






KNN算法概述
问题
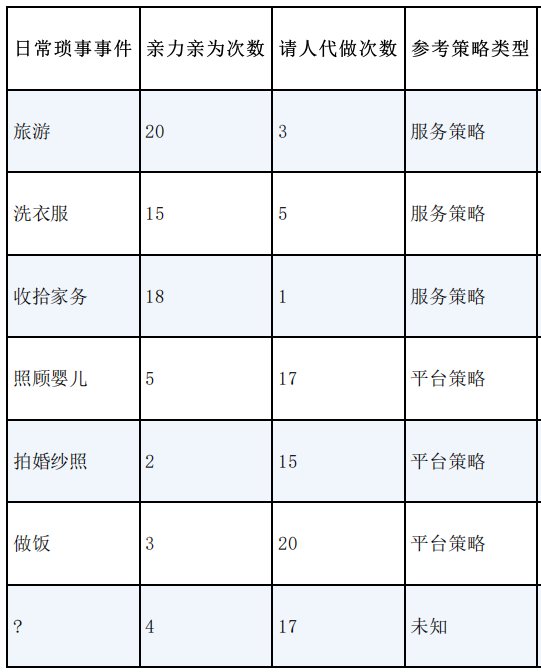
计算新事件与数据集的距离,来划分为是什么策略
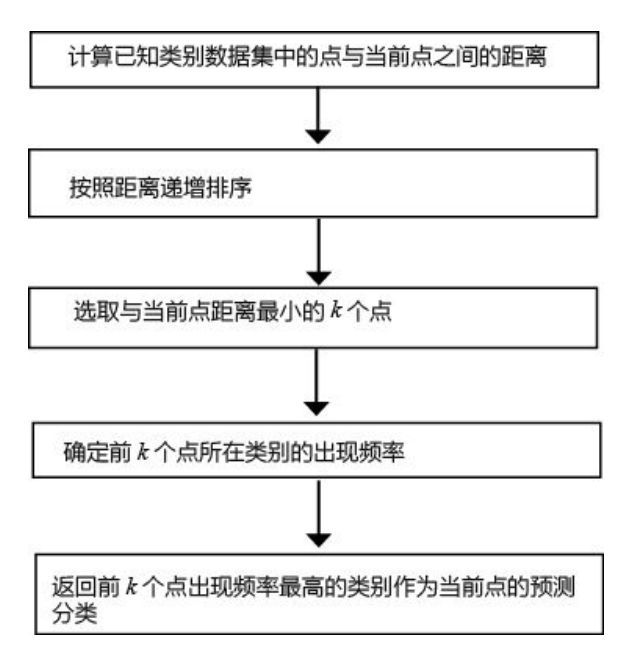
流程图
代码与运行结果
用的是Jupyter 来写,每一步可视化比较方便看结果
from numpy import *
import operator
import matplotlib.pyplot as plt
def createDataSet(): #创建数据集
group=array([[20,3],[15,5],[18,1],[5,17],[2,15],[3,20]])
labels=["服务策略","服务策略","服务策略","平台策略","平台策略","平台策略"]
return group,labels
if __name__=="__main__":
group,labels=createDataSet()
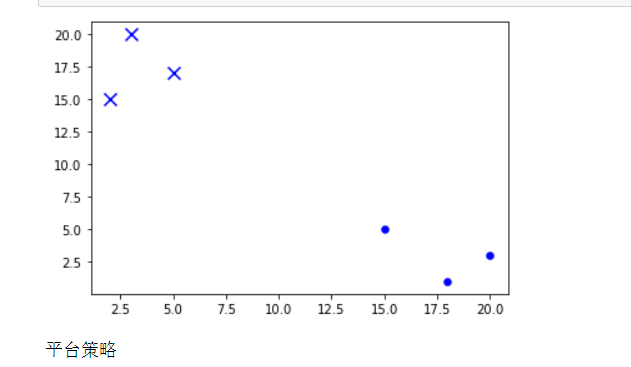
x=[item[0]for item in group[:3]] #列表推导式 item 是点(x,y)列表,item[0]获取x坐标
y=[item[1]for item in group[:3]] #列表推导式是 Python 中一种强大的工具,可以用于快速生成和转换列表,使代码更简洁易读。
plt.scatter(x,y,s=30,c="b",marker="o") #创建散点图
x=[item[0]for item in group[3:6]]
y=[item[1]for item in group[3:6]]
plt.scatter(x,y,s=100,c="b",marker="x")
plt.show()
a=classify([4,17],group,labels,3)
print(a)
#knn算法
def classify(in_x,datas,labels,k):
data_size=datas.shape[0] #获取数据行数
diff_mat=tile(in_x,(data_size,1))-datas #输入x复制,与原数据集相减
sqrt_diff=diff_mat**2 #计算输入数据与每个数据集中的数据点之间的差值。 这里自动计算x^2 , y^2 相当于已经减了原数据,只不过分步算
sub_distances=sqrt_diff.sum(axis=1) #第一维度1是行 第二维度0是列 这是按照行加和
distances=sub_distances**0.5
sorted_distances=distances.argsort() #返回的是原数组中元素按升序排列后的索引值数组 np.flipud(np.argsort(arr)) 沿着垂直方向翻转数组得到递减
class_count={} #创建空字典,存储每个类别的投票次数
for i in range(k):
votel_label=labels[sorted_distances[i]] #获取第i个邻居的标签
class_count[votel_label]=class_count.get(votel_label,0)+1 #字典中键 votel_label 对应的值,如果该键不存在,则返回默认值 0。
sorted_class_count=sorted(class_count.items(),key=operator.itemgetter(1),reverse=True)
#sort 默认递增 ,加了reverse=True 递减
#class_count.items() 将字典 class_count 转化为包含键值对的列表。
#key 按照投票次数排序。
return sorted_class_count[0][0] #返回最终分类结果
优点缺点
优点:
- 简单直观: KNN 是一种直观的算法,易于理解和实现。它不需要模型训练的过程,只需要记住数据。
- 无需训练: 不像一些其他机器学习算法需要花费大量时间在训练模型上,KNN 不需要显式的训练过程。
- 适用于多类别问题: KNN 在多类别问题上表现良好,尤其是在类别之间的决策边界不明显时。
- 适用于小数据集: 对于小型数据集而言,KNN 的计算效率通常较高。
- 对异常值不敏感: KNN 对异常值不太敏感,因为它是基于邻近的投票机制。
缺点:
- 计算开销大: 在预测时,需要计算未知点与所有已知点的距离,这可能在数据集较大时变得非常耗时。
- 存储空间大: 需要存储整个训练集,对于大型数据集来说,这可能占用较大的存储空间。
- 需要调参: 需要选择合适的邻居数 k,选择不当可能导致过拟合或欠拟合。
- 灵敏度高: 对输入数据的噪声和不相关特征敏感,可能导致不稳定的预测结果。
- 维度灾难: 在高维空间中,样本之间的距离变得模糊,KNN 的性能可能下降。
- 不适用于非度量空间: KNN 基于距离的度量,对于非度量空间(例如图像)可能不太适用。
总体而言,KNN 在一些特定场景下表现出色,但在大规模高维数据集上可能不是最佳选择。在实际应用中,需要根据问题的特点和数据集的规模来选择适当的算法。
项目
(暂时还未找到合适的项目学习) 到时候学到了再扩充















 2195
2195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









