索请求(Search Request):搜索请求是向Elasticsearch发送的查询请求,可以包含各种查询条件和过滤器,以便搜索并返回匹配的文档
操作ES

进入devTools操作es
创建索引:
PUT /my_index
{
“settings”: {
“number_of_shards”: 1,
“number_of_replicas”: 0
}
}
索引文档:
PUT /my_index/_doc/1
{
“name”: “John Doe”,
“age”: 30,
“email”: “john@example.com”
}
获取文档:
GET /my_index/_doc/1
搜索文档:
json
Copy code
GET /my_index/_search
{
“query”: {
“match”: {
“name”: “John”
}
}
}
更新文档:
POST /my_index/_update/1
{
“doc”: {
“age”: 31
}
}
删除文档:
DELETE /my_index/_doc/1
删除索引:
DELETE /my_index
获取集群健康状态:
GET /_cluster/health
获取索引信息:
GET /my_index/_settings
查看节点信息:
GET /_cat/nodes?v
查看索引列表:
GET /_cat/indices?v
查看分片状态:
GET /_cat/shards?v
精确匹配(Match):匹配指定字段中包含特定值的文档。
GET /my_index/_search
{
“query”: {
“match”: {
“name”: “John”
}
}
}
多字段匹配(Multi-Match):在多个字段中搜索匹配的文档。
GET /my_index/_search
{
“query”: {
“multi_match”: {
“query”: “John”,
“fields”: [“name”, “email”]
}
}
}
范围查询(Range):查询指定字段值在某个范围内的文档。
json
Copy code
GET /my_index/_search
{
“query”: {
“range”: {
“age”: {
“gte”: 20,
“lte”: 40
}
}
}
}
存在性查询(Exists):查询指定字段存在或不存在的文档。
GET /my_index/_search
{
“query”: {
“exists”: {
“field”: “email”
}
}
}
通配符查询(Wildcard):使用通配符匹配字段值。
GET /my_index/_search
{
“query”: {
“wildcard”: {
“name”: “J*”
}
}
}
正则表达式查询(Regexp):使用正则表达式匹配字段值。
GET /my_index/_search
{
“query”: {
“regexp”: {
“name”: “J.*”
}
}
}
模糊查询(Fuzzy):模糊匹配字段值。
GET /my_index/_search
{
“query”: {
“fuzzy”: {
“name”: {
“value”: “Jon”,
“fuzziness”: “AUTO”
}
}
}
}
全文搜索(Full-Text Search):在指定字段中进行全文搜索。
GET /my_index/_search
{
“query”: {
“match”: {
“content”: “Elasticsearch tutorial”
}
}
}
聚合查询(Aggregation):聚合查询允许对文档集合执行各种分析,例如计算统计数据、分组数据、计算平均值、求和等。以下是一个示例,显示了如何计算某个字段的平均值:
GET /my_index/_search
{
“aggs”: {
“avg_age”: {
“avg”: {
“field”: “age”
}
}
}
}
这将返回指定字段(例如"age"字段)的平均值。
复合查询(Compound Queries):复合查询允许将多个查询组合在一起,并指定它们之间的关系,例如逻辑与、或、非。以下是一个示例,显示了如何使用布尔查询(bool query)来执行逻辑与操作:
GET /my_index/_search
{
“query”: {
“bool”: {
“must”: [
{ “match”: { “name”: “John” }},
{ “range”: { “age”: { “gte”: 20, “lte”: 40 }}}
]
}
}
}
这将返回名字为"John"且年龄在20到40岁之间的文档。
Spring Data Elasticsearch
Spring Data Elasticsearch是Spring提供的一种以Spring Data风格来操作数据存储的方式,它可以避免编写大量的样板代码
添加依赖
<!--Elasticsearch相关依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch<artifactId>
</dependency>
SpringBoot配置
data:
elasticsearch:
repositories:
enabled: true
cluster-nodes: 127.0.0.1:9300 # es的连接地址及端口号
cluster-name: elasticsearch # es集群的名称
常用注解
@Document:
用于将Java类映射到Elasticsearch文档。
可以用于在Java类上指定索引、类型和映射。
参数:indexName: 指定了将Java类映射到的Elasticsearch索引的名称
@Id:
用于指定Java类中用作文档ID的字段。
必须放置在类字段上,并且字段类型必须是String。
@Field:
用于指定Java类中的字段与Elasticsearch文档字段之间的映射关系。
可以用于指定字段类型、存储选项等。
@Field(type = FieldType.Text, store = true):
type: 指定了字段的数据类型,例如文本、数字、日期等。在这个例子中,FieldType.Text 表示这个字段的类型是文本类型。
store: 指定了是否在 Elasticsearch 中存储这个字段的原始值。
数据操作
自定义接口继承ElasticsearchRepository接口可以获得常用的数据操作方法
ElasticsearchRepository接口中的两个泛型第一个填所选索引的文档类型(@Document注解修饰的类)第二个填文档类型的id类型
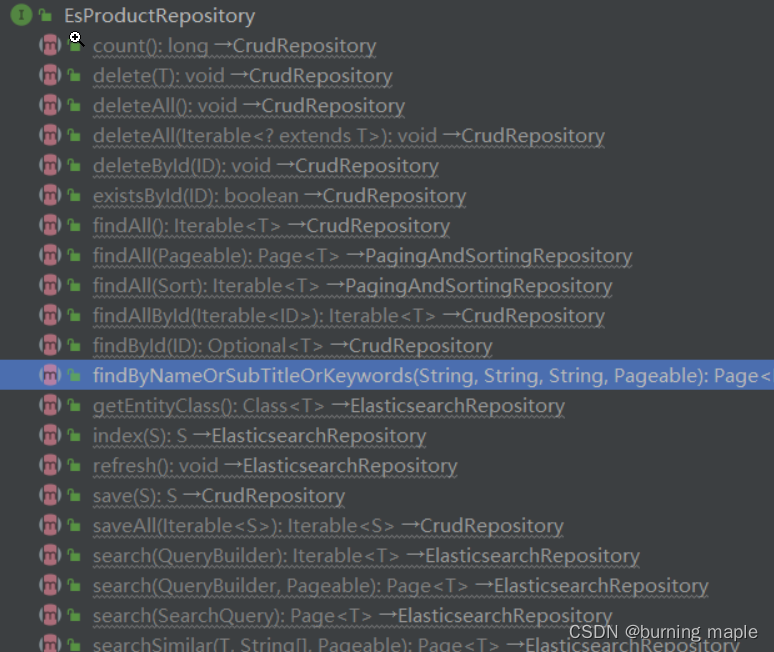
还可以使用衍生查询来自定义方法实现多条件查询
也可以使用Query注解编写es语句进行查询
@Query("{\"bool\": {\"must\": [{\"match\": {\"name\": \"?0\"}}]}}")
List<MyDocument> findByName(String name);
之后再编写接口时只需注入继承了ElasticsearchRepository接口的接口即可调用其中的基础方法和衍生方法操作Elasticsearch了















 1587
1587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









