







这篇论文《Single Image Deblurring Using Motion Density Functions》由 Ankit Gupta、Neel Joshi、C. Lawrence Zitnick、Michael Cohen 和 Brian Curless 合作完成,主要研究了一种新颖的单图像去模糊技术,用于估计由相机抖动引起的空间变化模糊。下面是对论文内容的解读:
摘要
- 论文提出了一种新的单图像去模糊方法,用于估计由相机抖动引起的空间非均匀模糊。
- 使用现有的空间不变去卷积方法以局部和鲁棒的方式计算潜在图像的初始估计。
- 相机运动通过运动密度函数(MDF)表示,记录了在所有可能的相机姿态空间的离散部分中花费的时间比例。
- 从MDF直接派生出空间变化的模糊核。
- 论文证明了6D相机运动可以通过3个自由度的运动(平面内平移和旋转)来很好地近似,并分析了这种近似的范围。
- 展示了在合成数据和捕获数据上的结果,系统性能超过了当前假设空间不变模糊的方法。
第1章:引言 (Introduction)
研究背景:
- 论文开篇介绍了由于相机抖动导致图像模糊的问题,这在长曝光摄影中尤为常见,例如在光线不足的环境下拍摄时。
- 作者指出,去除这种模糊是一个活跃的研究领域,尤其是在只有单张模糊图像可用的情况下,这一问题被称为盲去卷积。
研究挑战:
- 传统的去模糊方法通常假设模糊核是空间不变的,这限制了能够模拟的相机运动类型。然而,实际中的相机运动往往更为复杂,可能导致空间变化的模糊。
研究目标:
- 本文的目标是开发一种新的方法,能够处理由更一般的相机运动(包括2D平移和平面内旋转)引起的空间变化模糊。
- 作者提出了一种新颖的公式,通过运动密度函数(MDF)来描述相机抖动,从而恢复潜在图像和模糊核。
研究意义:
- 通过更准确地模拟相机运动,该方法有望提高去模糊的质量,尤其是在相机抖动引起的模糊核空间变化显著的情况下。
第2章:相关工作 (Related Work)
去模糊技术概述:
- 论文回顾了图像去模糊领域的研究进展,包括点扩散函数(PSF)估计和非盲图像去卷积的独立和联合解决方案。
现有方法的局限性:
- 许多现有方法基于空间不变模糊核的假设,这在实际应用中并不总是成立,因为实际相机运动可能更加复杂。
空间变化模糊的研究:
- 论文指出,相对较少的研究关注空间变化模糊的处理。例如,Tai等人的工作通过混合相机捕获高帧率视频和模糊图像来指导空间变化模糊核的计算,但这种方法受到混合相机需求的限制。
运动密度函数(MDF)的引入:
- 作者提出了一种新的方法,不直接恢复每个图像点的空间变化模糊核,而是通过MDF来模拟相机运动。MDF是一个在高维相机运动空间中的密度函数,可以用于在不知道运动曲线的时间顺序的情况下生成图像中任何位置的核。
与现有方法的比较:
- 与现有方法相比,本文提出的方法不直接恢复空间变化模糊核,而是恢复相机运动(即MDF),从而派生出模糊核。这种方法在理论上可以处理更广泛的相机运动情况,并且可能减少由于模糊核估计不准确而导致的伪影。
研究贡献:
- 论文的贡献在于提出了一种新的去模糊框架,该框架通过MDF来更好地模拟和恢复由相机抖动引起的模糊,特别是在模糊核空间变化显著的情况下。
第3章:统一的相机抖动模糊模型 (A Unified Camera Shake Blur Model)
3.1 图像模糊模型 (Image Blur Model)
论文在这一节中提出了一个数学模型来描述由于相机抖动导致图像模糊的过程。这里的关键公式是:
𝑏=𝑘⊗𝑙+𝑛b=k⊗l+n
这个公式表示记录的模糊图像 𝑏b 是潜在图像 𝑙l 与模糊核 𝑘k 的卷积结果加上噪声 𝑛n。作者假设噪声 𝑛n 是高斯分布的,即 𝑛∼𝑁(0,𝜎2)n∼N(0,σ2)。
为了便于处理空间变化的模糊,作者进一步将卷积模型转换为矩阵-向量形式:
𝐵=𝐾𝐿+𝑁B=KL+N
这里,𝐿L、𝐵B 和 𝑁N 分别是潜在图像 𝑙l、模糊图像 𝑏b 和噪声 𝑛n 的列向量形式。𝐾K 是一个图像过滤矩阵,每一行代表在每个像素位置上的模糊核,并展开成行向量。
3.2 模糊矩阵作为运动响应 (Blur Matrix as Motion Response)
在这一部分,作者提出了运动密度函数(MDF)的概念。MDF 是一个在相机姿态空间中的密度函数,记录了在曝光期间相机在每个离散姿态上花费的时间比例。MDF 可以用来直接确定图像中任何点的模糊核,而不需要知道运动曲线的时间顺序。
作者假设相机初始位于世界原点,并且其轴与世界轴对齐。相机运动可以表示为一个连续的路径,穿过6维的相机姿态空间。在离散化的空间中,相机在每个姿态上花费了一部分曝光时间,这个比例就是该姿态的密度。这些密度合在一起形成了MDF。
公式 (3) 显示了观察到的模糊图像 𝐵B 是相机在其路径上所有姿态看到的图像的积分:
𝐵=∑𝑗𝑎𝑗(𝐾𝑗𝐿)+𝑁B=∑jaj(KjL)+N
这里,𝐾𝑗Kj 是一个将原始姿态下的潜在图像 𝐿L 变换到姿态 𝑗j 下看到的图像的矩阵。𝑁N 是第3.1节中引入的噪声模型。
公式 (4) 定义了从深度 𝑑d 的正视场景到姿态 𝑗j 下的相机的单应性 𝑃𝑗Pj:
𝑃𝑗=𝐶(𝑅𝑗+1𝑑𝑡𝑗[001])𝐶−1Pj=C(Rj+d1tj[001])C−1
其中 𝑅𝑗Rj 和 𝑡𝑗tj 分别是姿态 𝑗j 的旋转矩阵和平移向量,𝐶C 是从图像EXIF标签中形成的相机内参矩阵。
公式 (5) 展示了如何将 𝐾𝑗Kj 组合成模糊矩阵 𝐾K:
𝐾=∑𝑗𝑎𝑗𝐾𝑗K=∑jajKj
这样,𝐾𝑗Kj 形成了一个基集,其元素可以使用MDF线性组合得到任何相机路径的相应模糊矩阵。
3.3 优化公式 (Optimization Formulation)
最后,作者提出了一个贝叶斯框架下的优化问题,以恢复最有可能的潜在图像和MDF。优化问题的目标是最小化以下能量函数:
𝐸=∥[∑𝑗𝑎𝑗𝐾𝑗]𝐿−𝐵∥2+prior(𝐿)+prior(𝐴)E=∥[∑jajKj]L−B∥2+prior(L)+prior(A)
这里,prior(𝐿)prior(L) 是潜在图像的全局图像先验,prior(𝐴)prior(A) 是MDF的先验。这些先验项帮助模型更好地恢复自然图像的特性和相机运动的连续性。
图片分析:
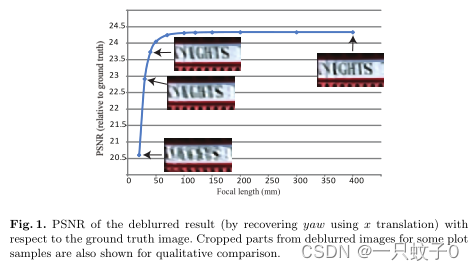
文中的图片,如图1,展示了使用不同焦距恢复偏航(yaw)运动时,去模糊结果的峰值信噪比(PSNR)与真实图像的比较。图中的曲线显示了随着焦距的增加,使用x平移来近似偏航运动的恢复效果趋于稳定,这验证了在较长焦距下,小的相机旋转可以近似为平移运动的假设。
整体而言,第3章通过数学建模和优化方法,为理解和解决由相机抖动引起的空间变化模糊问题提供了理论基础和解决方案。
第4章:形成运动响应基础 (Forming the Motion Response Basis)
4.1 场景深度的依赖性 (Dependence on Scene Depth)
- 论文指出,为了计算单应性矩阵 𝑃𝑗Pj 和相应的基础矩阵 𝐾𝑗Kj,需要知道场景的深度 𝑑d。然而,从单张图像中恢复场景深度是一个约束不足的问题。
- 作者提出了一种方法,通过假设场景深度是恒定的或正视的,可以不必知道确切的深度值。相反,可以将 1/𝑑𝑡𝑗1/dtj 视为一个单一的三维变量,从而消除对深度的依赖,只关注图像视差。
- 这种方法意味着系统自由度的数量不会改变,深度不是作为一个单独的变量需要考虑。
4.2 相机运动自由度的计算简化 (Computational Reduction in Degrees of Freedom for Camera Motion)
- 作者观察到,尽管理论上相机运动有6个自由度(3个旋转和3个平移),但实际上可以只用3个自由度(绕z轴的旋转即roll,以及x和y方向的平移)来近似。
- 这种简化使得问题在计算上更加可行,因为运动响应基础(MRB)的大小取决于自由度的数量。
- 通过实验验证,小的相机绕x轴(俯仰)和y轴(偏航)的旋转可以在透视效应最小的情况下近似为相机平移。这在大多数情况下是成立的,尤其是在较长的焦距下。
- 论文通过实验展示了这种近似的有效性,并通过图表展示了不同焦距下使用x平移来近似偏航运动的峰值信噪比(PSNR)。
4.3 相机运动空间的采样范围和分辨率 (Sampling Range and Resolution of the Camera Motion Space)
- 论文讨论了如何确定采样相机运动空间的范围和分辨率,这影响了𝐾𝑗Kj矩阵的数量。
- 作者假设采样应该足够密集,以确保离散化运动空间中的邻近体素在任何图像位置上投影的宽度不超过一个像素。
- 运动范围可以根据用户最初指定的模糊核大小估计来选择。因此,系统可以自动选择沿3个自由度的采样范围和分辨率,并预先计算𝐾𝑗Kj。
图片分析:
- 图1展示了不同焦距下,使用x平移恢复偏航运动的去模糊结果的PSNR值。图中的曲线显示了随着焦距的增加,恢复的平移开始准确近似偏航运动,这验证了在较长焦距下,相机旋转可以近似为平移的假设。
总结:
第4章主要讨论了如何形成运动响应基础(MRB),这是去模糊算法的关键组成部分。作者通过简化相机运动的自由度,减少了计算的复杂性,并通过实验验证了这种简化的有效性。此外,还讨论了如何确定相机运动空间的采样策略,以确保算法的计算可行性和去模糊效果。这些内容为后续的算法实现和优化提供了理论基础
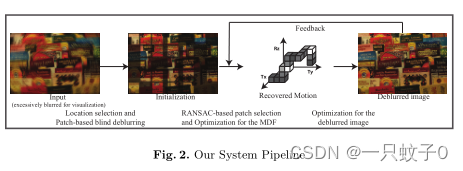
图2展示了该论文中提出的单图像去模糊系统的工作流程。下面是对这个流程图的详细解读:
-
初始化输入 (Initialization Input):
- 流程的第一步是输入一张模糊的图像,这张图像可能由于相机抖动导致模糊。
-
生成潜在图像的初始估计 (Generating an initial estimate for the latent image):
- 系统在模糊图像上均匀选择一些图像块(patches),独立地对这些图像块进行去模糊处理,以生成潜在图像的初始估计。
-
基于RANSAC的MDF优化 (RANSAC-based optimization for the MDF):
- 利用随机抽样一致性(RANSAC)算法,系统选择一组“好”的图像块,这些块在去模糊过程中表现良好。RANSAC通过迭代选择随机样本,拟合模型,并根据模型误差将样本分类为内点或外点。
-
基于位置选择和基于块的盲去模糊 (Location selection and Patch-based blind deblurring):
- 在确定了好的图像块之后,系统将对这些块进行盲去模糊处理。这是在不知道模糊核的情况下进行的去模糊尝试。
-
优化潜在图像 (Optimization for the deblurred image):
- 一旦有了运动密度函数(MDF)的估计,系统就可以解决潜在图像的优化问题。这是通过最小化能量函数来实现的,该函数考虑了模糊图像和潜在图像之间的差异以及图像的先验知识。
-
反馈 (Feedback):
- 去模糊后的潜在图像将反馈到RANSAC优化步骤,以改进MDF的估计。这个过程可能需要多次迭代,直到潜在图像收敛到一个稳定的解。
-
恢复的运动 (Recovered Motion):
- 在流程的最后,系统不仅恢复了潜在图像,还恢复了导致模糊的相机运动。这通常表示为平移(Tx, Ty)和旋转(Rz)的参数。
-
模型验证 (Model validation):
- 流程图中还展示了模型验证的结果,包括真实图像、合成相机运动、模糊图像、使用真实图像初始化的去模糊输出、使用手动选择的局部盲去模糊图像区域初始化的去模糊输出,以及使用全局空间不变去模糊系统的结果。
图2提供了一个高层次的视角,展示了系统如何通过一系列步骤从模糊图像中恢复出清晰的潜在图像,并且估计出导致模糊的相机运动。这个流程是迭代的,涉及到多个步骤的优化和反馈,以确保最终结果的准确性和质量。
第5章:我们的系统 (Our System)
第5章详细介绍了作者提出的去模糊系统的实现细节,包括算法的各个组成部分和它们是如何协同工作的。下面是对这一章节内容的解读,特别是对包含公式的部分。
5.1 生成潜在图像的初始估计
- 系统首先在模糊图像上选择一组均匀分布的图像块(patches),并对这些图像块独立进行去模糊处理,以生成潜在图像 𝐿L 的初始估计。
- 图像块的大小与系统中输入参数估计的最大模糊核大小成比例。
- 使用Harris角点度量来过滤掉那些在正交方向上梯度值平均较低的图像块,因为这些区域可能不适合进行模糊核估计。
5.2 基于RANSAC的MDF优化
- 假设潜在图像 𝐿L 已知,系统将通过最小化以下函数来求解MDF 𝐴A: 𝐸=∥∑𝑗𝑎𝑗(𝐾𝑗𝐿)−𝐵∥2+𝜆1∥𝐴∥𝛾+𝜆2∥∇𝐴∥2E=∑jaj(KjL)−B2+λ1∥A∥γ+λ2∥∇A∥2 这个函数是能量函数的简化形式,其中 𝜆1,𝜆2,𝛾λ1,λ2,γ 是实验中确定的参数。
- 优化过程使用迭代重加权最小二乘法(IRLS)进行,并且通常5次迭代就能取得良好的结果。
- 为了选择最佳的去模糊图像块,使用RANSAC算法来鲁棒地选择“好”的图像块集合,这些图像块在拟合MDF时表现良好。
- RANSAC通过随机选择初始去模糊图像块的子集,并计算每个图像块的残差误差来工作。如果残差小于所有误差中位数的1.2倍,则认为该图像块是内点。
5.3 潜在图像的优化
- 假设MDF 𝐴A 已知,系统将通过最小化以下函数来求解潜在图像 𝐿L: 𝐸=∥∑𝑗(𝑎𝑗𝐾𝑗)𝐿−𝐵∥2+𝜙(∣∂𝑥𝐿∣)+𝜙(∣∂𝑦𝐿∣)E=∑j(ajKj)L−B2+ϕ(∣∂xL∣)+ϕ(∣∂yL∣) 这个优化问题实际上是一个非盲去卷积问题,其中 𝜙ϕ 是一个正则化项,用于惩罚大的梯度,从而保持图像的自然性。
- 这个优化问题按照Shan等人在其论文中描述的方法解决。
系统流程
- 系统采用交替迭代的EM风格过程,首先对 𝐿L 进行初始化,然后交替优化 𝐴A 和 𝐿L。
- 整个过程包括:选择图像块,使用盲去卷积方法独立去模糊这些图像块,使用RANSAC选择好的图像块来优化MDF,然后使用优化后的MDF来优化潜在图像 𝐿L。
- 这个过程会迭代进行,直到恢复的潜在图像收敛。
实验设置
- 作者在一个四核双核心3.0GHz的PC上,拥有64GB RAM的环境下进行了去模糊实验。
- 对于768X512大小的图像,系统运行大约需要1小时,并且占用大约8GB的RAM。
与现有方法的比较
- 由于没有现有的自动去模糊系统可以处理一般的空间变化相机运动模糊,作者将他们的系统与Shan等人的最近盲去卷积方法进行了比较。
结果展示
- 作者展示了使用合成数据和真实世界数据的去模糊实验结果,并将新方法与现有的空间不变去卷积方法进行了比较。
结论
第5章展示了作者提出的去模糊系统的详细实现,包括初始化潜在图像的估计、使用RANSAC优化MDF以及优化潜在图像的过程。通过迭代优化和反馈,系统能够从单张模糊图像中恢复出清晰的潜在图像,并且估计出相机的运动。此外,作者还提供了实验设置和与现有方法的比较,证明了他们方法的有效性。
第6章:实验和结果 (Experiments and Results)
6.1 模型验证使用合成数据 (Model validation using synthetic data)
- 作者首先使用合成数据来验证他们提出的模型的有效性。他们使用一张清晰的图像,通过指定的6D相机运动来模糊它,然后尝试恢复3D MDF(绕z轴旋转和平移)。
- 他们展示了使用原始清晰图像作为初始化(理想情况)和使用手动选择的局部盲去模糊图像区域作为初始化的结果。
- 结果显示,如果以理想初始化开始,可以恢复非常准确的3D近似真实6D MDF。即使在系统对初始潜在图像敏感的情况下,所提出的方法也优于假设相机只进行平移运动的空间不变去模糊系统。
6.2 在真实世界数据上的结果和比较 (Results and comparisons on real-world data)
- 作者展示了使用Canon EOS-1D相机捕获的场景的真实世界模糊图像的去模糊结果。
- 他们将原始模糊图像、使用空间不变去卷积方法得到的去模糊图像和使用他们系统得到的去模糊图像进行了比较。
- 他们的系统在所有情况下都显示出比空间不变方法更显著的改进。尽管当前实现不处理场景中的深度变化,但在具有大深度变化的困难示例中,去模糊方法仍然比空间不变方法表现得更好。
实验设置和性能评估
- 实验在一个高性能的计算平台上进行,说明了系统对计算资源的需求。
- 作者提到他们的系统在处理768X512大小的图像时大约需要1小时,占用约8GB的RAM。
6.3 性能评估
- 作者评估了他们的系统在不同条件下的性能,包括处理时间和内存使用情况。
第7章:讨论和未来工作 (Discussion and Future Work)
7.1 讨论 (Discussion)
- 作者讨论了他们工作的局限性,特别是它依赖于不完美的空间不变去模糊估计进行初始化。
- 他们提出了可能的改进方向,包括使用其他模糊估计方法进行初始化,以及开发更好的度量标准来评估特定模糊核估计的准确性。
7.2 未来工作 (Future Work)
- 作者提出了未来研究的方向,包括探索其他运动响应基础。他们建议,而不是使用均匀采样的delta函数,可能更适合模拟常见相机模糊的更复杂的基础,具有更大的、更复杂的支持区域。
7.3 结论 (Conclusion)
- 作者总结了他们的工作,提出了一种统一的相机抖动模糊模型和框架,可以从单张模糊图像中恢复相机运动和潜在图像。
- 他们强调了该方法在处理由相机抖动引起的模糊方面的有效性,尤其是在模糊核空间变化显著的情况下。

通过图4的对比,可以得出以下结论:
- 正确的初始化对于去模糊算法的性能至关重要。
- 即使在非理想初始化条件下,所提出的去模糊方法也能够提供比传统方法更好的结果。
- 所提出的算法能够有效地处理由相机抖动引起的空间变化模糊,恢复出更高质量的图像。

















 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









